
从少量静态图像中合成任意视角下的三维物体和场景,是 VR、AR 等应用中的关键能力。神经辐射场(NeRF)通过神经网络对场景进行建模,能够生成质量很高的新视图结果,因此受到广泛关注。
不过,传统 NeRF 在渲染时需要沿着每条光线进行大量采样,并反复调用神经网络计算颜色与密度,这使得整体渲染速度非常慢,很难满足实时交互场景的要求。为了解决这一问题,研究者提出了 PlenOctrees 表示方式,在保持较高画质的同时,将 NeRF 的渲染速度提升到可实时运行的水平,最高可比原始方法快 3000 多倍,同时还能缩短整体训练流程。

方法思路
在标准 NeRF 中,相机会向场景发射光线,并在光线路径上采样多个三维点。神经网络根据这些点的位置和观察方向,预测对应的体密度与颜色,再通过体渲染方式累积成最终图像。
这种做法的问题在于:每个采样点都要经过网络推理,而很多采样实际上落在空旷区域,对成像几乎没有贡献,因此计算成本很高。
针对这一点,该方法引入稀疏八叉树(Octree)结构来减少无效采样,并通过预计算体素中的表示信息,避免在渲染阶段重复执行大量网络计算,从而显著提高效率。
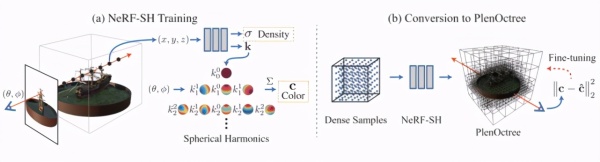
图 1 算法框架图
NeRF-SH 模型
方法首先使用 NeRF-SH 作为中间表示。它的整体训练和渲染流程与原始 NeRF 接近,但输出形式有所不同:模型不再直接预测 RGB 颜色,而是输出球谐函数(SH)系数。最终颜色由这些球谐系数结合当前射线方向进行加权计算得到。
这种设计可以更高效地表达视角相关的外观变化,也为后续转换到树结构提供了便利。
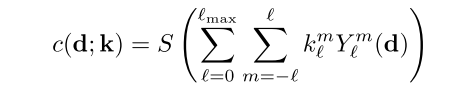
PlenOctrees 结构
在完成 NeRF-SH 训练后,研究者将其转换为稀疏八叉树结构,以实现实时渲染。整个转换过程主要包括以下几个步骤:
- 先在较高层级的网格上评估网络,仅保留密度信息;
- 根据阈值筛除无效体素;
- 对保留下来的体素内部随机采样,并对结果求平均,得到对应的球谐表示,再将其存储到八叉树叶节点中。
在渲染阶段,树中的数值仍然保持可微,因此还可以直接基于原始训练图像继续微调,进一步提升最终图像质量。
从效率上看,PlenOctrees 的优化速度约为每秒 300 万条光线,而原始 NeRF 约为每秒 9000 条光线,差距非常明显。也正因为如此,NeRF-SH 可以在尚未完全训练结束时就提前转换为 PlenOctrees,通常不会对结果质量造成明显影响。
实验结果
实验表明,这种方法不仅渲染更快,而且生成图像在细节表现上也具有很强竞争力,整体效果接近甚至优于原始 NeRF,同时实现了 3000 多倍的速度提升。

在训练时间方面,NeRF 与 NeRF-SH 的训练耗时基本相近。PlenOctrees 的结构转换与后续微调大约还需要 1 小时左右。但如果将 NeRF-SH 与 PlenOctrees 结合使用,整个流程大约 4.5 小时就能达到传统 NeRF 约 16 小时训练后的效果。
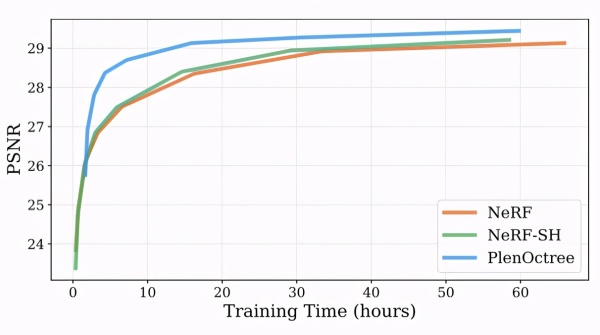
当然,这种加速方案也并非没有代价。相比传统 NeRF,基于 Octree 的表示通常会占用更多内存资源。因此,在实际部署时,需要在渲染速度、画质和硬件开销之间进行权衡。
