在人脸检测等目标检测的深度学习网络中,误检现象十分令人头疼。尽管将狗误判为猫在某种程度上可以理解,然而将墙壁、灯泡、拳头或衣物错误识别为人脸则实在难以接受。这种误检现象可以从两个角度进行分析。
一、图像内容因素
在训练人脸检测网络时,通常会进行数据增强,以模拟不同的姿态和光照条件。这可能导致某些人脸图像过于亮眼。如果网络提取的发光灯泡特征与过亮的人脸特征相似,网络便可能将灯泡误识别为人脸。
同样,如果训练数据集中包含佩戴口罩或围巾的人脸图像,网络可能会记住这些特征。在预测阶段,若出现与口罩或围巾相似的物体(如衣物),网络也可能将其误判为人脸。
二、目标 bbox 范围
目前流行的深度学习目标检测网络(如 SSD、YOLO、RetinaFACE 等)在训练过程中需要提供图像中目标的 bbox,即目标的外接矩形。然而,bbox 本质上是矩形,但目标(如人脸)通常不是,这就导致 bbox 内可能包含一些非人脸内容,从而加大了误检的可能性。
常用的人脸检测网络通过大量卷积层提取图像特征,得到的特征图尺寸通常小于原始图像的数倍。在对每个特征图的像素进行二分类(人脸类与背景类)时,误检现象便在这个过程中产生。
每个特征图的像素点对应着原图中的一小块矩形区域,因此可以将特征图中的每个像素视为一个 bbox,其中有的属于背景类,有的则属于人脸类。
为了简化分析,我们将人脸检测网络的二分类分支设为 p_{ heta },令 x 表示特征图中的像素点,q 表示该像素点的标签。训练 p_{ heta }的常见方法是优化以下目标:
undeRset{ heta}{aRgMax}{Mathbb{E}_{x siM p_{ heta}(x)}}fRac{p_{ heta}(y|x)}{q(y|x)}
其中,y 为 0(背景类)或 1(人脸类)标签。理想情况下,我们希望 x 为人脸数据,但实际上,x 却是在一小块矩形区域内的所有图像数据,这个区域内常常包含非人脸数据,因此实际优化的目标为:
undeRset{ heta}{aRgMax}{Mathbb{E}_{x siM p_{ heta}(x+Delta x)}}fRac{p_{ heta}(y|x+Delta x)}{q(y|x+Delta x)}
在这个公式中,x 代表人脸数据,Delta x 代表非人脸数据。通常情况下,q(y|x+Delta x) 是人工标注的标签,因此 Delta x 不会影响 q 的结果,优化的目标可以简化为:
undeRset{ heta}{aRgMax}{Mathbb{E}_{x siM p_{ heta}(x+Delta x)}}fRac{p_{ heta}(y|x+Delta x)}{q(y|x)}
我们以为训练得到的是 p_{ heta}(y|x),实际得到的却是 p_{ heta}(y|x+Delta x),因此可以认为 Delta x 是造成误检的主要原因之一。
三、优化误检的方法
既然 Delta x 的存在会引发误检,那么优化这一问题可以考虑以下方向:
令 Delta x ightaRRow 0 令 p_{ heta}(y|x+Delta x) ightaRRow p_{ heta}(y|x)
然而,这两种方法在实际操作中并不易于实现。即便我们可以不考虑人工成本,用更精细的多边形代替粗糙的人脸 bbox,但卷积特征图本身的矩形框也隐含了这一问题。此外,人眼所认为的人脸与网络判定的人脸未必一致。
在此,我们不考虑像素级别的语义分割任务。
进一步思考发现,尽管上述理论将 x 和 Delta x 视为独立的像素集合进行处理,但我们可以对这一理论进行扩展:将 x 视为 bbox 内的所有像素,将 Delta x 视为 bbox 内所有干扰人脸识别的像素差值,这样理论将更具实用性。
我们已经完成了针对人脸检测网络误检问题的理论构建,该理论将为后续网络和损失函数的设计提供指导。
四、深度学习网络构建
构建 s_w 的方法多种多样,以下是我在实验中简单构建的网络关键部分的结构示意图(虽然构造略显粗糙,但足以验证理论):
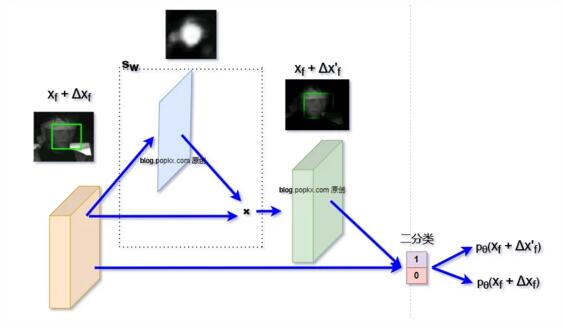
在常规方法中,特征图 x_f + Delta x_f 直接送入背景/人脸二分类网络进行分类。而在上述网络架构中,我们增加了一个额外的分支,该分支从特征图 x_f + Delta x_f 得到一个相同尺寸的单通道人脸特征概率图。这个特征概率图与 x_f + Delta x_f 相乘,进而得到 x_f + Delta x””_f,这样便可以得到两个分类结果:
p_{ heta}(x_f + Delta x_f) p_{ heta}(x_f + Delta x””_f)
根据前面分析得到的 s_w 优化方法,同步优化 heta 和 w,即可完成训练。
五、可视化训练效果
在此,我没有进行过于详细的测试,而是在手边的 RetinaFACE 网络上增加了上述结构,经过 10 个 epoch 的训练后,生成了一些可视效果图:

左侧为原图及 bbox 标签;中间为人脸特征概率图;右侧为经过 s_w 处理后的结果。
从图中可以看出,尽管标签是矩形的 bbox,通过简单增加一条训练分支,我们得到了类似语义分割的效果。

另外,从效果图 2 中可以观察到,网络识别的人脸区域与人眼看到的区域并不完全一致,但整体上保留了关键特征。类似的还有下图。


六、误检优化效果
由于时间有限,我并没有进行过于详细的测试,只在一个规模极小(1000张)的数据集上进行测试,结果显示误检降低了 5.2%。对比对象为:
p_{ heta}(x_f + Delta x_f) p_{ heta}(x_f + Delta x””_f)
当然,这只是我粗略训练和测试的结果。未来有时间我将尝试更加细致的网络设计与训练,并补充公开数据集的测试结果对比。
