AI 的发展速度惊人!
在中国欢庆春节之际,DeepMind 和 OpenAI 这两大知名人工智能研究机构相继推出了重要成果:DeepMind 发布了基于 TRansfoRMeR 模型的 Alphacode,能够生成与人类程序员相当的计算机程序;与此同时,OpenAI 的神经定理证明器成功解决了两道国际奥林匹克数学题。
这两个领域的突破是否让你觉得耳熟?没错,早在 2021 年,OpenAI 就推出了 AI 代码补全工具 GitHub Copilot,并介绍了其背后的技术 codeX。而在去年下半年,DeepMind 也发布了其在数学难题解决方面的 AI 研究成果,并被刊登在《Nature》上。
尽管这两个研究机构的新成果为 AI 解决旧问题提供了新视角,但网友们也不禁感叹,AI 领域竞争十分激烈!
Alphacode 击败了 46% 的参赛者
在一篇最新的论文中,DeepMind 的研究团队介绍了 Alphacode。这一系统利用基于 TRansfoRMeR 的语言模型进行大规模代码生成,并将其编写为程序。

论文链接:https://sTorage.GoogleAPIs.coM/DeepMind-Media/Alphacode/coMpetITion_level_code_geneRation_wITh_alphacode.pdf
研究者在 codefoRces 挑战中测试了 Alphacode,codefoRces 是一个竞争激烈的编程平台,类似于国际象棋中的 Elo 评级系统,每周提供新的编程挑战和问题排名。与开发商业应用程序时可能面临的任务不同,codefoRces 的挑战更加独立,要求对计算机科学中的算法和理论概念有更全面的理解,通常结合了逻辑、数学和编码的专业知识。
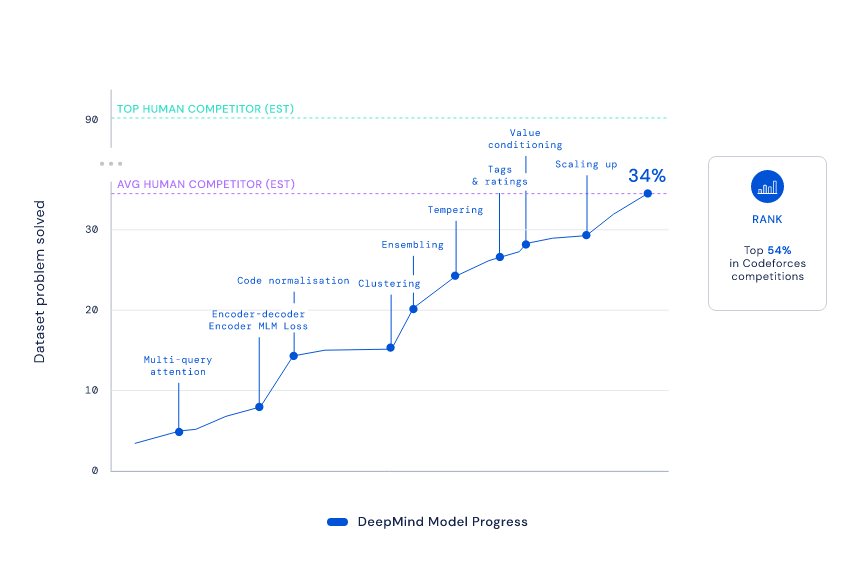
Alphacode 在 codefoRces 网站上针对 5000 名用户解决的 10 项挑战进行了测试,最终排名前 54.3%,这意味着它击败了 46% 的参赛者。DeepMind 估算,Alphacode 在 codefoRces 的 Elo 分数为 1238,在过去六个月的竞争中位列前 28%。
例如,在一项测试中,参赛者需要找到一种方法,将一个随机、重复的字符串 s 和 t 转换为另一个相同字母的字符串,且只能使用有限的输入,不能单纯输入新字母,还需使用「backspACE」命令删除原字符串中的某些字母。对 Alphacode 来说,这个挑战的难度中等:

在十个挑战中,Alphacode 以与人类相同的格式接收输入,并生成大量可能的答案,通过运行代码和检查输出进行筛选,过程完全自动化,无需人工干预。Alphacode 论文的联合负责人 Yujia Li 和 David Choi 表示:“整个过程是自动化的,无需人工选择最佳样本。”
想要在 codefoRces 的挑战中脱颖而出并不容易。Alphacode 项目启动已有两年多,随着 TRansfoRMeR 模型的进步及大规模采样和滤波技术的结合,DeepMind 的研究者在 AI 能解决的问题数量上取得了显著进展。

由于疫情影响,项目大部分工作是在家完成的。研究者在选定的公共 GitHub 代码上预训练模型,并在相对较小的竞赛编程数据集上进行微调。在评估阶段,他们创建了大量 C++ 和 Python 程序,数量远超以往工作。随后,通过筛选、聚类和排序,将解决方案汇总成一个包含 10 个候选程序的小集合,并提交进行外部评估,这一自动化系统替代了传统的调试、编译、测试和最终提交的反复过程。
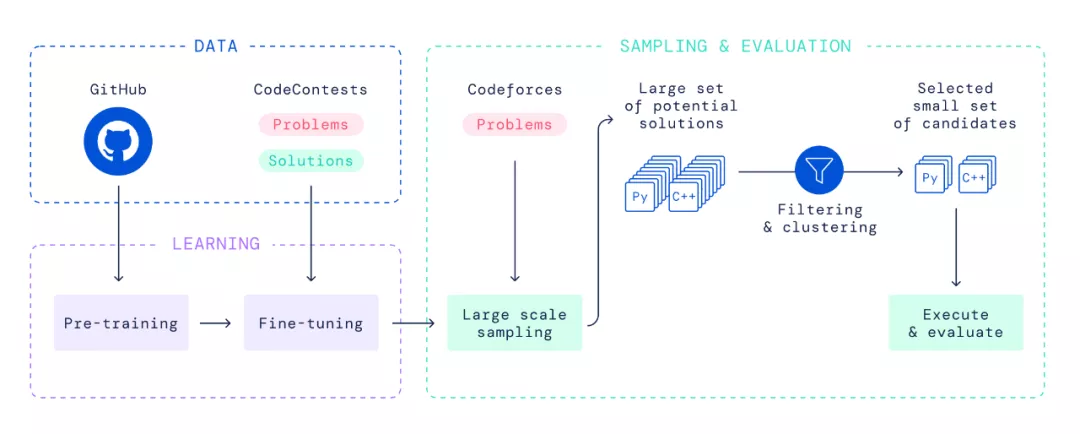
总体来看,Alphacode 的排名在竞争对手中大致处于中位数。尽管未能赢得比赛,但这一结果标志着人工智能在解决问题能力方面的重大进步,证明了深度学习模型在需要批判性思维的任务中的潜力。DeepMind 指出,Alphacode 目前的技能组合主要适用于竞技编程领域,但其能力为未来工具的开发铺平了道路,这些工具将使编程变得更加简便,甚至实现完全自动化。
与此同时,许多其他公司也在开发类似的应用。这些系统对最终用户而言,就如同 Gmail 的 Smart Compose 功能,能够提供你正在编写内容的建议。
近年来,AI 编程系统的开发取得了显著进展,然而这些系统尚未准备好全面取代人类程序员。它们生成的代码往往存在问题,且由于系统通常是在公共代码库上进行训练,因此有时会复制受版权保护的材料。
一项关于 GitHub Copilot AI 编程工具的研究显示,其输出的代码约 40% 存在安全漏洞。安全分析师甚至警告称,不法分子可能故意编写含有隐藏后门的代码并在线共享,从而被用来训练 AI 程序,将这些缺陷引入未来的代码中。
这类挑战意味着 AI 编程系统可能会慢慢融入程序员的工作中——换句话说,它们需要进行学徒训练,从助理角色开始,在被信任能独立执行任务之前,AI 提供的建议都需经过审慎评估。
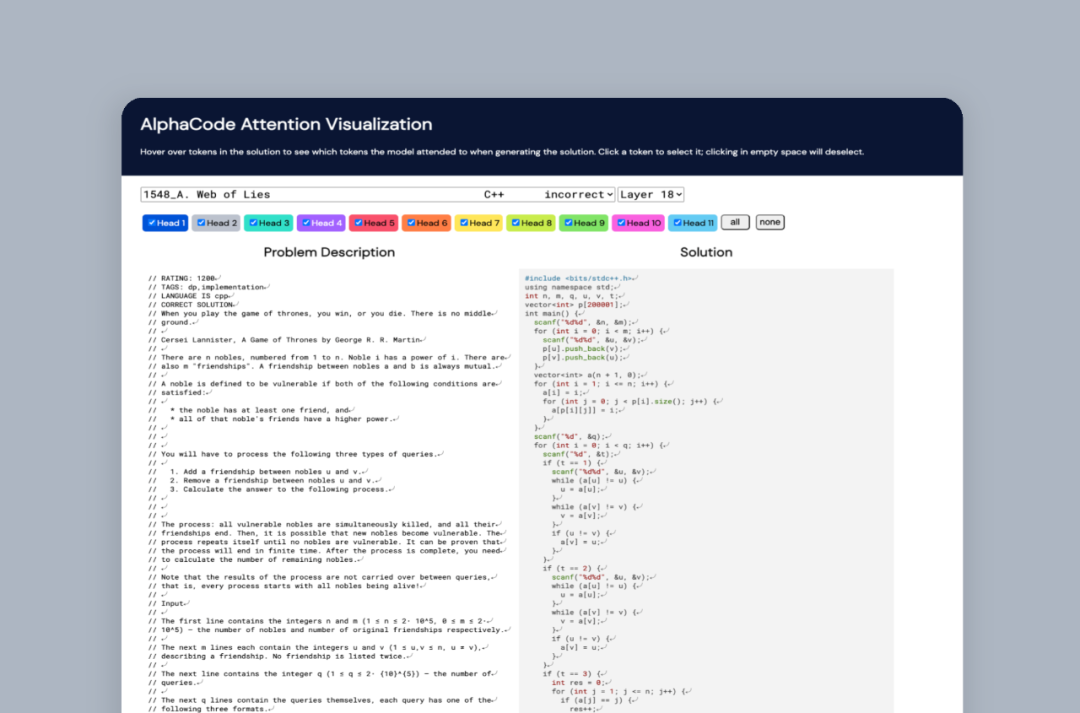
目前,DeepMind 在 GitHub 上发布了竞赛级编程问题和解决方案的数据集,其中包括广泛的测试数据,以确保通过这些测试的程序是正确的,这是当前数据集中所缺少的一个关键特性。DeepMind 希望这一基准能够推动在问题解决和代码生成领域的进一步创新。
GITHub 项目地址:https://Github.coM/DeepMind/code_contests
挑战国际数学奥林匹克题目的神经定理证明器
在学科竞赛领域,国际数学奥林匹克(IMO)是一项极具声望的比赛,许多数学天才(如韦东奕)都在此赛事中取得了卓越的成绩。
2021 年,这项比赛迎来了一个小小的变化:微软研发多年、在数学界颇具声望的 AI——Lean 也加入了竞争,与人类选手同台竞技。据悉,Lean 是微软研究院于 2013 年推出的计算机定理证明器,数学家可以将数学公式转化为代码并输入到 Lean 中,让程序来验证定理的正确性。
由于 Lean 旨在争夺金牌,研究团队对其进行了不断的优化,其中也包括被微软收购的 OpenAI。近期,OpenAI 宣布他们已为 Lean 创建了一种神经定理证明器,能够解决多种具有挑战性的高中奥林匹克问题,包括两道改编自 IMO 的题目以及若干来自 AMC12 和 AIME 竞赛的问题。
该证明器利用语言模型寻找形式化命题的证明。每当发现一个新的证明,研究者都会将其作为新的训练数据,这样可以提升神经网络的能力,使其在迭代中找到更复杂的命题解决方案。
该证明器在 miniF2F 基准测试中达到了 SOTA 水平(41.2% vs 29.3%),miniF2F 包含了一系列具有挑战性的高中奥林匹克问题。
研究者将其方法称为 statement curriculum learning,包括手动收集的不同难度级别的命题(无需证明),其中最困难的命题类似于目标基准。最初,他们的神经证明器性能较弱,只能证明其中的一小部分。因此,他们逐步搜索新的证明,并在新发现的证明上重新训练神经网络。经过八次迭代,他们的证明器在 MiniF2F 上取得了优异的表现。
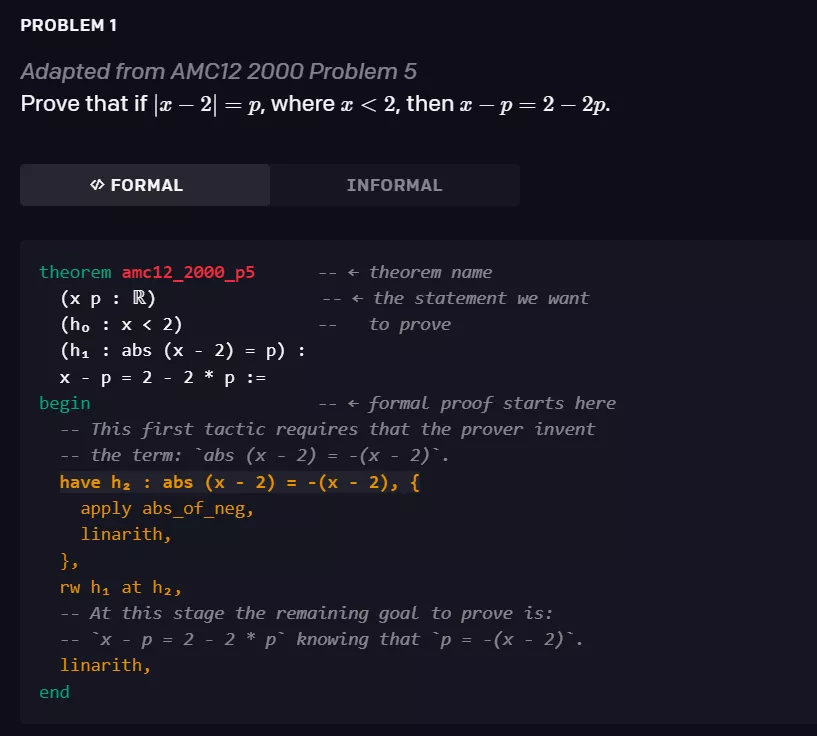
形式化数学是一个令人兴奋的研究领域,原因有二:1)它丰富多样,能够证明需要推理、创造力和洞察力的任意定理;2)它与游戏相似,同时也提供了一种自动化的方法来验证一个证明的成立(即由形式系统进行验证)。如下图所示,证明一个形式化的命题需要生成一系列的证明步骤,每个步骤都涉及策略的调用。
形式化系统接受的 aRtiFAct 是低级的(类似于汇编代码),人类生成这些内容相对困难。策略从更高层次的指令生成这种 aRtiFAct 的搜索过程,以辅助形式化。
这些策略以数学术语为参数,每次策略调用都能将当前待证明的命题转换为更易于证明的形式,直到不再需要证明。
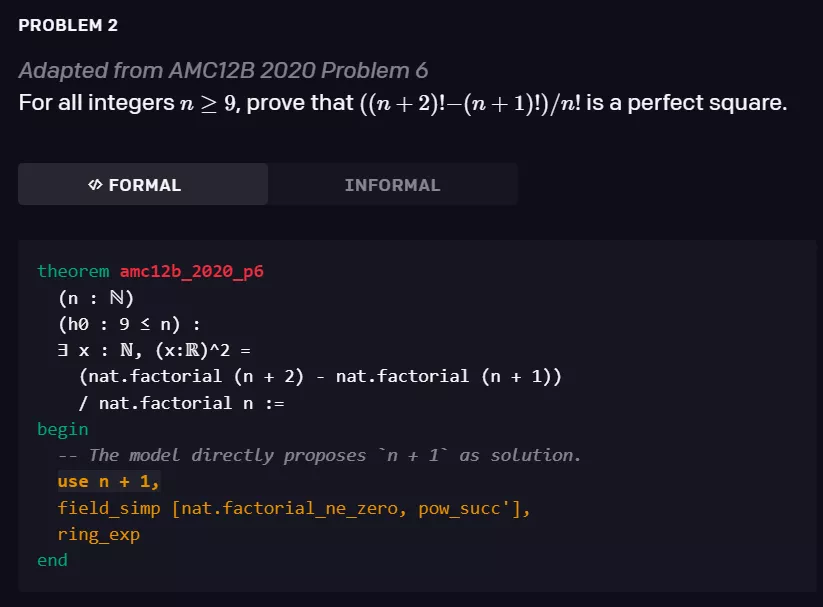
研究者注意到,生成策略参数所需的原始数学术语的能力在他们的训练过程中得以实现,这是神经语言模型所无法完成的。以下的证明是一个例子:证明步骤“use n + 1”(完全由模型生成)提出使用“n + 1”作为解决方案,其余的形式证明依赖于“Ring _ exp”策略以验证其有效性。
研究者还观察到,他们的模型和搜索过程能够生成连接多个关键推理步骤的证明。在以下证明中,模型首先利用引出存在性命题(existential statement)(∃(x : ℝ), f x ≠ a * x + b)的换质换位律(contraposition)。接着,它使用 USe (0 : ℝ) 生成一个 witness,并通过利用 noRM _ nuM 策略完成证明。
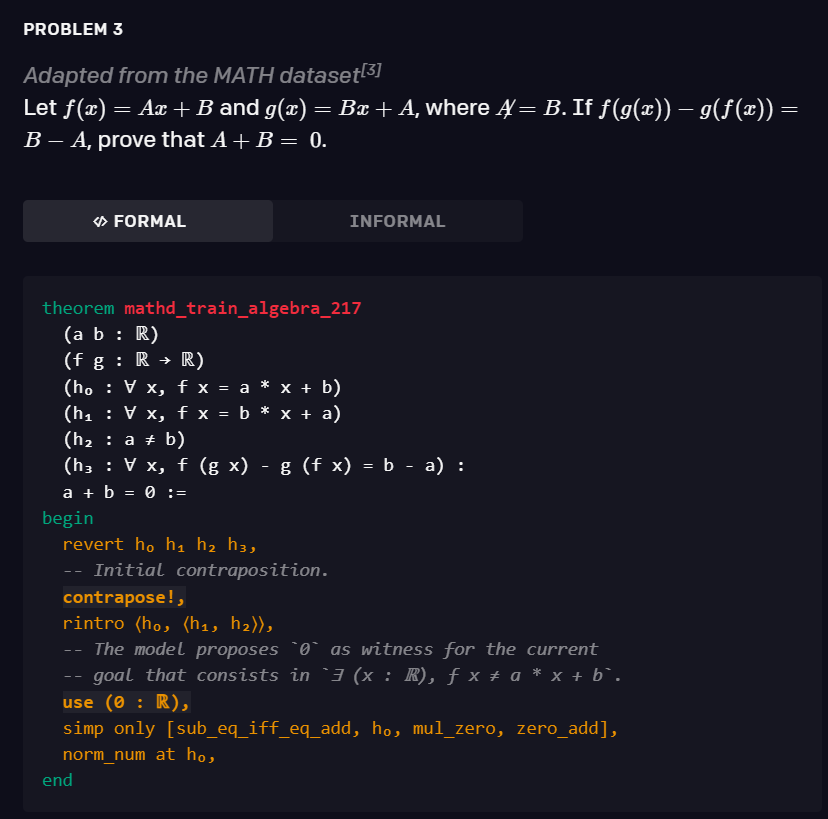
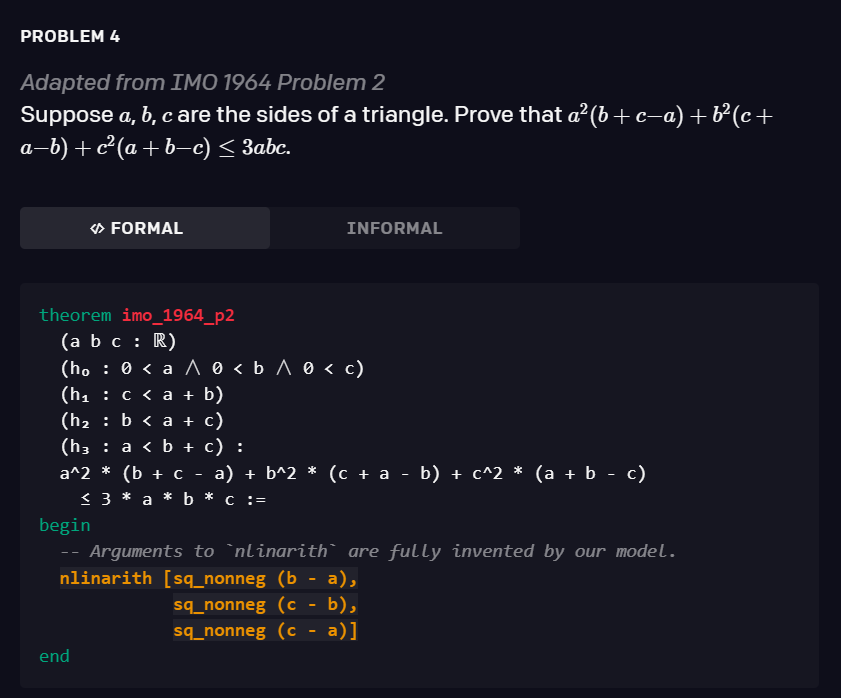
该模型经过 statement curriculum learning 的训练,能够解决培训教材以及 AMC12 和 AIME 中的各种问题,以及改编自 IMO 的两道问题。以下是三个相关例子。
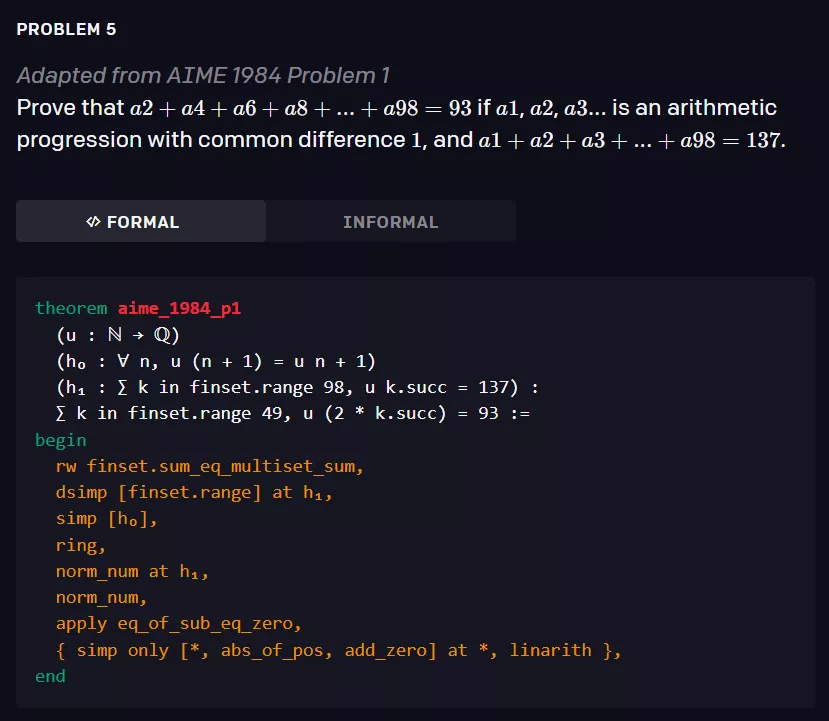
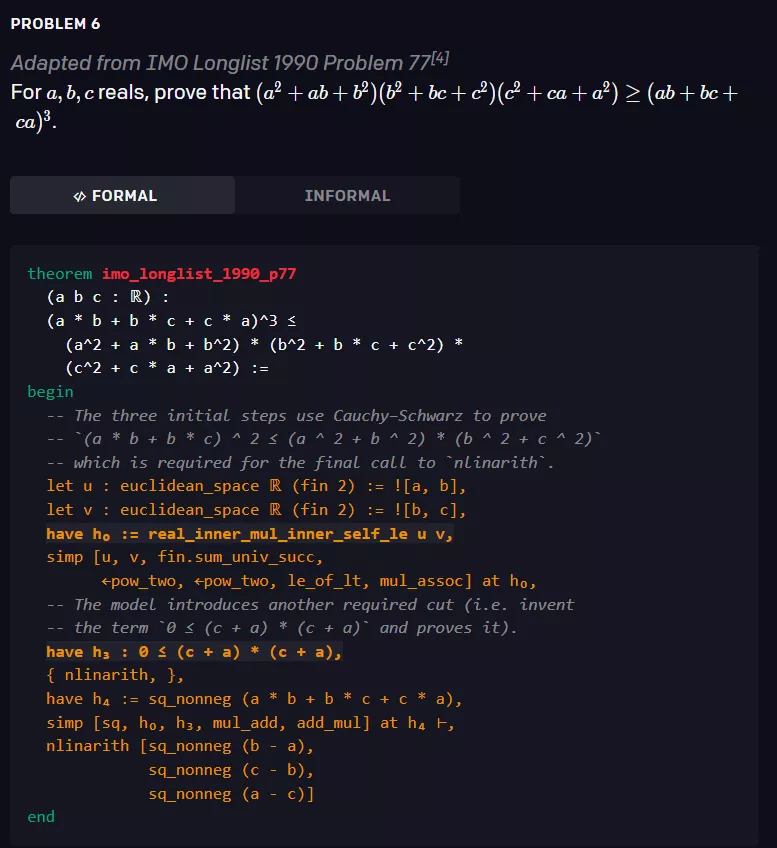
形式化数学面临两个主要挑战,使得单纯的强化学习应用难以成功:
1. 无限的动作空间:形式化数学不仅拥有庞大的搜索空间(例如围棋),同时其动作空间也是无限的。在搜索证明的每一步,模型的选择范围涵盖了一系列复杂且无限的策略,涉及必须生成的外生数学。
