应对海量数据和并发的图数据库研发实践
一、图状结构的广泛应用
当前,字节跳动的所有产品几乎都能归类为三种主要的数据类型:用户信息,这包括用户之间的关系(如关注、好友等);内容数据,涉及视频、文章和广告等;以及用户与内容之间的交互关系(如点赞、评论和转发等)。这些数据通过图状(Graph)结构相互关联,形成了丰富的关系网络。
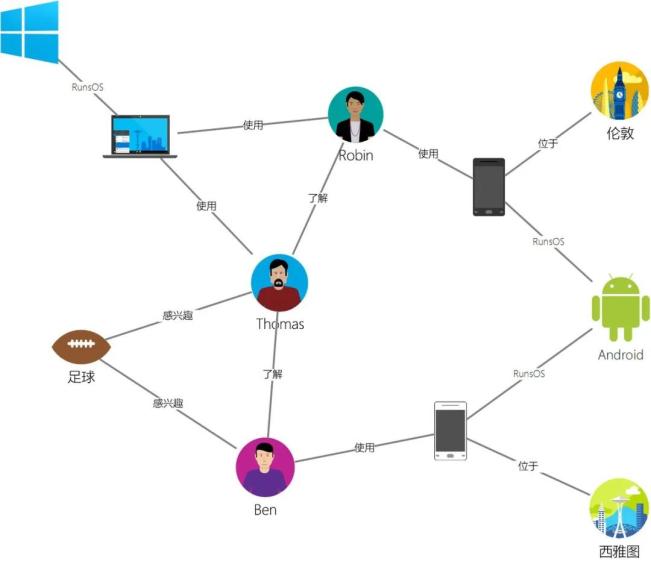
为了满足社交图形的在线增删改查需求,字节跳动开发了分布式图数据库系统 ByteGraph。该系统支持有向属性图数据模型,兼容 Gremlin 查询语言,具备丰富的读写接口,读写吞吐量可扩展至千万 QPS,延迟控制在毫秒级。目前,ByteGraph 已为字节跳动的多个产品线提供支持,包括今日头条、抖音、TikTok等,覆盖全球多个数据中心。
在本文中,我们将深入探讨 ByteGraph 的应用场景、内部架构和关键问题的分析。
ByteGraph 主要用于在线 OLTP 场景,但在离线场景下,图数据的分析和计算需求逐渐突显。2019 年初,Gartner 在数据与分析峰会上将图数据库列为未来的重要趋势之一,预计全球图分析应用将以每年 100% 的速度增长,至 2020 年将达到 80 亿美元。因此,我们团队也开启了对离线图计算场景的支持和实践。
接下来的部分将重点介绍字节跳动在图数据库和计算方面的实践。
二、自研图数据库(ByteGraph)介绍
从数据模型的角度看,字节跳动的图数据库是有向属性图,基本元素包括图中的节点(Vertex)、边(Edge)及其附加的属性。作为工具,图数据库对外提供的接口主要围绕这些基本元素展开。
图数据库的本质也是一个存储系统,区别于常见的 KV 存储系统或 MySQL 数据库在于其目标数据的逻辑关系形式不同。对于本质上数据的内在关系,图模型及其查询方式与传统的查询模式截然不同,能够更高效地处理复杂的关系查询。
以下是 ByteGraph 的关键特点:
1、为什么不选择开源图数据库
图数据库在 90 年代初首次出现,随着大数据爆炸的趋势,近年来得到了快速发展,市场上各类图数据库层出不穷。但目前大多数成熟的图数据库都面临性能瓶颈,尤其是在高并发场景下,传统的图数据库难以满足字节跳动的需求。因此,我们选择自研图数据库 ByteGraph,以满足在全球范围内高并发、高可用和低延迟的需求。
下文将介绍 ByteGraph 的数据模型和 API 设计,以及分布式架构的实现。
1)数据模型
ByteGraph 的数据模型主要基于图的节点和边。节点(Vertex)是图的基本组成部分,通常反映的是静态信息,而边(Edge)则表示节点之间的关系。ByteGraph 中的节点包含唯一标识符、类型和属性等信息,而边则由两个节点以及描述它们之间关系的属性组成。
2)边的方向
在 ByteGraph 的数据模型中,边是有方向的,目前支持三种边的类型:正向边、反向边和双向边。正向边如 A 关注 B(A -> B),反向边则是 B 被 A 关注(B <-> A)。
3)图计算
图计算主要是基于图的节点和边进行的计算,分为两种主要模型:同步计算和异步计算。同步计算指的是所有节点在每轮迭代中都要等待其他节点的计算结果,而异步计算则允许每个节点独立进行计算,不必等待其他节点的结果。半同步计算则是对两者的综合,允许一定程度的并行计算,灵活应对复杂场景。
图计算的实现需要高效的算法支持,例如 PageRank 和社区检测等算法。通过对图的特性加以利用,字节跳动的图计算可以在大规模数据上进行高效的分析和处理。
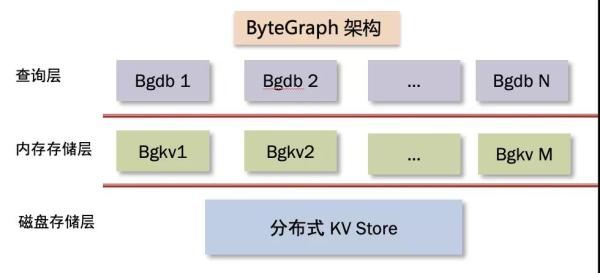
4)分布式架构
ByteGraph 的分布式架构使得其能够在高并发场景下提供稳定的性能。分布式的设计使得系统能够横向扩展,合理分配负载,避免单点故障带来的风险。该架构包括多个服务节点,支持对数据的高效存储与计算。
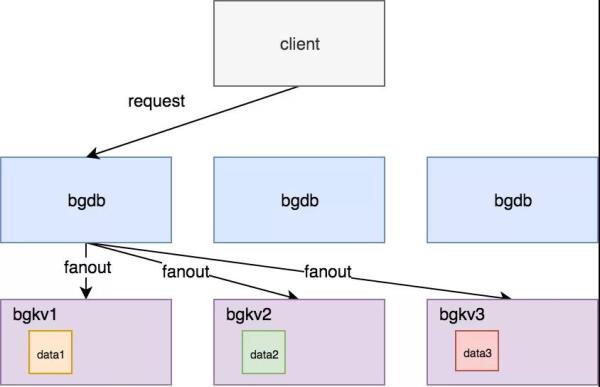
5)图存储格式的优化
在图的存储中,ByteGraph 采用了优化的存储格式,以提高数据的读写效率。数据存储的设计不仅考虑了如何高效存储图数据,还注重对图数据访问模式的优化,比如通过合理的缓存策略来提高访问性能。
6)未来展望
面对日益增长的业务需求和技术挑战,字节跳动将持续对 ByteGraph 进行优化与迭代,探索更高效的图计算和存储方案。希望通过不断的技术创新,为用户提供更好的产品体验。
三、总结
字节跳动在图数据库和计算领域的探索和实践,不仅解决了大量的实际问题,还为未来的发展奠定了基础。随着业务的不断扩展,ByteGraph 将继续发挥其核心技术优势,推动图技术的广泛应用。