选择优秀机器学习算法的七个关键因素
在机器学习领域,任何问题都可以采用多种算法和模型进行解决。例如,在垃圾邮件检测的分类任务中,可以运用朴素贝叶斯、逻辑回归以及诸如BILSTM等深度学习技术。
虽然拥有丰富的选择是有益的,但决定在实际应用中使用哪个模型却是一个挑战。尽管我们可以利用多种性能指标来评估模型,然而针对每个问题实现所有算法并不切实际,这将消耗大量时间和精力。因此,了解如何为特定任务选择合适的算法至关重要。
本文将探讨影响算法选择的关键因素,帮助你找到最适合你项目和商业需求的解决方案。理解这些因素有助于明确模型将执行的任务及其复杂性。
可解释性
可解释性是指算法对其预测结果的解释能力。缺乏这种解释能力的算法通常被称为黑箱算法。
例如,k-最近邻算法(KNN)通过特征重要性展现出较强的可解释性,而线性模型则通过特征权重的分配实现可解释性。考虑到机器学习模型的最终应用,了解算法的可解释性显得尤为重要。
在诸如癌细胞检测或评估房屋贷款信用风险等分类任务中,理解系统结果背后的逻辑至关重要。仅有预测结果是不够的,我们需要能够评估其合理性。即便预测准确,我们也需理解导致这些预测的过程。如果任务要求理解结果背后的原因,那么选择合适的算法就显得尤为必要。
数据点的数量与特征
在挑选合适的机器学习算法时,数据点的数量和特征起着关键作用。不同用例下,机器学习模型会与各种不同特征和数量的数据集进行交互。在某些情况下,选择模型时需考虑如何处理不同规模的数据集。
例如,神经网络擅长处理大量数据和特征,而某些算法如支持向量机则只能应对有限特征的情况。因此,在选择算法时,务必要考虑数据的规模和特征的数量。
数据格式
数据通常来源于开源和自定义数据源的结合,因此可能呈现不同的格式。最常见的数据格式包括分类和数值数据。任何数据集可能仅包含分类数据、数值数据,或两者的结合。
由于算法只能处理数值数据,如果你的数据格式为分类或非数值,则需要考虑将其转换为数值数据的过程。
线性数据
在选择模型之前,了解数据的线性特征至关重要。这一特征有助于确定决策边界或回归线的形状,从而指导我们选择合适的模型。例如,身高与体重之间的关系可以用线性函数描述,意味着当一个数值增加时,另一个通常也会相应增加,这种关系适合用线性模型建模。
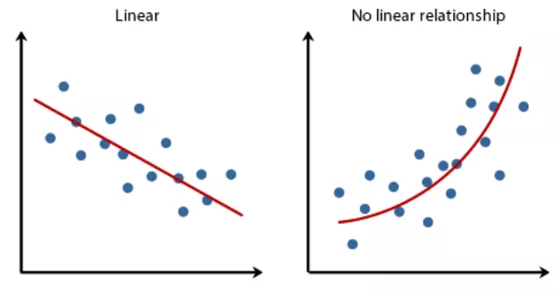
通过散点图理解数据的线性度
掌握这一点将帮助你选择合适的机器学习算法。如果数据几乎是线性可分的,或者可以用线性模型表达,支持向量机、线性回归或逻辑回归等算法都是不错的选择。此外,还可以考虑使用深度神经网络或集成模型。
训练时间
训练时间是指算法学习和构建模型所需的时间。在某些用例中,例如特定用户的电影推荐,每次用户登录时都需要对数据进行训练;而在库存预测等场景中,模型需要实时训练。因此,评估模型的训练时间至关重要。
众所周知,神经网络通常需要大量时间来训练模型,而传统的机器学习算法,如KNN和逻辑回归所需时间则要少得多。一些算法如随机森林的训练时间也因所用CPU内核的不同而有所差异。
预测时间
预测时间是指模型进行预测所需的时间。对于像搜索引擎或在线零售商店这样的互联网公司,快速的预测时间对于用户体验至关重要。在这种情况下,速度是关键,即便算法结果良好,如果预测速度太慢也将无济于事。
然而,在某些业务需求中,准确性可能比预测速度更为重要。例如在癌细胞检测或欺诈交易识别的场景中,支持向量机、线性回归、逻辑回归和某些类型的神经网络能够实现快速预测,而KNN和集成模型通常需要更长的预测时间。
存储需求
如果整个数据集能够加载到服务器或计算机的内存中,则可以选择多种算法。然而,当无法做到这一点时,可能需要采用增量学习算法。
增量学习是一种机器学习方法,通过不断输入新数据来扩展已有模型的知识,进而训练模型。其目的是适应新数据的同时保留已有知识,因此无需对模型进行重新训练。
在选择适合机器学习任务的算法时,性能看似是最显而易见的评估标准。然而,仅凭性能无法决定最佳算法,模型还需满足其他标准,如内存需求、训练和预测时间、可解释性及数据格式。通过综合考虑这些因素,你可以做出更为自信的决策。如果在多个候选模型中难以选择最佳算法,可以通过验证数据集进行测试。
在决定实现某个机器学习模型时,选择合适的模型意味着深入分析你的需求与预期结果。尽管这可能需要额外的时间和努力,但最终将带来更高的准确性和更优的性能。