如何进行人工智能开发?
市场对「定制开发AI模型」的需求已高达86%。
然而,在这一过程中,企业用户与开发者常常面临以下挑战:
缺乏模型训练经验、数据采集和标注成本较高、模型适配与部署流程繁琐、模型优化迭代周期长。
那么,是否存在一个工具能够「一站式解决」这些问题呢?
答案是:百度EasyDL。
简单来说,EasyDL大幅降低了深度学习的应用门槛:
使AI开发的过程变得如同使用「家用电器」一般简单,而训练出来的AI模型质量则与高级工程师所产出的一样专业。
实际上,百度早在2017年底推出了EasyDL,并在2018年初正式开放,同时提出了一个愿景——EveRyone can AI。
那么,经过近三年的发展,这一愿景进展如何呢?
像家电一样的AI,究竟可靠性如何?
首先,让我们来看看EasyDL的三大特点:
极简的交互和使用流程,模型训练最快可在15分钟内完成;高精度的训练效果,例如图像分类模型的线上平均准确率超过99%;多样的部署方式,全面支持云端、设备端及边缘计算的部署。
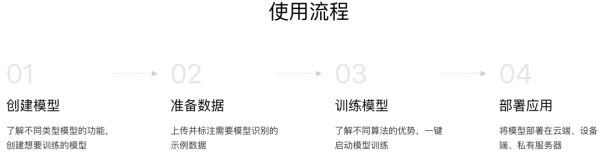
EasyDL的易用性和低门槛是其一大亮点。
整个使用流程仅需四个简单步骤:创建模型、准备数据、训练模型和部署应用。
整个过程均为可视化图形操作,显著降低了企业与开发者的使用难度。
正如百度AI平台研发部技术总监忻舟所说:
无需编写一行代码,便可根据需求和数据定制自己的AI解决方案。
例如,在工业制造的质量检测领域,以「爱包花饰」为例,在监控箱包生产过程中残留异物(如针和金属部件)时,通过EasyDL训练的质检模型达到了90%的准确率,且无需了解AI算法的具体细节。
再以「瀚才猎头」为例,几位人力资源专家在未了解AI算法的情况下,利用EasyDL完成了简历数据的结构化处理和自动分类,大幅提高了简历检索的效率。
虽然EasyDL强调简便,但并未牺牲专业性。两者之间是「兼容且并行」的关系。
继续以「瀚才猎头」为例,该机构储备了200万条不同行业的企业与人才信息。
但一个严重的问题是:由于简历检索效率低下,人才库的利用率不足10%。
使用EasyDL训练多个模型推进简历数据的结构化处理后,两个模型的识别率达到了95%以上。
在关键词搜索任务中,瀚才猎头以往每天只能找到60-70份合适的简历,而现在仅需20分钟即可找到600-1000份,且精准度高达95%。
总而言之,百度EasyDL不仅使企业在「定制AI模型」的使用上变得简单如家用电器,而且在专业性上丝毫不逊色于高级AI工程师。
此外,EasyDL还支持公有云API、私有服务器部署、设备端SDK及软硬一体方案等多种模型部署方式。
在软硬一体方案上,EasyDL提供了6种方案,支持专项适配与加速,覆盖高中低全矩阵,模型识别速度可提升10倍。
不仅种类丰富,集成速度也极快——最快仅需5分钟。
EasyDL的这些优异特性,源于其深厚的技术实力。
EasyDL是如何实现这一切的?
表面上看似简单的工具和平台,其背后往往蕴藏着复杂的设计。
百度EasyDL亦是如此。
平台内部集成了众多复杂的深度学习算法和工程技术,旨在确保其使用的简单、易用和低门槛。
EasyDL高精度模型的另一个关键因素是其基于百度自主研发的深度学习平台飞桨。该平台整合了百度长期积累的独特技术与工程能力,为用户提供一站式模型训练和服务体验。
首先,EasyDL预置了百度超大规模数据训练的预训练模型。
在视觉任务中,图像分类训练任务内置了基于海量互联网数据的超大规模视觉预训练模型,涵盖10万+分类和6500万张图片,平均精度提升达3.24%-7.73%。
在物体检测训练任务中,内置的超大规模物体检测预训练模型基于800+标签、170万张图片和1000万+检测框,平均精度提升1.78%-4.53%。
在自然语言处理领域,EasyDL提供了业界效果最佳的预训练模型文心(ERNIE),将机器语义理解能力提升到新高度。
同时,EasyDL还提供自动数据增强、自动超参数搜索等AutoML/DL自动化建模机制,降低了对无算法基础用户的使用门槛。
利用飞桨DGC加速机制,EasyDL通过仅传输重要梯度(稀疏更新)来减少通信带宽,提升了分布式训练效率,相比传统方式速度提升超过70%。
在数据处理方面,EasyDL建设了EasyData智能数据服务平台。
在数据标注与清洗上,EasyData提供了11种数据标注模板和5种标准及高级清洗方案。
EasyData还提供软硬一体、端云协同的自动数据采集方案,简化数据采集中的设备选型、调试与集成开发工作。
最后,在部署方案上,EasyDL提供了公有云API、设备端SDK、本地服务器和软硬一体部署四种选择。
公有云API支持弹性扩展,设备端SDK则提供了端模型适配服务,支持15+芯片类型及4大常用操作系统。
这些都是EasyDL强大能力背后的技术支持。
为什么选择EasyDL?
因为市场需求促成了这一选择。
人工智能引领的第四次工业革命正在各行各业不断深入,大企业通常具有一定的人才储备与技术积累。
相比之下,中小企业在智能转型过程中往往面临重重困难,智能化门槛过高,包括高级开发人员成本和技术能力等问题。
然而,中小企业在国民经济发展中却扮演着至关重要的角色。
因此,解决这些问题成为了一种「刚需」。
正因如此,EasyDL自开放以来便获得了中小企业的广泛认可与支持。
在过去两年多的时间里,EasyDL不断升级与改进,提升整体产品体验与功能。
这也是EasyDL在众多AUTODL平台中,能够脱颖而出的原因,带来更好的效果。
不仅如此,EasyDL的更新迭代仍在继续。
例如,今年的升级亮点之一是五月全新发布的EasyData智能数据服务平台。
该平台专注于AI开发场景,提供一站式的数据采集、数据清洗、数据标注与数据回流解决方案。
内置的超大规模预训练模型也是今年技术亮点之一,提升了训练效果的精度。
在刚刚过去的9月,EasyDL进行了大规模升级。
在EasyDL经典版NLP方向新增定制情感倾向分析、文本分类多标签和文本实体抽取;全新推出表格数据预测分析的ML方向,进一步丰富模型类型。
在数据服务方面,EasyDL在已有的智能标注基础上推出了多人标注,极大提升了数据标注的效率。
全新上线的模型市场还支持个人或企业将EasyDL经典版训练好的模型发布进行销售,并首次创新性地支持将已购买的模型与数据进行再训练,以实现更优的模型效果。
未来,EasyDL将继续发力:
不仅扩展现有的CV、NLP、ML、语音识别等算法类型,还将推出OCR、视频追踪等定制化能力,持续提升模型效果、加快训练速度与模型推理。
在数据、模型与服务等方面,EasyDL将不断降低使用门槛。
因此,可以说,百度EasyDL离最初的「EveRyone can AI」的愿景又近了一步。