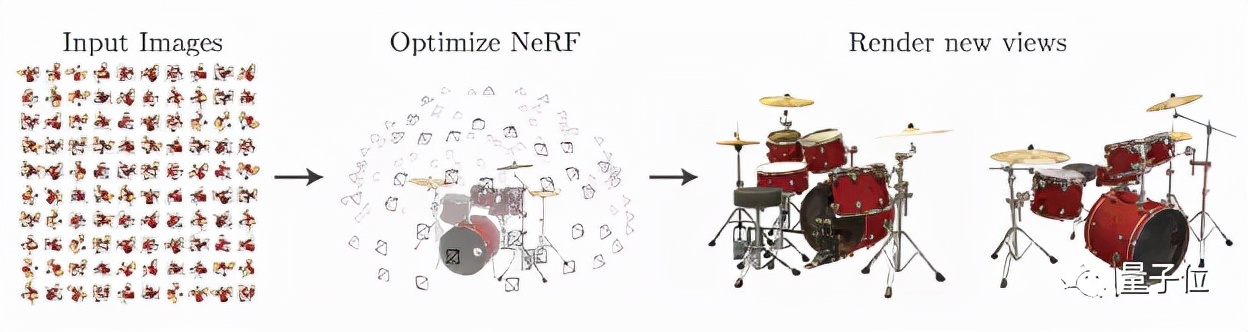
把照片变成可视化的三维效果,竟然可以不依赖复杂的神经网络,过程也能显得异常流畅。

在此之前,关于新视角合成领域的主流方法之一,是近年广泛讨论的 NeRF(神经辐射场)。
NeRF 是一个简单的全连接网络,利用二维图像信息作为训练数据,来还原具有体积感的三维场景。
近期来自某高校的研究团队提出了一个名为 PlEnoxels 的新思路。
它无需依赖神经网络,只通过梯度下降和正则化即可实现同样的效果,且速度提升达到约 100 倍!
他们究竟是如何实现的呢?
从 NeRF 到 PlEnoxels 的演化路径
为了帮助理解 PlEnoxels,我们先简要回顾 NeRF 的工作要点。

PlEnoxels 发现 NeRF 成功的核心并非神经网络本身,而是其体积渲染方程的应用方式。
那么,这个体积渲染方程到底隐藏着怎样的原理?先来一探究竟。
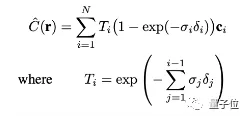
在 PlEnoxels 的框架中,颜色信息通过球谐系数来表示。每个颜色通道需要 9 个系数来描述,总共有三种颜色,因此一个体素需要 27 个球谐系数来表达其颜色。
相机光线经过的每一点颜色与不透明度,是通过最近的8个体素进行三线性插值计算得到的。
随后,和 NeRF 一样,使用体积渲染将得到的颜色与不透明度合成为三维渲染结果。
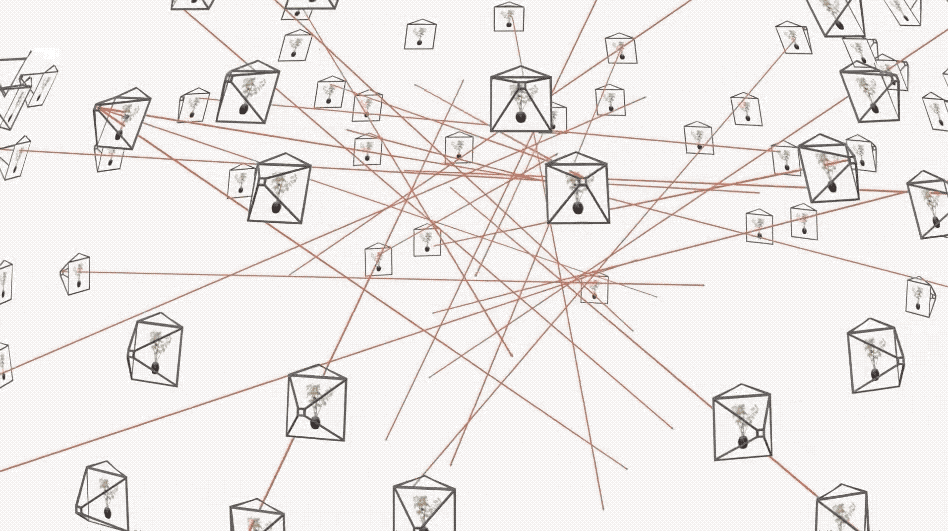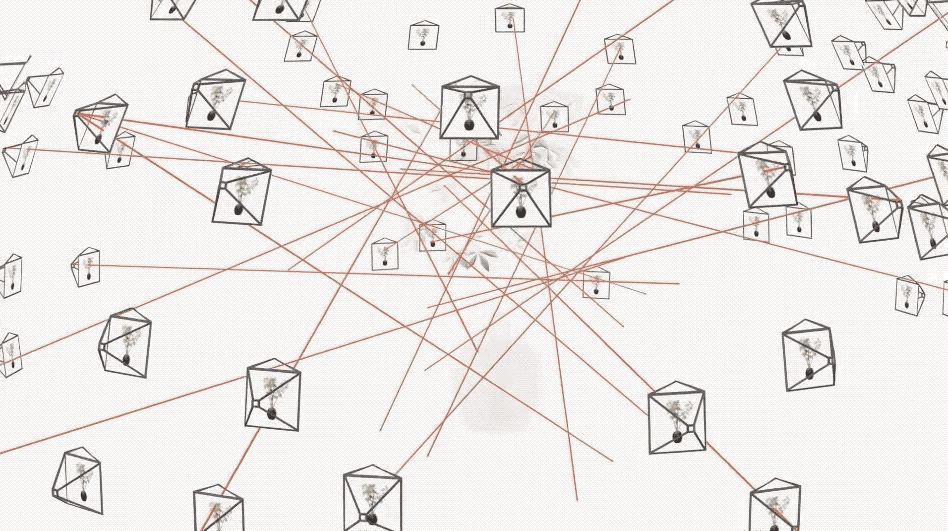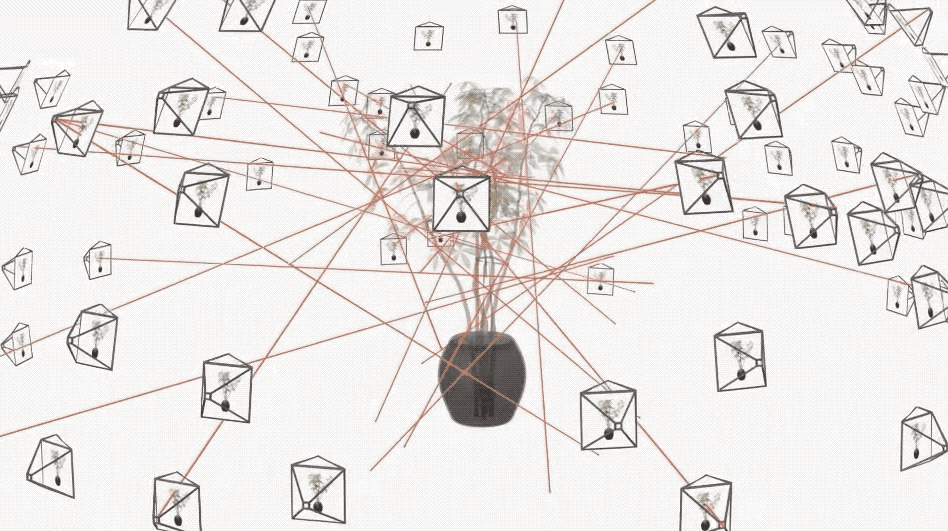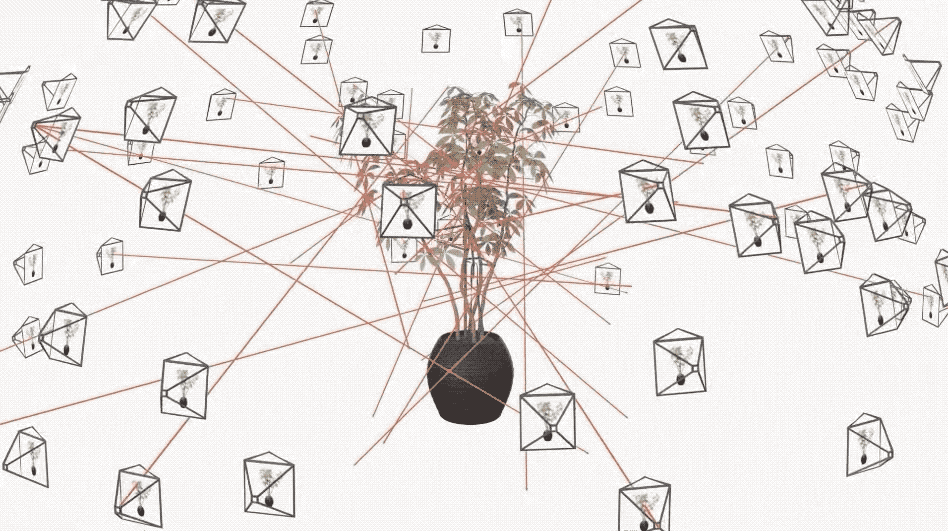

你会发现,只需几秒钟,PlEnoxels 就能得到相对清晰的效果,而同一场景的 NeRF 可能只能呈现出模糊的轮廓。
在同一个场景下,NeRF 使用单 GPU(如型号 v100)训练通常需要 1–2 天,而 PlEnoxels 只需单 GPU 大约 11 分钟即可完成。
速度 提升如此显著,自然会让人怀疑效果是否会受影响。我们用数据来回答这个问题。

PSNR(峰值信噪比):衡量图像失真程度,数值越高代表画质越好。
SSIM(结构相似性):衡量实际图像与合成图像的相似度,完整一致时等于 1。
LPIPS(学习感知图像块相似度):越低表示两者越相近。
综合对比显示,PlEnoxels 的表现并非全然领先,但在速度上的两十万级别量级提升,显著领先于同类模型。

正因其在速度上的巨大提升,PlEnoxels 让一些长期存在的应用瓶颈变得可行,例如多次反射照明(Multi-bounce lighting)和大型场景的三维建模(3D 生成模型)。
如果在相机位姿和体素哈希等环节进行进一步优化,端到端的三维重建有望落地到实际应用中。
相信 PlEnoxels 的潜力不仅于此,让我们拭目以待其实际落地的成果吧!
团队成员与背景
PlEnoxels 的强劲表现来自某校本科生团队的努力,主创 Alex Yu 也是本科在读。除了计算机相关课程,他还在校内的相关研究实验室从事三维计算机视觉方向的研究。

据悉,Alex 计划在 2022 年秋季开启 PhD 路径,未来在 AI 领域可能继续焕发新的活力。
未来若通过进一步学习和研究,他还能带来哪些创新?让我们继续关注。
开源与使用建议
目前,PlEnoxels 的代码已经在公开平台上完成开源。

写在最后:拍摄时尽量环绕物体,并尝试不同的拍摄高度,这对重建效果有帮助。快去试试吧!
