设想医生用简短描述指向一种用于治疗的药物,AI 就能自动给出所需分子的确切结构。虽然听起来像科幻,但跨学科的进展正让这一想法逐步接近现实。传统药物开发通常依赖人工设计与合成,走完整条链路往往耗资巨大且周期漫长。
近年,深度学习在计算机辅助药物设计中的应用受到广泛关注,相关领域通常称为化学信息学。尽管早期研究多聚焦于分子及其低阶性质,如亲水 – 油分配系数等,未来需要在分子设计中实现更高层次的控制,并结合自然语言实现直观操作。
伊利诺伊大学厄巴纳-香槟分校与相关研究团队提出两项任务来推动分子与自然语言之间的转换:一是为分子生成描述;二是在文本指导下从头生成分子。

论文地址:http://blendeR.cs.illinois.edu/papeR/Molt5.pdf
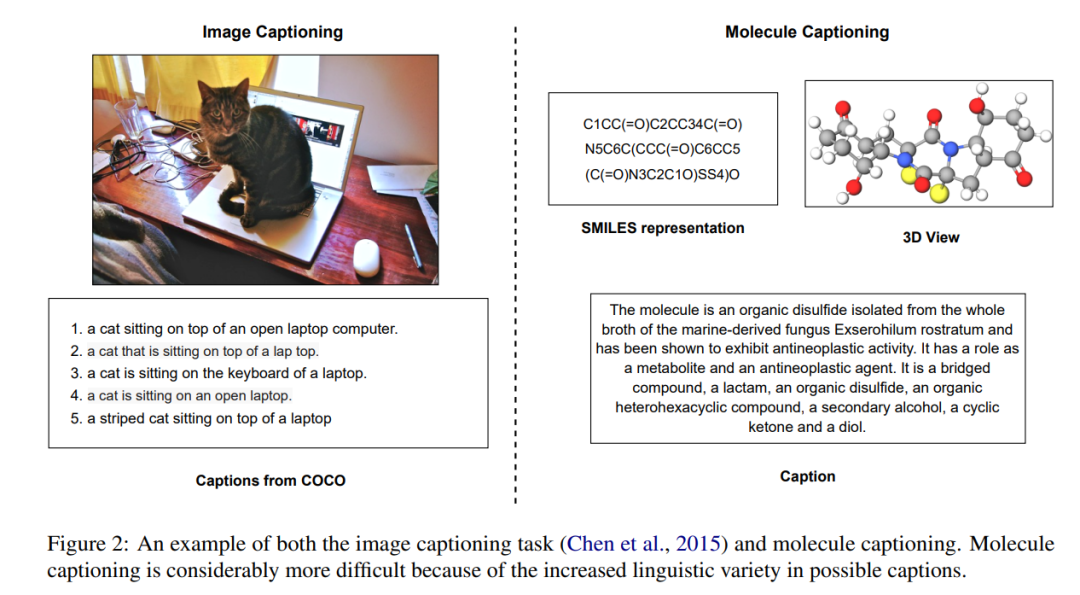
文本指导的分子生成任务旨在创建与给定自然语言描述相匹配的分子,这一能力有望加速多个科学领域的研究进展。
在多模态研究领域,自然语言处理与计算机视觉的交叉已成为热点。自然语言驱动的图像语义控制取得一定进展,推动了对多模态数据与模型的持续关注。
该研究提出的分子 – 语言任务与传统的V+L任务有相似之处,同时也面临若干挑战:1) 为分子添加高质量注释需要大量专业知识;2) 数据稀缺导致难以获得广泛的分子–描述对;3) 同一分子可具备多种功能,需要多样描述;4) 现有评估指标如 BLEU 无法充分覆盖此类任务的评估需求。
为缓解数据匮乏,该研究提出了一种自监督学习框架 MolT5,灵感来自最新的跨语言预训练模型进展。
此外,为全面评估分子描述与生成能力,该研究提出了一个名为 Text2Mol 的新评估指标。
研究者们从互联网上抓取大量自然语言文本作为训练数据来源。比如 RaFFel 等(2019)构建了一个包含超过 700GB 的自然英语文本的数据集;另一方面,公共数据库如 ZINC-15 提供了超过十亿个分子相关数据。受大规模预训练进展的启发,该研究将自监督学习框架 MolT5 与海量未标记文本和分子字符串结合起来,以提升模型的泛化能力。
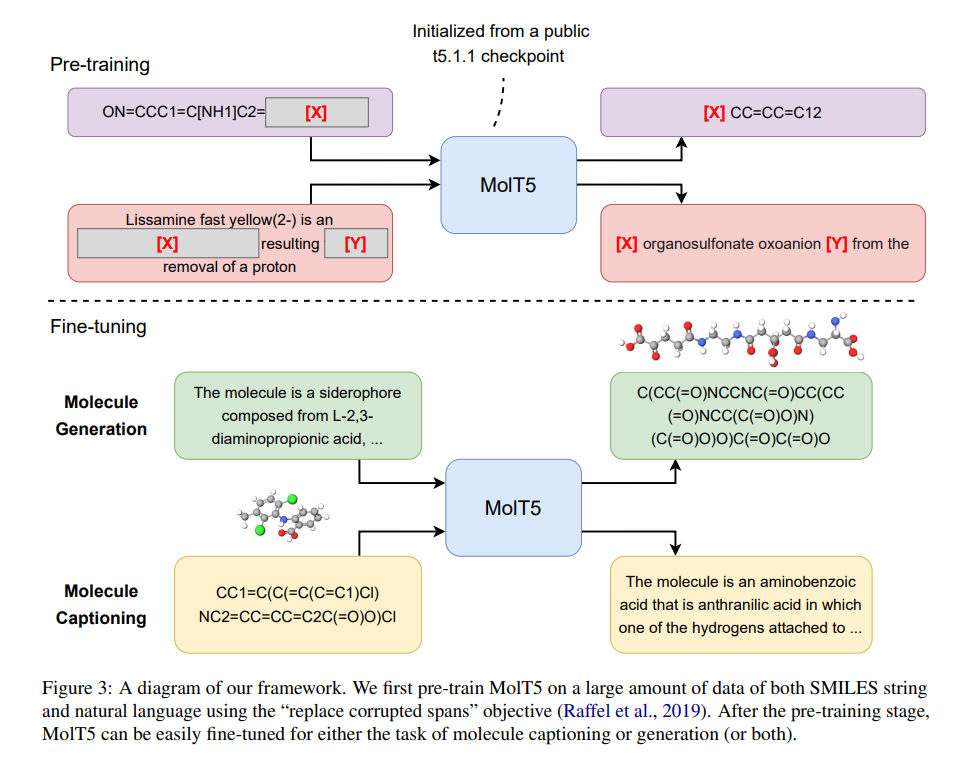
分子通常以 SMILES 字符串表示,具有独特的语法结构。可以理解为本研究的预训练阶段在两种不同的语言语料库上训练一个语言模型,二者之间并无显式对齐,这与 MBERT 和 MBART 等跨语言模型的思路类似。由于这些模型在跨语言任务中表现突出,研究者希望 MolT5 的预训练模型也能在文本–分子翻译等任务上发挥作用。
完成预训练后,模型可进一步微调用于分子描述或分子生成任务。
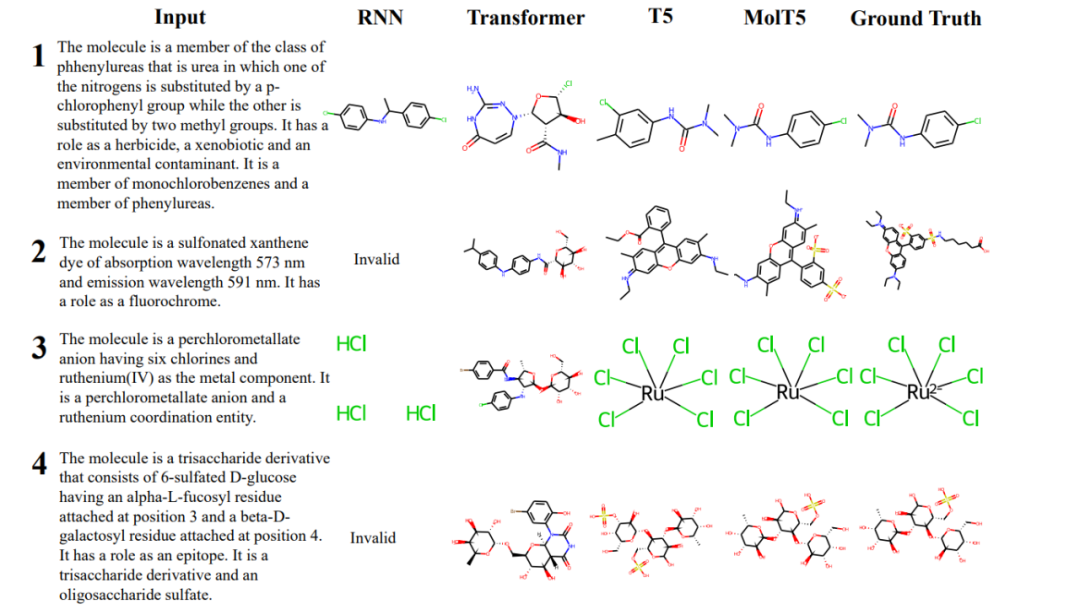
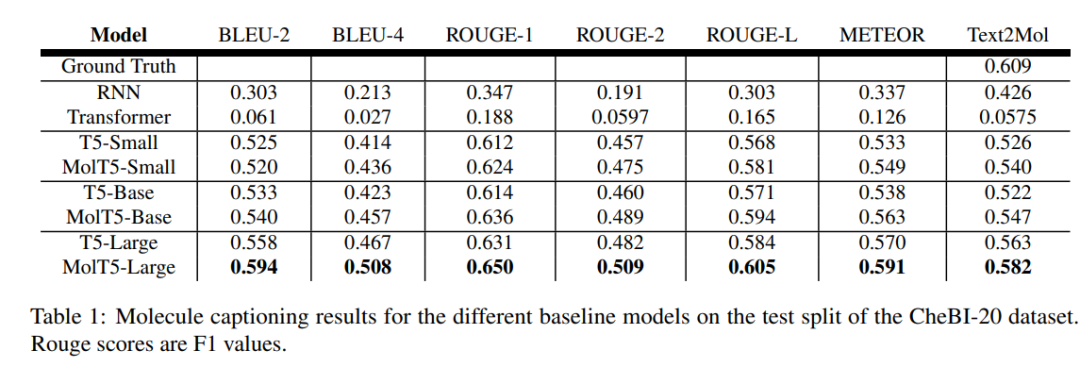
下文简表显示分子描述任务的测试结果。研究发现,在生成贴近真实描述的语言时,较大的预训练模型如 MolT5 相较于传统的 Transformer 或 RNN 展现出显著优势。
下图展示了若干模型输出的示例。

一般而言,RNN 在分子生成方面优于 Transformer,但在分子描述任务中,较大规模的预训练模型往往表现更好。扩展模型规模和训练数据通常带来性能提升,但该研究的结果仍然令人惊喜。
例如,默认的 T5 模型只在文本数据上预训练,便能生成更接近真实分子结构的描述,并保持一定有效性。随着语言模型规模的扩大,较大参数的模型往往进一步提升性能。MolT5 的预训练虽未完全超过最优的大型模型,但在某些分子生成指标上仍有显著改进,尤其在有效性方面表现突出。
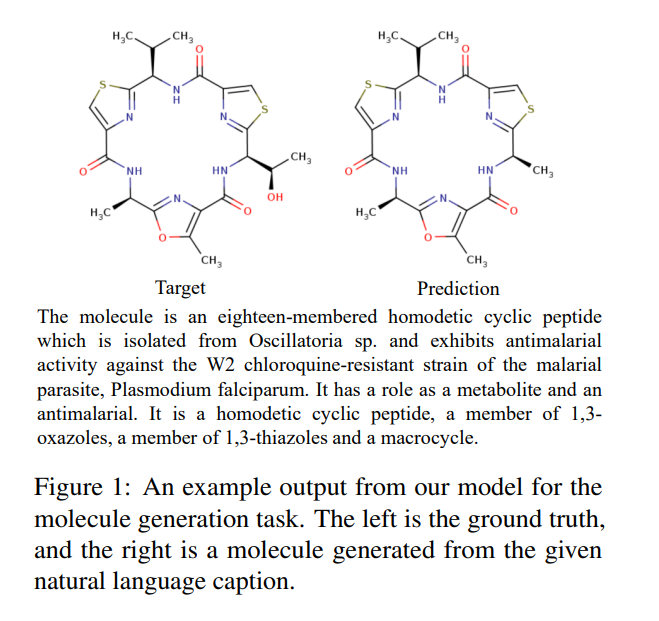
下图4展示了模型的结果,按输入描述对输出进行编号。研究发现,相比于 T5,MolT5 更擅长理解分子操作指令。