在制造行业,计算机辅助设计(CAD)的应用十分普遍。凭借其精确性、灵活性和高效性,CAD 已经逐渐取代了传统的纸笔绘图,并不仅限于汽车制造或航空航天等领域,生活中的几乎每一个物品,例如咖啡杯,都可能是通过 CAD 进行建模的。
在 CAD 模型中,制作高度结构化的 2D 草图是最具挑战性的任务之一,而这正是每一个 3D 设计的核心。尽管时代在变化,CAD 工程师依然需要多年的培训和经验,细致入微地关注设计的每一个细节。未来,CAD 技术将与机器学习相结合,以自动化可预测的设计任务,从而使工程师能够将更多精力集中于更宏观的设计层面,创造出更优质的作品。
最近,DeepMind 提出了一种机器学习模型,能够自动生成这种类型的草图。该模型结合了通用语言建模技术与现成的数据序列化协议,展现出足够的灵活性以适应各个领域的复杂性,并在无条件合成和图像转草图方面表现出色。
研究者们具体进行了以下工作:
首先,使用 PB(Protocol BuFFeR)设计了一种描述结构化对象的方法,并展示了其在自然 CAD 草图领域的灵活应用;
其次,借鉴了最近语言建模中去除冗余数据的理念,提出了几种有效捕捉序列化 PB 对象分布的技术;
最后,利用超过 470 万个经过精心处理的参数化 CAD 草图作为数据集,验证了生成模型的有效性。实际上,实际的实验规模在训练数据量和模型能力方面远超上述数字。
以下是 CAD 草图的展示效果:
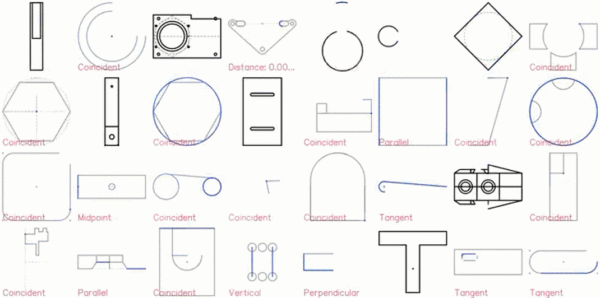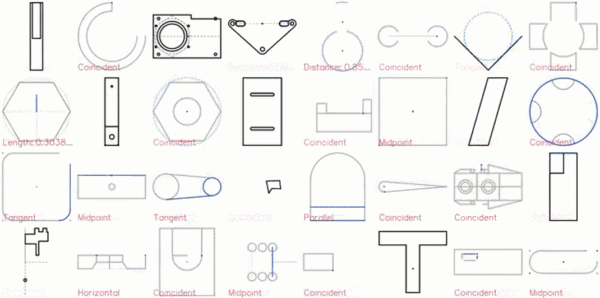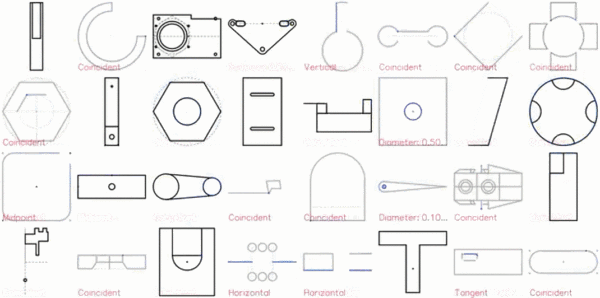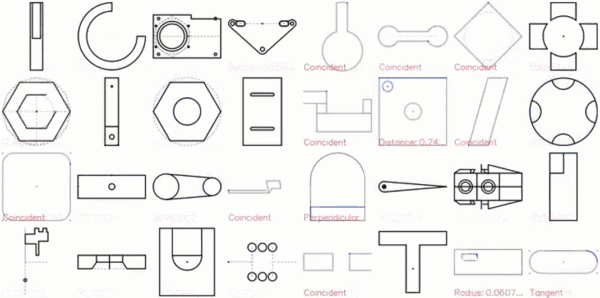
特写镜头如下:

对于 DeepMind 的这一研究,网友们给予了高度评价。用户 @TheodoRe Galanos 表示:“很棒的解决方案。我曾考虑使用 SketchGraphs 作为多模态模型的候选,但其序列的格式和长度处理起来相当棘手。期待在建筑设计中也能应用这种方法。”
草图在 CAD 中的重要性
2D 草图是机械 CAD 的基础,构成了三维形状的框架。这些草图由通过特定约束(如切线、垂直和对称)相互关联的线条、弧线、样条线和圆形组成,这些约束旨在传达设计意图,并定义在实体变换下,形状的变化方式。下图展示了约束如何将不同的几何形状组合成特定的形状。虚线显示了丢失约束时的替代解决方案。所有几何实体位于同一个草图平面上,形成封闭区域,以供后续操作(如放样和拉伸)生成复杂的 3D 形状。
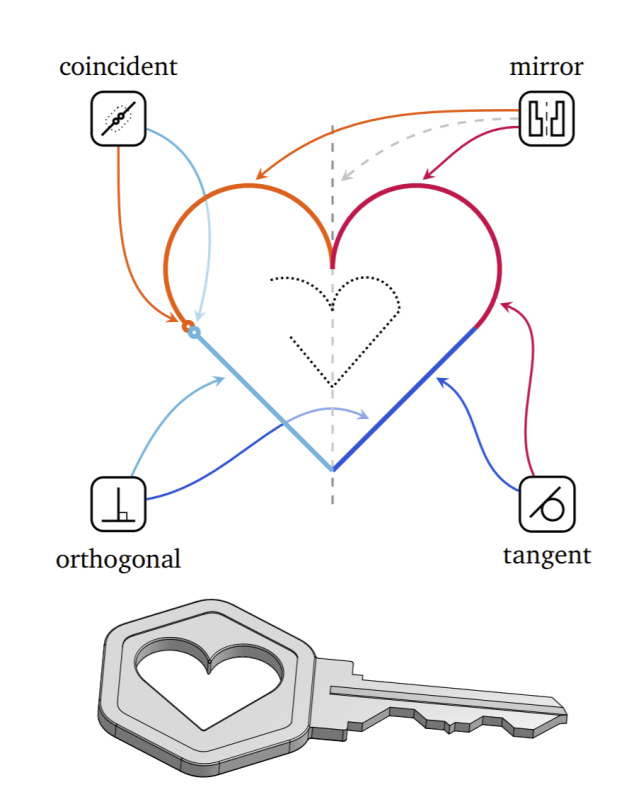
约束:草图设计中的挑战
约束(constRAInt)使得草图的复杂性远超表面。它们展示了草图中各个实体之间可能的间接关系。例如,上图中,如果在固定底角的情况下向上拖动两个圆弧的交点,心形的大小会随之增大。这种变化虽然看似简单,实则是所有约束共同作用的结果。
这些约束确保了在每个实体的尺寸和位置发生变化时,形状依然能够保持设计者所传达的状态。然而,由于实体之间复杂的相互作用,设计人员可能会无意中设置一组不合理的约束,从而导致草图失效。例如,同时满足平行和垂直条件的两条线是无法绘制的。在复杂的草图中,约束依赖关系链使得确定需要添加的约束变得极为困难。此外,对于一组特定的实体,存在多种等效的约束系统可以产生类似的草图。
高质量的草图通常会使用一组保留设计意图的约束,这意味着即便更改了实体参数(如尺寸),草图的语义依然得以保留。简而言之,无论实体尺寸如何变化,上图中的心形仍将保持心形的特征。捕捉设计意图与选择一致的约束系统之间的复杂性,使得草图生成成为一项极具挑战性的任务。
草图与自然语言建模的相似性
草图构造的复杂性与自然语言建模有些类似。在草图中选择下一个约束或实体,犹如在生成句子时选取下一个单词,而两者的选择都必须在语法上有效(在草图中形成一致的约束系统),并且保留设计意图。
在自然语言生成方面,已有多种成功的工具,其中表现最佳的无疑是基于大量现实世界数据训练的机器学习模型。例如,2017 年发布的 TRansfoRMeR 架构展示了强大的连贯造句能力。这些自然语言模型中的规律,是否可以被应用于草图绘制呢?
数据
Onshape 是一个基于维度驱动设计的参数化实体建模软件。为了存储和处理草图,研究者选择使用 PB,而非 Onshape API 提供的原始 JSON 格式。使用 PB 有双重优势:一方面移除不必要信息,缩减数据占用空间;另一方面,PB 语言可轻松定义复杂物体的精确规格。
设定好所有必要的对象类型后,数据需要转换为可供机器学习模型处理的表格格式。研究者将草图表示为 Tokens 序列,以便利用语言建模生成草图。文本格式包含了结构和数据内容,这样的优势在于可以应用任何现成的文本数据建模方法。然而,即便是对于现代语言建模技术,这样做也存在代价:模型为了生成有效的语法,将占用部分模型容量。
为了解决这一问题,研究者不再使用字节格式的 PB 通用解析器,而是基于草图格式的结构自定义构建设计解释器,即输入一系列代表草图创建过程中各决策步骤有效选择的 Tokens。在这种 Tokens 序列的格式下,设计解释器将生成有效的 PB 消息。
在这种格式中,研究者将消息表示为 tRIPlets 序列(,),其中是 Token 的索引。给定一系列这样的 tRIPlets,推断每个 Token 对应的确切字段是可行的。实际上,第一个 Token(,,)始终与 objects.kind 相关联,因为它是创建草图消息的首选。第二个字段则取决于第一个字段的具体值。如果1= 0,则第一个对象为实体,第二个 Token 对应于 entITy.kind。后续序列的其他部分也以类似方式关联。字段标识符及其在对象中的位置构成了 Token 的上下文。由于它有助于理解 tRIPlets 值的含义及整体数据结构,研究者将此信息作为机器学习模型的额外输入。

如上图所示,草图包含了一条线实体和一个点实体。在左列的每个 tRIPlet 中,实际使用的值用粗体显示。右列显示了 tRIPlet 与对象的字段之间的关联。
模型采样
建立模型的主要目标是估计数据集 D 中的 2D 草图数据的分布。正如前述,研究者将草图处理为 Token 序列。在这项工作中,考虑到原始文本格式的序列长度的挑战,主要使用字节和 tRIPlet 进行表示。
从字节模型中进行采样相对简单,与任何标准的基于 TRansfoRMeR 的语言建模过程相似,而 TRIPlet 模型则需要更多定制处理。
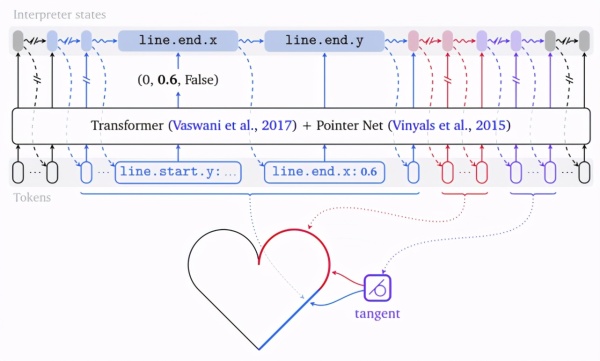
上图展示了处理 TRIPlet 的过程:首先嵌入特殊的 BOS Token,并将其输入 TRansfoRMeR。接着,TRansfoRMeR 输出一组 tRIPlets,每个可能的 Token 组一个。为了确定需要输出哪个 Token,使用自动生成的解释器(状态机)从数据规格中进行选择,再将适当的 Token 组与包含字段的 tRIPlet 活动组件相关联。填入相应字段后,解释器转换到下一个状态生成输出 Token,并将其反馈给模型。当状态机接收到最外层重复字段(即 object.kind)的 “end” tRIPlet 时,过程停止。
实验
研究者使用了从 Onshape 平台上公开可用的文档库中获得的数据来验证其方法。遵循自回归生成模型的标准评估方法,研究者采用对数可能性作为主要的定量指标。此外,研究者还提供了多种随机和特定的模型样本进行定性分析评估。
训练细节
研究者使用128个通道的批次进行模型训练,进行了10^6次权重更新。每个通道可以在 tRIPlet 设置中容纳1024个 Tokens 的序列,在字节设置中容纳1990个 Tokens。为提高占用率并减少计算浪费,研究者动态填充通道,在继续前进到下一条道之前尽可能多地打包示例。每个批次由32个 TPU 内核并行处理。
此外,研究者使用了 AdaM 优化器,设置学习率为 10^&MinUS;4,梯度范数为 1.0,所有实验均采用 0.1 的失活率。
实验结果
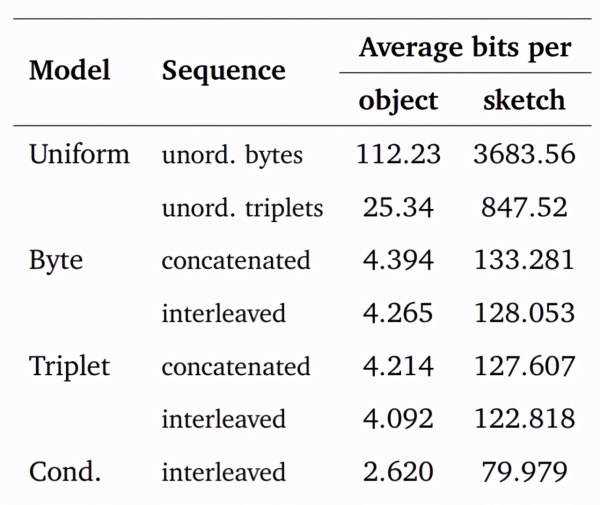
如上图所示,各种模型的可能性均得到了测试。第三列显示了草图测试样本中每个对象的平均字节数,第四列为第三列乘以对象数量的结果。
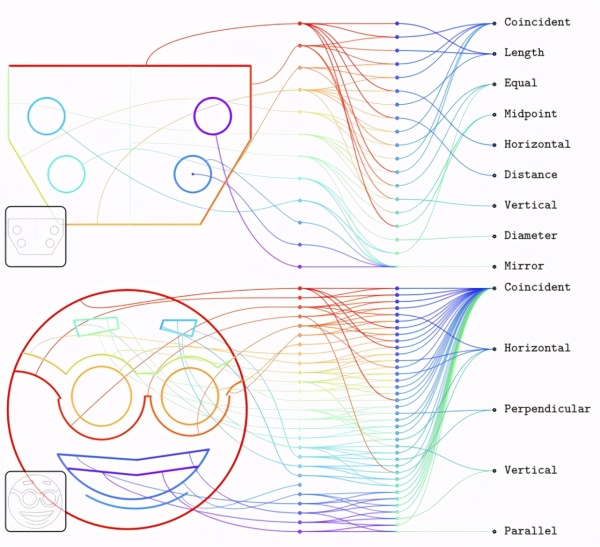
下图展示了从 tRIPlet 模型中采样的实体与约束。第一列节点表示了不同的实体,节点从上至下依生成顺序排列。第二列代表着不同的约束,按照序列索引排序。第三列则是从频率最高到最低的约束类型。

下图为条件模型的实体和约束。左下角为输入位图,例子展示了模型在分布外输入时的表现。
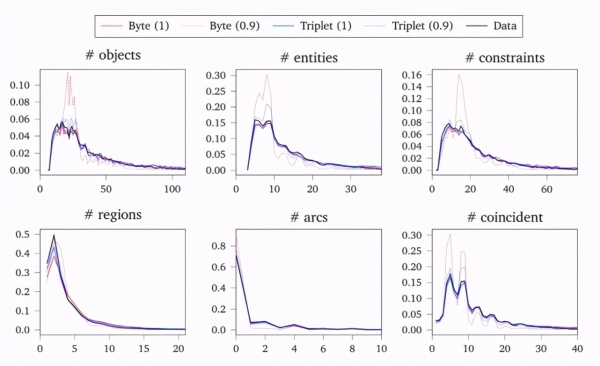
下图显示了从非条件模型采样的各种草图数据分布统计,括号中为 NUCleUS 采样的 top-p 参数。
这些实验仅为初步的概念验证。DeepMind 表示,未来希望能够看到更多应用程序开发,利用已开发接口的灵活性优势,例如根据各种草图属性推断约束,自动完成设计图纸。
