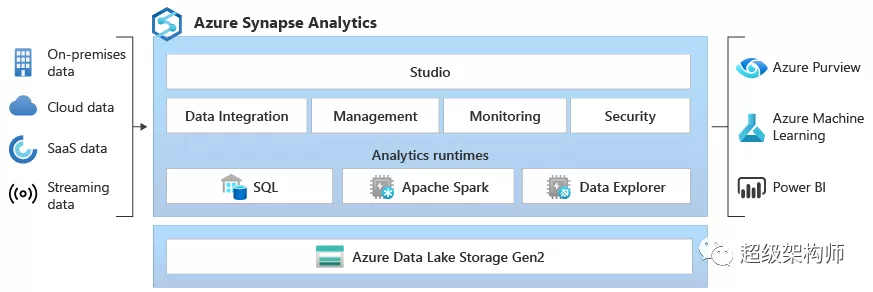
Synapse Analytics 是面向大型信息分析的服务,作为 SQL 数据仓库的演变,将业务数据存储与大数据分析结合在一起,旨在为多类工作负载提供统一的分析能力。
它能够在处理、管理和提供数据以满足即时商业智能和数据预测需求时,提供一体化的服务。通过与 Power BI 和机器学习的集成,Synapse 可以支持 ONNX 格式的机器学习模型,从而实现对海量信息的处理与查询的灵活性。
Databricks 的作用与联系
Databricks 作为基于 Apache Spark 的数据处理与分析平台,提供在交互式工作区中对共享项目的协作与扩展能力。Synapse 与 Databricks 之间可以建立高性能的连接器,以实现快速的数据传输,并在同一数据湖中对相同数据进行分析。
两者的结合可以将分析、商业智能与数据科学解决方案,与统一的数据湖进行深度整合,提升端到端的数据处理和分析能力。
主要组成与工作方式
该服务通常以云端软件即服务的形式提供,按需付费、按计算或按数据量进行计费,具有一定的成本优化潜力。核心通常包括以下要点:
- 基于 SQL 的分析能力,支持可按计算单位付费的 SQL 集群以及按处理 TB 付费的按需模式。还提供 Apache Spark 的原生集成和多数据源连接器。
- 以统一的数据模型管理、监控和元数据管理,并可通过单点登录等安全功能进行保护与合规管理。
- 对编程语言的广泛支持,包含 SQL、Python、Java、Scala、R 等,适用于不同分析工作负载和工程配置。
在数据层面,系统通常以 Data Lake Storage Gen2 为基础进行数据仓库建设,提供报告和可视化能力,形成从数据接入、清洗、到分析的完整流程。
执行引擎与工作负载隔离
系统通常支持多引擎并行处理,结合批处理、流式处理和交互式查询需求。对于大数据处理场景,可以使用 Spark 引擎进行分析,而对于结构化查询则可使用传统的 SQL 引擎。
此外,借助高效的数据传输通道和对 ETL 工作负载的优化,可以在大规模数据准备和建模环节显著提升性能与效率。
性能与优化要点
该类平台的性能要点包括对 JSON 等半结构化数据的原生支持、数据屏蔽与安全性强化、对数据工具的兼容性以及工作负载的资源分配与隔离能力。通过对不同工作负载的资源分配,可以实现对销售、市场等子工作流的优先级管理。
在数据准备与摄取方面,通常支持原生流式传输、与事件中心或物联网中心的集成,以及高吞吐、低延迟的数据加载能力,辅以基于云的并行计算架构的扩展性。
附加功能与性能提升
常见的有完善的数据加载方式、对标准 CSV 的完整支持、可控的文件选择、以及在 ONNX 格式下的机器学习模型创建与使用等。
与 Data Lake 的集成通常能带来显著的性能提升,例如对数据读取格式的优化,以及对查询执行效率的提升。
简而言之,这类服务旨在为 SQL 数据仓库客户提供持续发展的生产力,确保现有数据存储工作负载能够顺利运行并自动获得新功能的收益。