在企业级数据场景中,单台服务器的存储能力通常难以承载持续增长的数据量,因此需要将数据分布到多台机器上统一管理。这类能够跨节点存储并提供统一访问方式的系统,就是分布式文件系统。
什么是 HDFS
HDFS 是 Hadoop Distributed File System 的简称,属于 Apache Hadoop 生态中的核心存储组件。它主要面向海量数据存储而设计,适合处理 TB 级甚至 PB 级的数据规模。通过将文件分散存放在多台计算机上,HDFS 能够提供统一的文件访问接口,并提升数据存储的可靠性与扩展能力。
HDFS 的设计理念来源于 Google 发布的论文《The Google File System》。
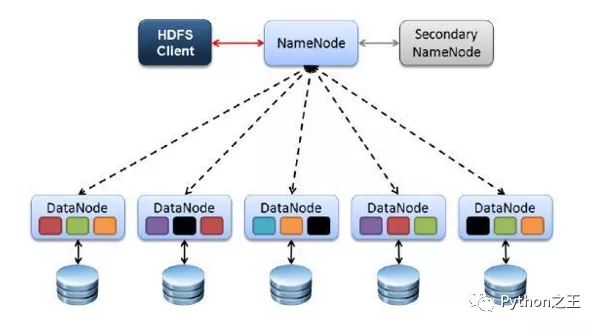
HDFS 的核心组成
HDFS 主要由四个基础组件构成:HDFS Client、NameNode、DataNode 和 Secondary NameNode。
1. HDFS Client
Client 即客户端,是用户与 HDFS 交互的入口。文件上传到 HDFS 时,客户端会先将文件切分为多个 Block,再按规则写入集群中。除此之外,客户端还负责执行常见的文件操作与管理命令,例如访问、上传、下载以及相关控制操作。
2. NameNode
NameNode 是 HDFS 的管理中心,可以理解为主控节点。它负责维护整个文件系统的元数据,包括文件名称、路径、权限、大小,以及文件被切分后的 Block 信息等。
同时,NameNode 还负责管理数据块的副本策略。默认情况下,每个 Block 会保存 3 份副本,以便在节点异常时仍能保证数据可用。客户端的读写请求也需要通过 NameNode 进行协调。
3. DataNode
DataNode 是实际存储数据的工作节点,负责保存文件的 Block 数据,并执行具体的读写操作。它会按照 NameNode 的指令完成数据块的存储、复制等任务,并定期向 NameNode 上报自身保存的 Block 信息。
4. Secondary NameNode
Secondary NameNode 并不是 NameNode 的实时热备节点,NameNode 故障后,它不能立即接管服务。
它的主要作用是辅助 NameNode 处理部分元数据相关工作,减轻 NameNode 的压力。在某些异常情况下,它也可以为 NameNode 的恢复提供帮助。
HDFS 的副本机制
HDFS 的目标是在大规模集群环境中,可靠地存储超大文件。系统会把一个文件拆分为一系列数据块,也就是 Block。除最后一个 Block 外,其余数据块通常大小一致。
为了提升容错能力,HDFS 会为每个 Block 保存多个副本。数据块大小和副本数量都可以按需配置。
在 Hadoop 2 中,文件 Block 的默认大小通常为 128MB,也就是 134217728 字节。
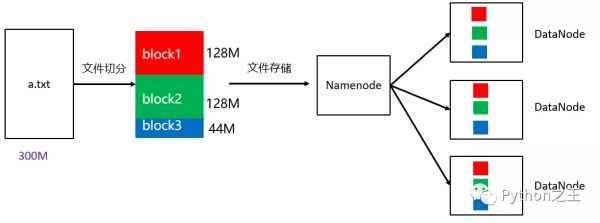
例如,一个 300MB 的 a.txt 文件上传到 HDFS 时,会按照 128MB 的规则进行切分,因此通常会被划分为 3 个 Block,最后一个 Block 的大小小于 128MB。
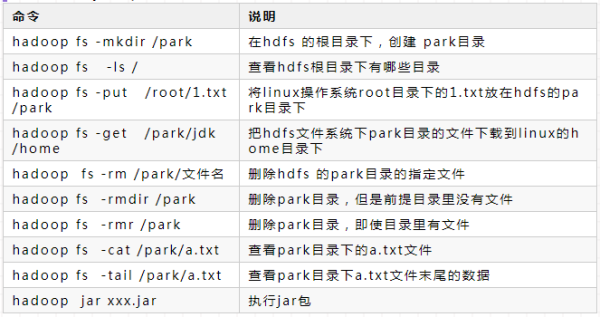
HDFS 常用命令
在日常使用中,可以通过 Hadoop 提供的命令行工具对 HDFS 执行目录创建、文件上传、查看和删除等操作。
HDFS 基础使用示例
假设当前部署的 HDFS 根路径为 hdfs://192.168.147.128:9820,下面演示一个简单的目录创建与文件上传过程。
首先,在 HDFS 根目录下创建一个名为 User 的子目录:
[hadoop@node01 ~]$ hadoop fs -mkdir /User
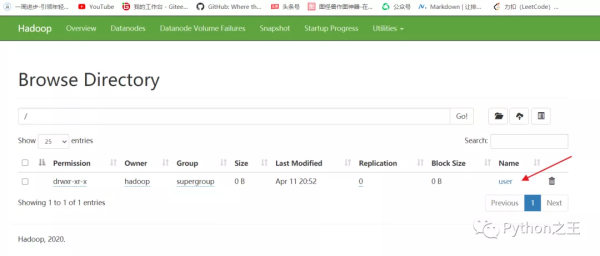
执行完成后,可以在 Hadoop 的 Web 页面中查看 HDFS 文件系统。
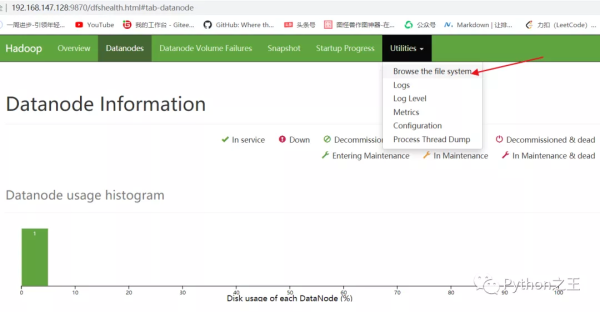
这时就能够看到刚刚创建的 User 文件夹。
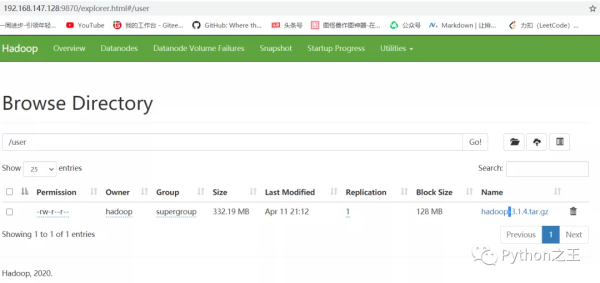
接下来,将一个大小约 300MB 的文件上传到 HDFS 的 User 目录中。

上传完成后,可以在 Hadoop 页面中看到对应文件已经出现在目标目录下。
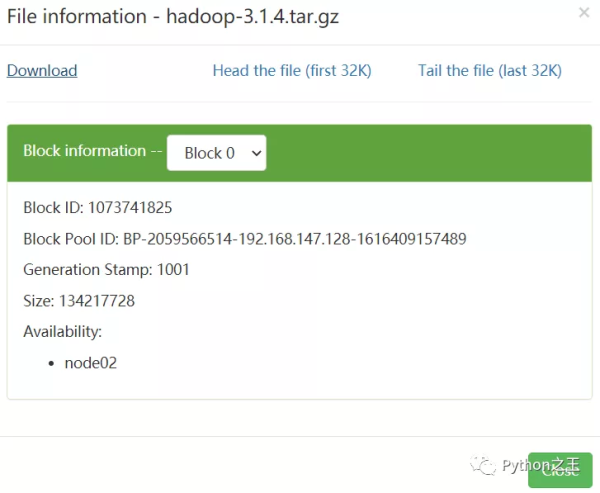
由于该文件大小超过单个 Block 的默认容量,因此系统会自动将其拆分存储为 3 个 Block。
总结
HDFS 是 Hadoop 生态中非常重要的分布式存储系统,适合存放大规模文件数据。它通过 NameNode 统一管理元数据,通过 DataNode 保存实际数据,并借助 Block 切分和副本机制实现扩展性与容错能力。对于刚开始接触大数据平台的用户来说,理解 HDFS 的结构、Block 机制以及基础命令,是后续学习 Hadoop 相关技术的重要基础。
