超大数据规模与模型效果的关系再思考
当前人工智能领域的一个显著趋势是扩大数据集规模,但最近的研究质疑,单纯追求超大规模数据整理可能并不一定促进有效的智能系统开发。
数据规模真的越大越好吗?
算力与数据一直被视为推动AI发展的两大核心驱动力。无论是计算机视觉还是自然语言处理,数据集的作用都不容忽视。
在超大规模数据时代,数据量与学习结果之间的关系似乎呈现出一种直观的相关性:数据越多,模型越精准。但是,这种正相关真的是普遍成立的吗?
[ ]
]
最近发表的一篇论文对这一广泛观点提出了质疑,呼吁重新审视数据规模与模型表现之间的关系。
[ ]
]
规模越大,未必就越好?研究对“饱和”现象进行了探讨。
论文题为 Exp l o ring the liMITs of pRe-tRAIning Model,挑战了“通过扩大数据规模或调整上游超参数来提升下游任务性能”的常见假设。实验结果显示,在某些情况下,上游性能的提升并不一定带来下游任务的对应提升,甚至可能出现下游性能的饱和。
所谓饱和,简单理解就是没有充分的梯度信号传递给网络,导致权重更新变得困难,学习过程受限。
[ ]
]
文中还描述了一种极端情形:提高上游任务的性能并不必然带来更好的下游效果,甚至可能需要在某些情况下牺牲上游的精确度以提升下游表现。
这一观点若成立,将意味着像 LAION-400M(包含数亿对文本/图像对)等超大数据集,以及以往规模较大的语言模型所依赖的数据,可能受限于传统机器学习架构与方法。巨量数据未必总是提升下游任务的泛化能力。
当然,这并非完全否定既有直觉,只是需要在一个更清晰的前提下考察:数据规模与超参数并非简单的一条直线关系,而是在一定条件下呈现复杂的非线性模式。
数据资源与计算成本的现实制约,使得早期的研究范围往往局限于较小的规模,这也在某种程度上导致对数据-AI系统关系的理解不够全面。
因此,结论不可一概而论,需在更广泛的范围内进行验证。
同时,文章也指出以往对数据规模有效性的论证,往往是在有限范围内进行的,不能据此妄下定论。
[ ]
]
上下游关系并非简单线性
早期研究在一个线性假设下,呈现出对数型关系的趋势。[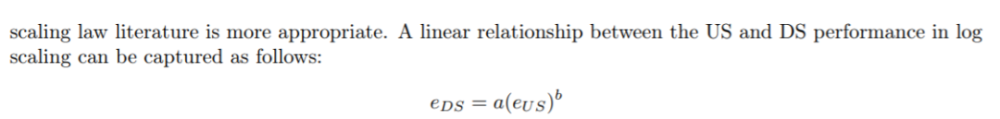 ]
]
但进一步的研究显示,情况更为复杂:下游任务在某些阶段会出现饱和点,而这些点并非固定存在,因此上下游之间的关系呈现非线性特征。[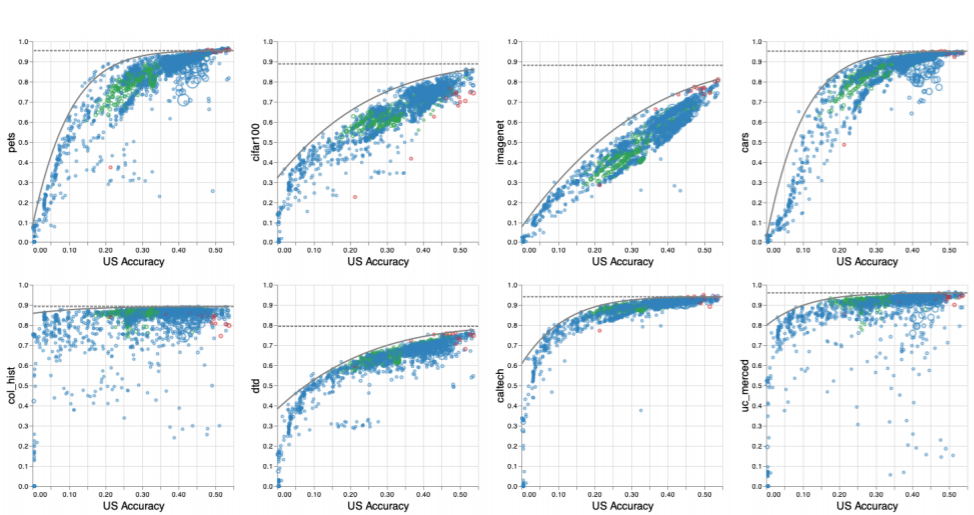 ]
]
尽管扩大数据规模和模型容量可以提升上游的性能,但由于非线性关系的存在,同步提升上游并不必然提高下游的准确性。
因此,预训练模型并非一劳永逸的万能解决方案。
本文还讨论了“预训练”这一做法:尽管在减少从零开始训练所需时间方面具有优势,若考虑到特征的复杂性,预训练并不一定适用于所有场景。若继续普遍依赖预训练模型,可能对最终结果的准确性产生影响。
论文最后总结称:“不能指望找到适用于所有下游任务的通用预训练模型。”
[ ]
]
规模与准确度真的一一对应吗?
研究对这一“规模越大越准”的说法提出质疑,揭示了潜在的复杂关系。是否会因此推动AI研究产生新的突破,仍有待观察,或许会引发更多相关研究与讨论。我们拭目以待。