在AI时代,生存与发展的关键是什么?
无疑是数据。
尤其是对中小企业和正在转型的传统企业而言,寻找和管理优质数据已成为一种迫切需求,这就像在互联网开发时代对代码共享与管理的需求一样。
因此,若有一个专为AI时代打造的数据共享平台,是否能有效满足这一需求呢?
事实上,确实有创业团队在朝这个方向努力。
其中,陆奇这一知名人士也对此表示看好。
该团队是一家专注于AI数据托管和协作的SaaS公司,创始团队由经验丰富的一线工程师组成,他们深刻理解当前市场的痛点。
一方面,AI数据准备和工程任务所占的时间,已超过大多数AI项目的80%。在AI训练过程中,若缺乏高质量的训练和测试数据集,构建出高效的AI模型将变得异常困难。
因此,提供高质量且适应场景的真实数据,成为AI产业链中至关重要的需求。
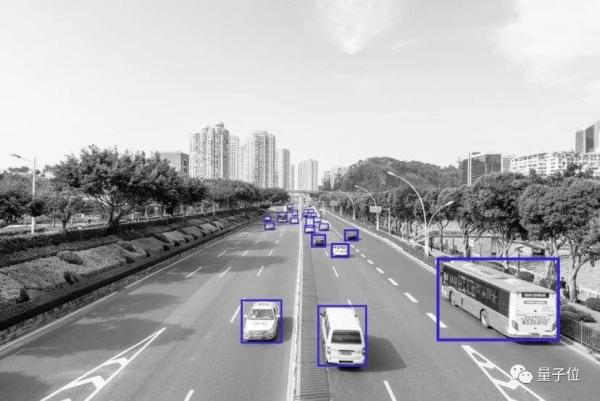
另一方面,人工智能的“思考”和“决策”依赖于大量数据。尽管企业对数据的开放态度曾较为谨慎,但随着AI应用场景的逐步落地,相关的技术挑战也日益显现。例如,在无人驾驶领域,许多驾驶场景数据稀缺,单靠一家公司的力量收集全面的交通场景数据将耗费巨大的成本,并且短时间内难以完成。
因此,格物钛希望能够打破数据共享的壁垒,通过开源的方式实现优质数据的合作与共赢。
正如GitHub在代码领域所发挥的基础设施作用,AI数据领域同样需要这样的平台。
随着AI技术的深入应用,另一个显而易见的情况是:在现实世界中,只有一小部分机器学习系统是由机器学习代码构成的,而其所需的配套基础设施却庞大且复杂。
数据和数据集是其中的关键环节。进一步关注国内市场,我们会发现,适应AI项目落地的真实数据更为稀缺。

统计数据显示,国内已有近60万AI开发者,但面临的挑战包括:
开源数据集普遍依赖海外,匹配性不足;下载和解析难度大,效率低下;数据质量参差不齐,难以保障;而最重要的是,缺乏本土化的数据。
这导致超过70%的企业面临数据共享困难、数据版本管理混乱、数据可视化标签转换复杂等问题,缺乏专门管理非结构化数据的共享协作平台。
因此,格物钛面临的关键问题是:
如何解决这些问题?

寻集令
顾名思义,寻集令的目标是寻找数据集。
这一过程分为两步。
第一步,与AI行业的先锋公司合作。
共同建立一个涵盖自动驾驶、互联网娱乐、新零售、智慧城市及在线教育等紧迫AI商业应用的开放数据集生态联盟。
可以说,这是一个开端,初步展现其价值,随后将吸引更多企业和组织参与。
在寻集令发布会上,元戎启行、新石器、速腾聚创等多家公司均表示支持。
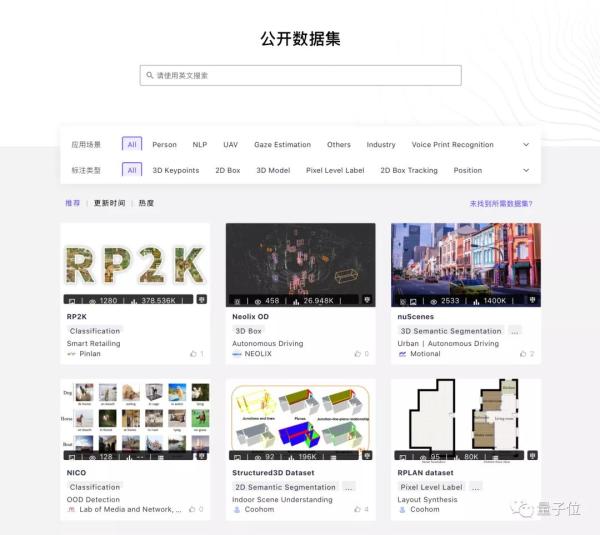
格物钛希望借助寻集令的第一步,打造中国最大规模的非结构化数据集平台。
平台将全面覆盖图像、视频、语音和文本等多种类型的数据。
资源上,既包括公开数据集,也包括AI头部企业的数据资源。
领域上,从商业落地最为紧迫的自动驾驶、互联网娱乐、智慧工业、新零售、在线教育和直播等开始。
此外,期望这个数据平台能够像GitHub一样,成为开发者喜爱的社区,并提供卓越的数据集管理体验,包括安全性等基本要求。
尽管国内尚缺乏这样的开源数据集平台,但这并不意味着行业内没有探索。
之前,创新工场与国内领先的AI公司共同发起了AI ChallengeR大赛,百度、腾讯、华为、字节跳动等公司也举办了以数据集为核心的挑战赛。
只不过,始终缺乏一个“全职”来推动这一事业的人。
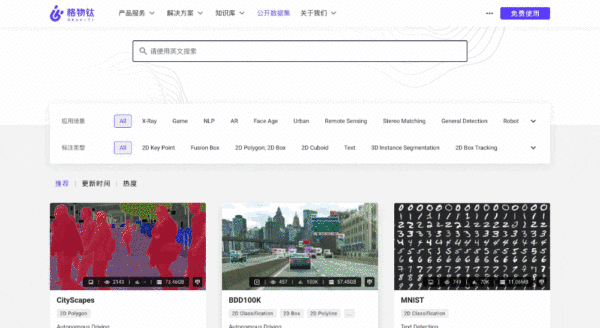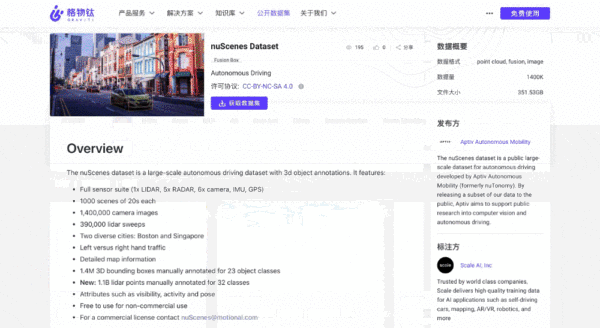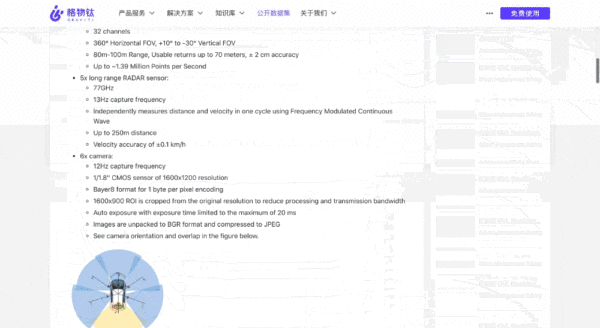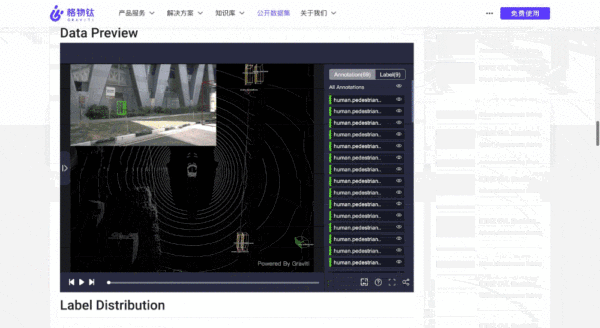
AI从业者都明白数据集的重要性。
例如,假如没有ImageNet,这场AI复兴可能不会这样迅速发展,李飞飞和李佳等华人科学家在数据集上的努力,加速了这一浪潮的复兴。
同时,数据集也能强化产学研之间的紧密合作,若资源能够更便捷地利用,或许将吸引更多力量参与其中,从而提升和优化相关领域的算法。
换句话说,公开共享数据集如同发起一场比拼,产学研各方的高手不仅在自我检测算法,也推动了数据集所在场景的不断提升。
从这个角度来看,也不难理解为何能获得陆奇的支持。
在奇绩创坛的DEMO day上,寻集令项目得到重点介绍,陆奇也亲自为其致辞。
总之,这是一个值得关注的项目,终于有人在这方面采取了行动。

谁是推动者?
最后介绍一下格物钛的创始团队,核心成员均具备技术背景。
创始人兼CEO崔运凯,曾是Uber无人驾驶团队的早期员工,长期从事人工智能研究与产品化,经历了Uber无人驾驶团队从50人增长到1500人的过程,成为该部门最年轻的技术负责人。
其他两位联合创始人分别是陈麒任和王广宇。陈麒任曾在Snapchat工作,是聊天系统和游戏系统的核心开发者,具备丰富的分布式系统软件开发经验;王广宇则在阿里巴巴本地生活服务公司担任高级产品专家,负责平台的搭建并实现了可观的成长和收入。
