神经表征正逐渐成为渲染、成像、几何建模与模拟中的重要方法。相比网格、点云和体素网格等传统表示方式,这类方法更容易融入可微分、基于学习的处理流程之中。尽管近年来相关技术已经能够较好地表达中等分辨率下的图像和三维形状,但面对超大尺度或结构复杂的场景时,仍然存在明显瓶颈。
过去的神经表征方法,通常难以准确处理分辨率超过百万像素的图像,或由数十万多边形构成的复杂三维场景。
针对这一问题,研究人员提出了一种新的隐式—显式混合网络架构,以及配套的训练策略,使模型能够在训练和推理阶段根据信号的局部复杂程度,自适应地分配计算资源。这一方法被命名为 AcoRn,是一种用于神经场景表征的自适应坐标网络。
其核心思路是采用类似四叉树或八叉树的多尺度块坐标分解方式,并在训练过程中持续细化。整个网络由两个阶段组成:首先,坐标编码器利用较多参数在一次前向传播中生成网格特征;随后,每个块中的大量样本再由轻量级特征解码器高效完成评估。

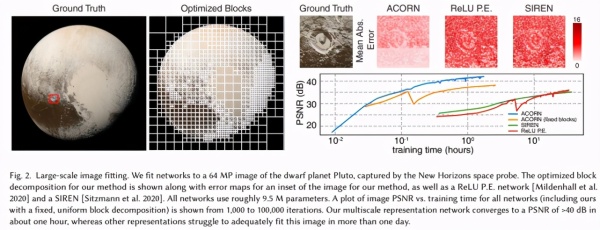
这种混合式架构带来的效果非常突出。研究显示,该方法首次将十亿像素级图像拟合到接近 40dB 的峰值信噪比。与以往图像拟合实验常见的分辨率相比,处理规模提升了 1000 倍以上。与此同时,在三维形状表征任务中,它不仅精度更高,训练速度也明显加快,可将原本需要数天的训练压缩到数小时甚至数分钟,内存需求也降低至少一个数量级。
AcoRn 在实际任务中的表现如下所示,首先是十亿像素的东京城市图像:

下面是三维浮雕的重建效果:

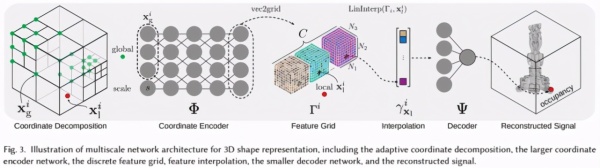
多尺度坐标网络的核心设计
这一多尺度表征网络主要包含两个部分:一是多尺度块参数化,用于依据局部信号复杂度划分输入空间;二是由坐标编码器和特征解码器构成的网络结构,用于将空间位置与尺度信息高效映射为输出结果。
多尺度块参数化
多尺度块参数化的基础,是对输入域进行树状分区。二维场景可使用四叉树,三维场景则可使用八叉树,从而确定最合适的尺度层级和最大深度。
传统的多尺度分解方法,往往会在多个尺度上同时表示同一个输入值,例如图像金字塔中的像素。而这一方法的不同之处在于,它通过空间划分,让每个输入值只在单一尺度上被表达,从而减少冗余并提升效率。
神经网络架构
该网络采用两阶段设计。第一阶段的坐标编码器负责提取局部坐标对应的特征向量;第二阶段的特征解码器则根据这些特征计算最终输出。
这一结构的关键优势在于,同一块中多个坐标点可以共享大量计算,从而显著降低评估成本。此外,特征网络还能够在不同空间位置和尺度之间复用,对于具有重复结构的信号,往往可以进一步提升整体表示能力。
在线多尺度分解
研究人员还提出了一种自动分解机制,使网络能够根据目标信号的特点动态分配资源。这个思路受到了自适应网格细化和有限元求解方法的启发:在优化过程中持续进行细化或粗化,以尽量少的计算代价获得更高的表示精度。
剪枝策略
为了避免在整片区域中重复学习相同或近似的内容,方法中还引入了剪枝机制。当某些块不再需要继续细分时,它们的值会被记录到查找表中,随后这些块将不再作为活跃部分参与后续优化,从而释放更多可用计算资源。
在实际操作中,研究发现判断一个块是否适合剪枝时,满足“误差低”和“方差低”两个条件通常就能取得较稳定的效果。
十亿像素图像表征实验
研究首先验证了 AcoRn 在超高分辨率图像中的表现。以往神经图像表征大多停留在百万像素以下,而这里直接测试了 6400 万像素和十亿像素级图像,显著突破了此前的规模限制。
实验中,研究人员选用了两张大尺度图像。其中第一张是新视野号拍摄的冥王星图像,分辨率为 8192×8192。由于这张图像同时包含不同尺度的结构特征,因此非常适合作为多尺度表征的测试对象。
结果表明,自适应资源分配策略能够让模型在细节丰富的区域采用更小的块进行表示。例如在火山口等局部区域,可以保留更多细节;而在大面积平坦、变化较少的区域,则可以用更粗尺度进行表达,以节省资源。
第二张图像是东京城市全景,分辨率达到 19,456×51,200,总体规模约十亿像素,远高于此前神经图像表征实验常见的输入大小。
在这张图像上,AcoRn 同样能够捕捉不同尺度下的细节结构,表现出良好的可扩展性。

整体来看,这一方法可以灵活扩展到超大规模二维图像,在训练速度、表征质量和实际适用范围上都带来了明显提升。
复杂三维场景表征能力
除了二维图像,这种多尺度表征方式也能够很好地推广到复杂三维场景中。
实验结果显示,与 Conv. Occ.、SIREN 等已有方法相比,AcoRn 在复杂形状表示上更准确。无论是缠绕的浮雕结构,还是紧密交错的弹簧等高复杂度对象,它都能更好地保留细节。从定量指标看,在体积表示能力和网格精度方面,该方法也优于各类对比基线。
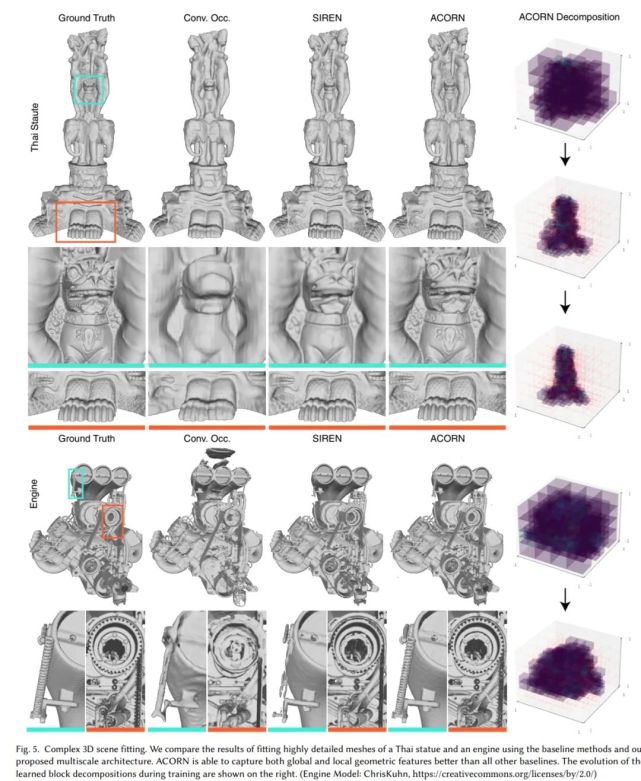
此外,AcoRn 在计算效率方面也表现突出。通过在多个采样点之间共享计算,它显著降低了训练和查询时的时间与内存开销,使神经表征在更大规模场景中的应用变得更加可行。
