Meta AI(原FACEbook AI)近日推出了一款新型自监督语音处理模型XLS-R,支持多达128种语言的交流。

这一技术发展与Meta的“元宇宙”愿景密切相关。人与人之间的交流是自然互动的核心,随着语音技术的进步,未来的虚拟世界将使人们能够通过这一技术进行更为便捷的互动,虚拟体验也将与现实生活紧密结合。这意味着在元宇宙中,使用不同母语的人们可以无障碍地进行交流,例如一位说英语的人与一位说汉语的人,可以通过XLS-R进行顺畅对话。

那么,这项技术的实际效果如何呢?Meta AI在Hugging FACE平台上发布了试用版语音翻译模型,支持22种语言之间的转换。我们首先测试其英译中的表现。

尽管翻译略显生硬,但整体准确性依然令人满意,七秒钟的句子仅用时1.53秒完成翻译。众所周知,世界上有数千种语言,而借助AI实现这些语言间的无缝交流并不简单。一般而言,语料库的丰富程度直接影响翻译模型的质量,语音翻译通常集中在资源丰富的主要语言上。然而,小语种的语料通常较为匮乏,使用这些语言的人往往难以享受到高质量的AI翻译服务。XLS-R通过自监督技术对十倍于以往的数据进行训练,显著提升了多语言模型的表现,尤其是在小语种的处理上。
XLS-R的核心技术基于Meta去年发布的wav2vec 2.0。该技术类似于BERT,通过预测音频中被遮盖部分的语音单元进行训练。与BERT不同的是,语音音频是一个连续信号,无法简单地分割成单词或其他单位。wav2vec 2.0通过学习25毫秒长的基本单元,来解决这一问题,从而能够掌握更高级的上下文表示。
在仅有一小时标记训练数据的情况下,wav2vec 2.0能够利用后续的无监督训练数据,在LibReSpeech测试基准的100小时子集上达到当前技术的领先水平。随后,Meta推出了完全无监督的高性能语音识别模型wav2vec-U,该模型完全依赖录制的语音音频和未配对的文本进行学习。为了让wav2vec-U能够识别音频中的单词,Meta训练了一个生成对抗网络(GAN)。生成器根据自监督表示中的每个音频段,预测与语言中声音对应的音素,而鉴别器则评估这些预测的音素序列的真实性。尽管最初转录效果不佳,但随着时间的推移,鉴别器的反馈使得转录准确度逐步提高。

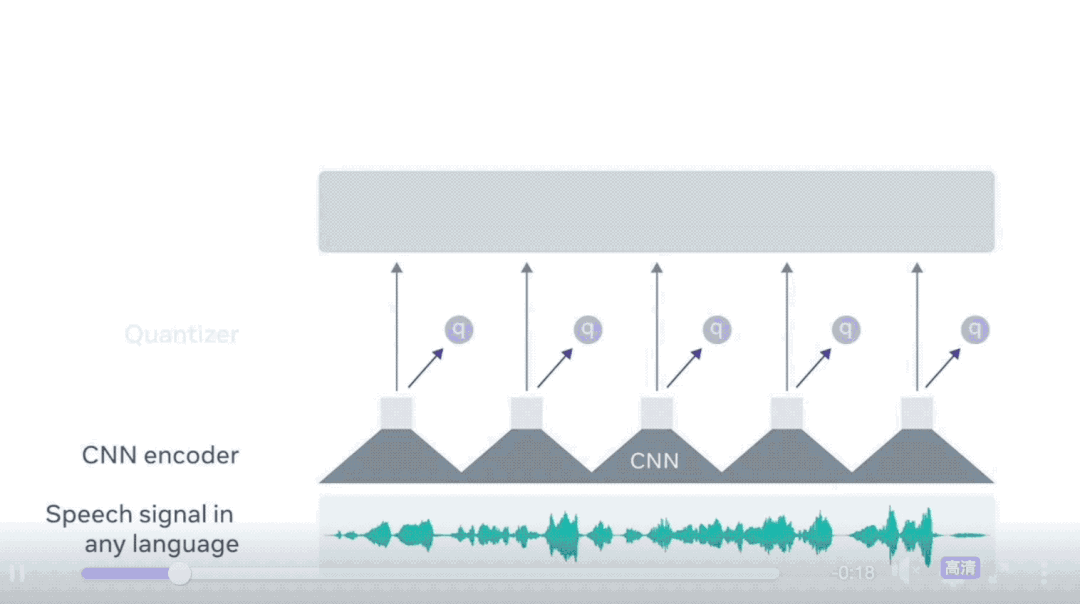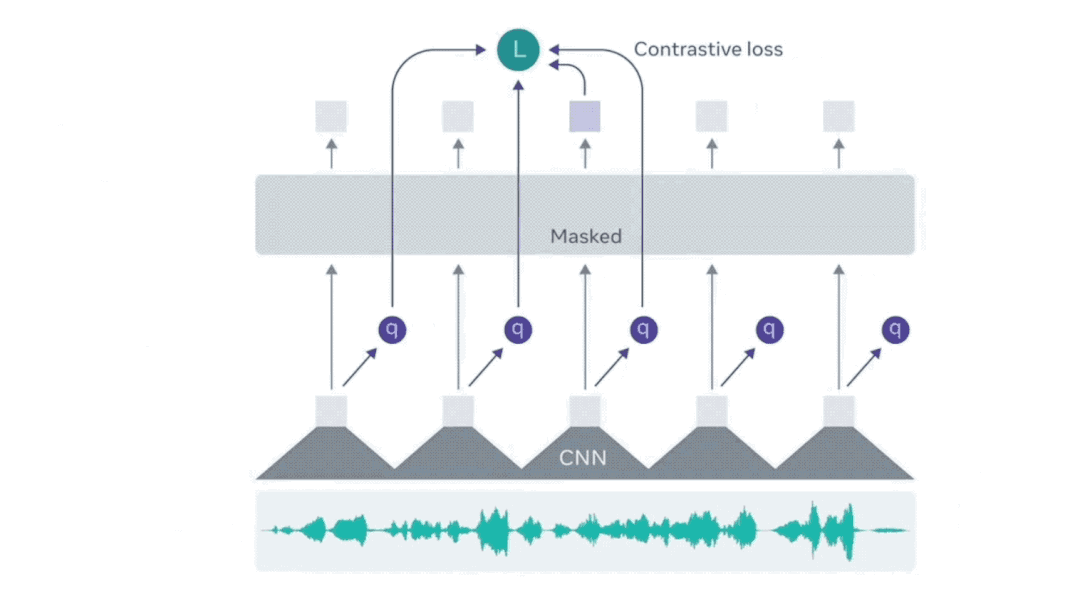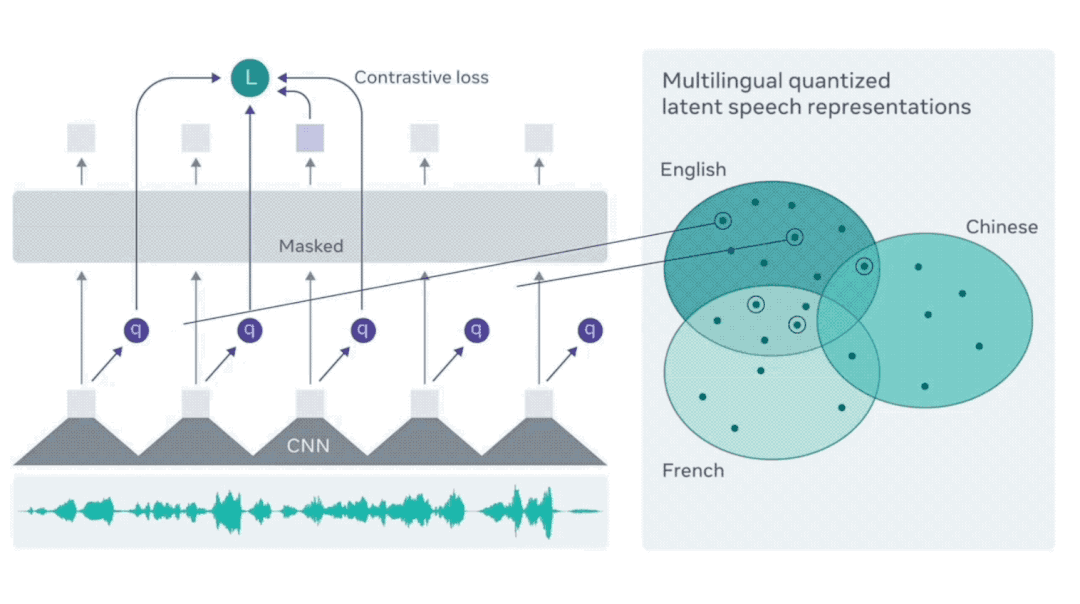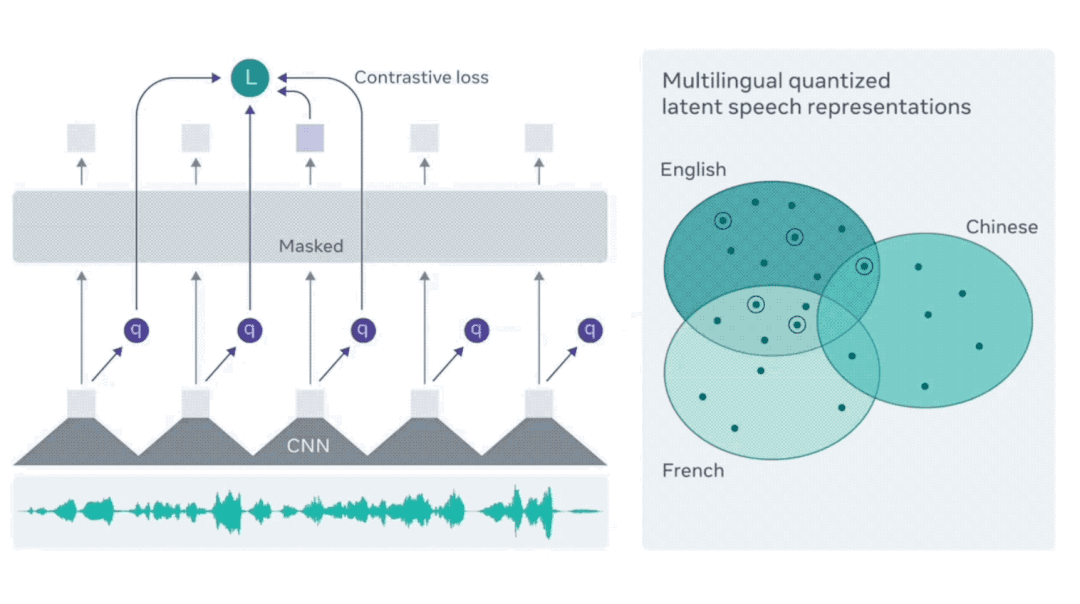
通过这种方法,模型逐渐学会区分生成器输出的语音识别结果和真实文本。在此基础上,Meta发布了包含53种语言的XLSR,而最新的XLS-R则扩展到128种语言,语种数量是XLSR的两倍,数据量更是后者的十倍,总计达43.6万小时的语音数据。
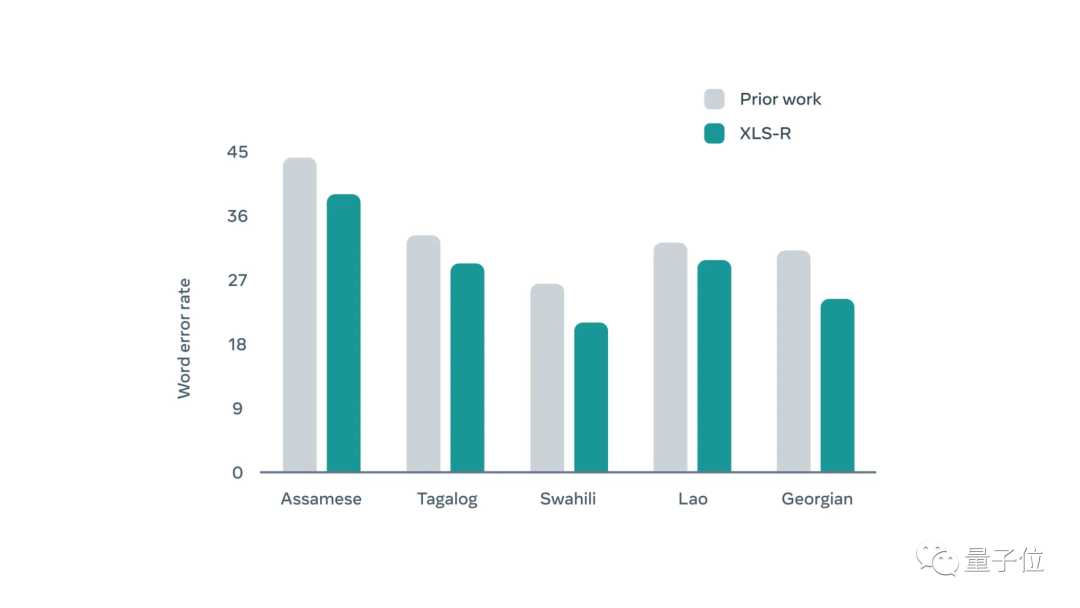
XLS-R拥有20亿个参数,在测试的37种语言中,其表现优于以往大部分语言模型,尤其是在老挝语等小语种的识别上,错误率明显降低。
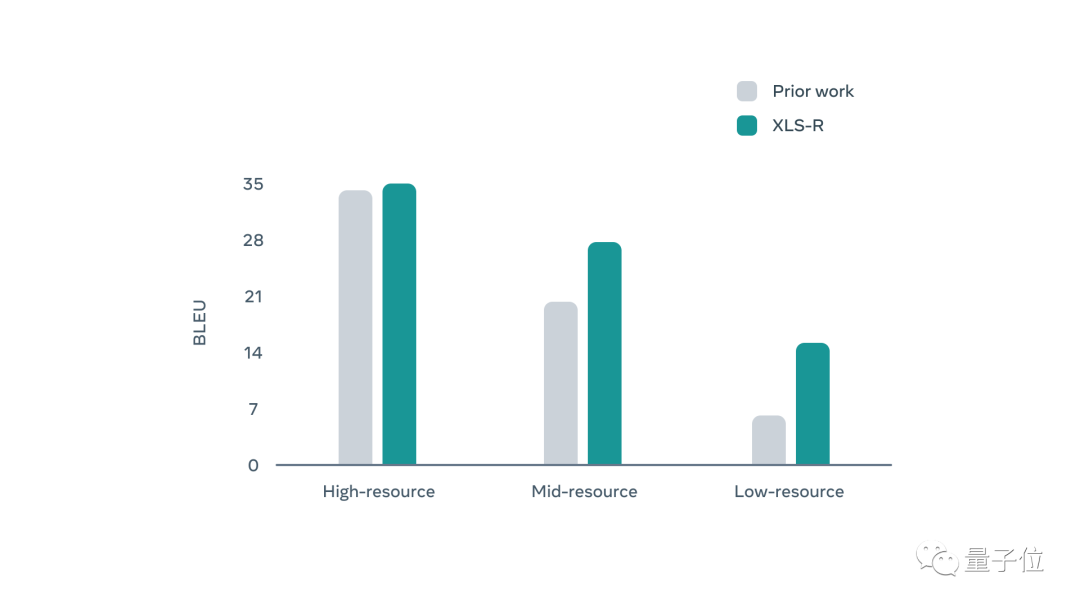
此外,XLS-R也显著提升了低资源语言与英语之间的翻译效果,例如在印尼语到英语的翻译中,BLEU分数的准确性平均翻了一倍。在COVoST-2语音翻译基准测试中,XLS-R在21个英语翻译方向上相比于之前的技术,平均提高了7.4 BLEU分数。从下图可以看出,XLS-R对低资源语言的改进尤为显著。
官方还提供了不同参数规模的语音识别模型,以及15种语言与英语之间的互译模型,供用户下载。
