在日常工作中,海量文档需快速了解要点。手动撰写摘要往往耗时且具有挑战性,因此一项能够自动生成要点描述的功能显得尤为重要。
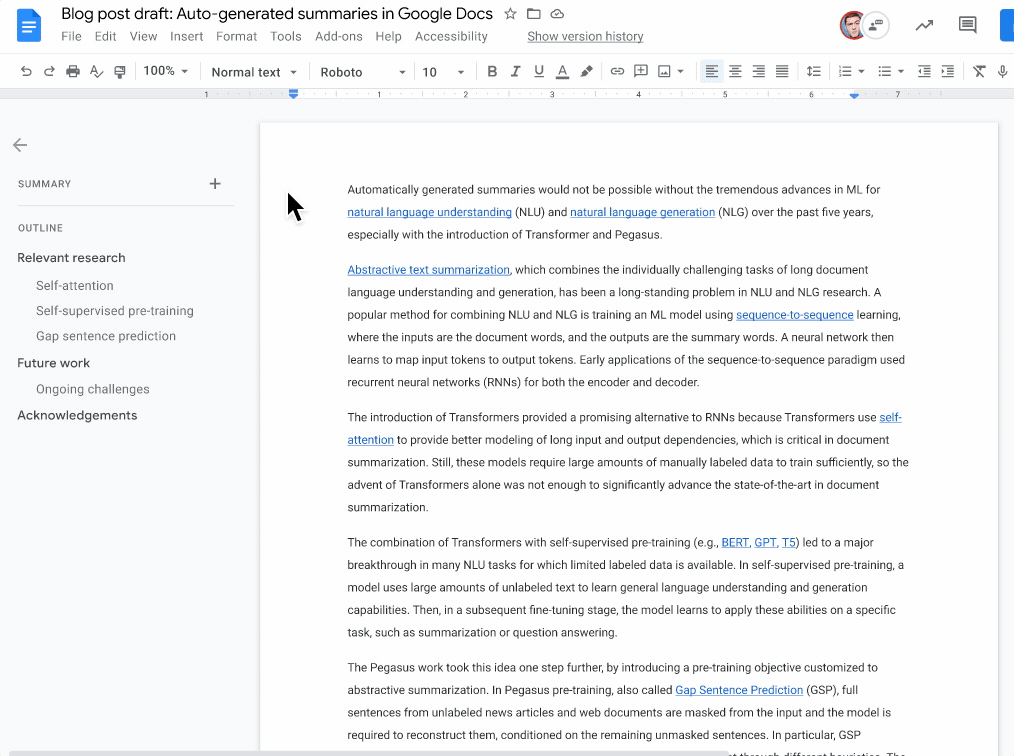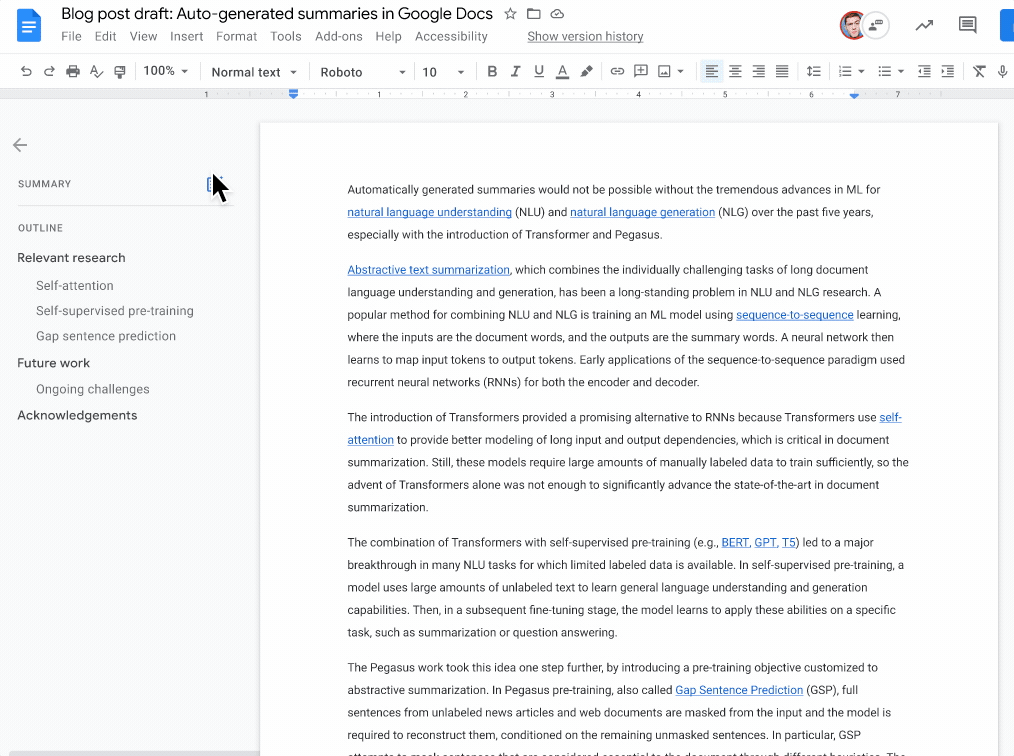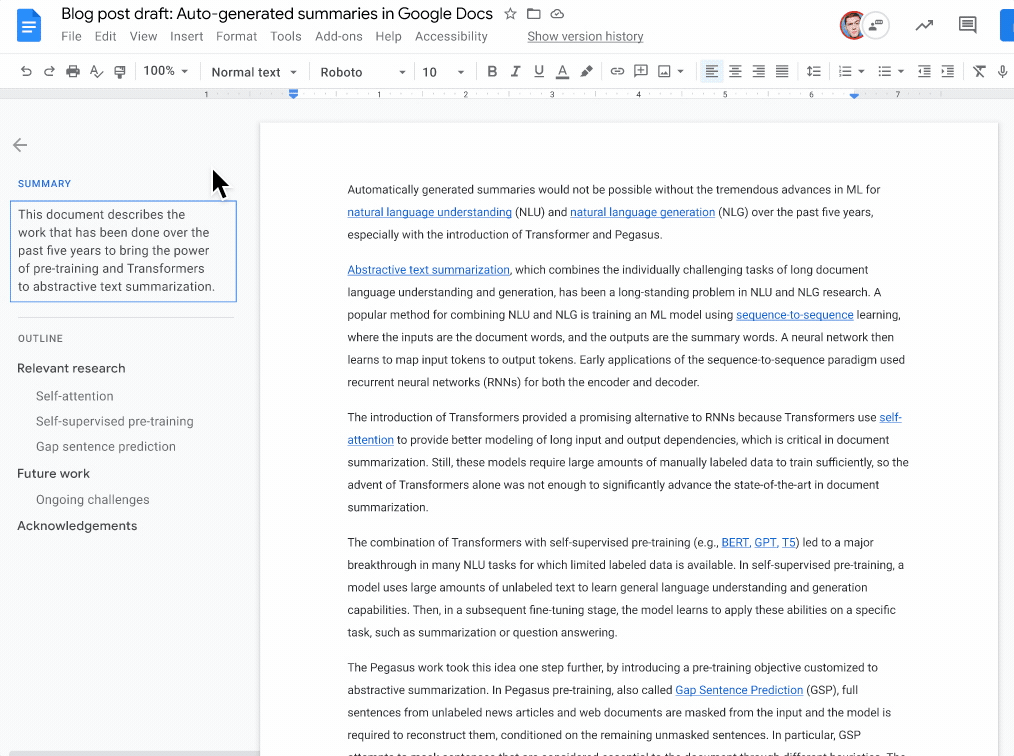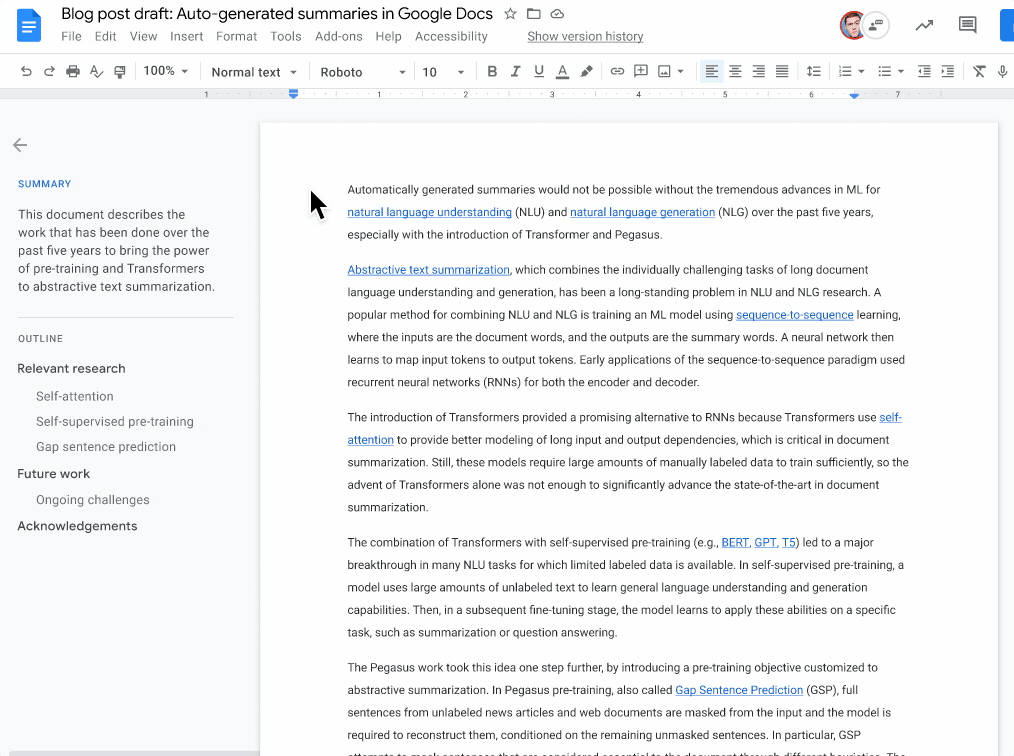
为了解决这一需求,Docs 引入了自动生成摘要建议的能力,基于机器学习模型来理解文档内容并输出1-2句的自然语言摘要。文档作者对摘要拥有完全控制权:可以完全接收、编辑后再使用,或选择忽略。
该功能还能提升对文档的层次理解与浏览体验。目前摘要建议对所有用户开放,但自动生成功能在某些版本或层级下可能需要特定权限。
使用示例:当摘要建议可用时,左上角会出现一个蓝色摘要图标。文档作者随后可以查看、编辑或忽略摘要。
模型与实现要点
近年来,文本理解与生成领域取得显著进展,Transformer 及相关模型的演进推动了自动摘要能力的发展。典型做法是将文本理解(NLU)与文本生成(NLG)结合,通过序列到序列学习训练模型,输入为文档内容,输出为摘要词序列。早期的应用常使用 RNN 作为编码器/解码器,而 Transformer 的自注意力机制为处理长文本提供了更强的建模能力,提升了对长输入与输出依赖的处理效果。
随后,一些研究通过特定的预训练目标来提升摘要质量,如在未标记文本中通过掩码重建来引导模型学习摘要相关的表达。这些方法在多数据集上展现出强大的迁移能力,推动了从通用语言理解到具体摘要任务的转化。尽管如此,将研究成果落地到实际产品仍需在数据与工程效率之间取得平衡。
在某些研究中,通过设计更高效的解码架构(如将编码器-解码器的 Transformer 与高效的解码器组合),以及对推理阶段的优化,显著提升了服务端的响应速度与资源使用,使得在生产环境中提供高质量的摘要成为现实可能。
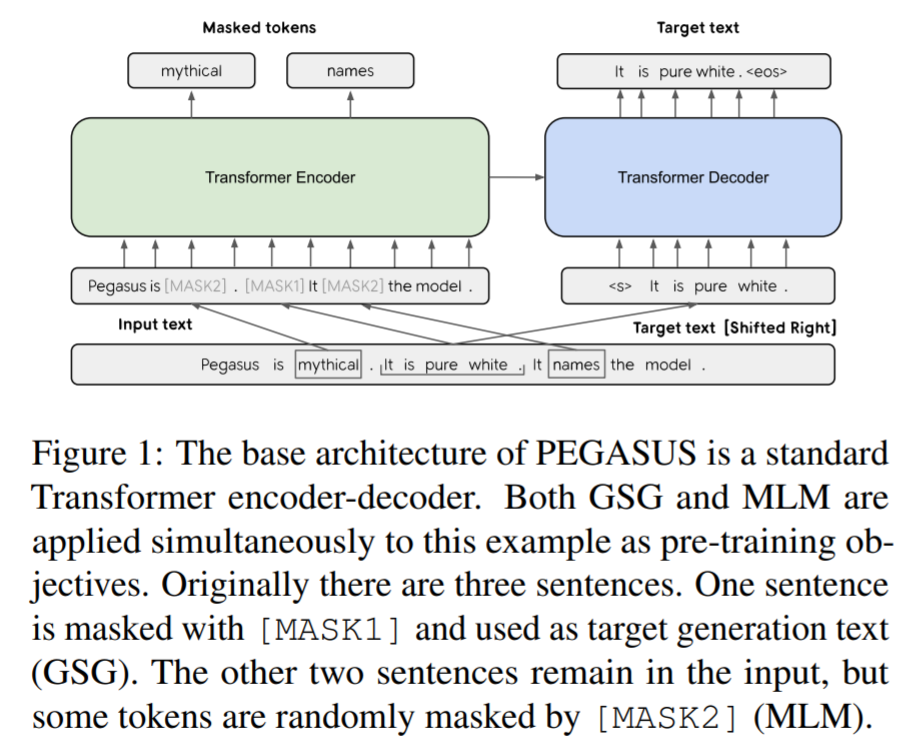
架构与生产部署要点
摘要任务的核心架构通常采用标准的编码器-解码器框架。在提升推理效率方面,混合架构(如保留编码器的稳定性,同时使用更高效的解码器)以及对解码器层数的合理调整,可以在不显著降低摘要质量的前提下减少延迟与内存占用。此外,利用专用硬件(如加速器)进行服务部署,亦可进一步提升吞吐量。
生产环境中的微调策略也十分关键。对微调数据进行清洗与对齐,能显著提升模型在现实文档上的表现;相比之下,扩大数据量并不总是带来更好的结果,高质量的小数据集往往更具价值。
持续的挑战包括:文档覆盖率的广泛性、评估的主观性与多样性,以及长文档摘要的高难度。为此,用户反馈与使用统计对不断改进模型至关重要。
此外,长文档的摘要在某些场景下可能最具帮助,但也最需要优化的资源与能力。未来的改进方向将聚焦于更高效的长文本理解与摘要生成能力。
