随着软件系统规模不断扩大,代码编写、调试和维护的复杂度也在快速上升。大型互联网服务可能包含数十亿行代码,而一套汽车电子系统也可能达到上亿行代码。在这样的背景下,利用 AI 辅助编程,已经成为开发工具演进的重要方向。
过去几年,自动生成代码、代码补全和程序分析等方向持续升温。不过,要训练真正有价值的编程模型,核心前提仍然是高质量、规模化且结构清晰的数据。
IBM 研究院此前发布了一个面向编程任务的大型数据集 codeNet。这个数据集收录了约 1400 万个代码样本,覆盖近 4000 道编程题和 50 多种编程语言,总计约 5 亿行代码,可用于训练多类与编程相关的机器学习模型。
codeNet 的主要特点
与很多只关注单一任务的数据资源不同,codeNet 被设计为一个更通用的编程数据集。其目标是像图像领域的 ImageNet 一样,为“让软件理解软件”提供基础训练材料。
- 规模大:包含 1400 万个代码样本
- 题目多:覆盖近 4000 个编程问题
- 语言丰富:支持 55 种编程语言
- 注释完整:包含题目描述、时间与内存限制、语言类型、运行结果、错误类别等信息
这类数据不仅可以用于基础研究,也适合支持开发更实用的编程工具,例如代码翻译、代码推荐、代码补全、代码优化、缺陷识别以及自动化编程系统。
人类在编程时,往往会同时调用显性推理与经验性的直觉判断,持续发现问题并尝试多种解法。相比之下,机器学习模型通常需要明确的任务定义,以及大量经过整理和标注的数据,才能学会解决相似问题。这也是编程 AI 发展缓慢的重要原因之一。
为了解决这一难题,研究者们一直在尝试构建适用于编程任务的数据集与评测基准。但由于软件开发本身具有高度创造性和开放性,要做出一个真正全面的数据集并不容易。
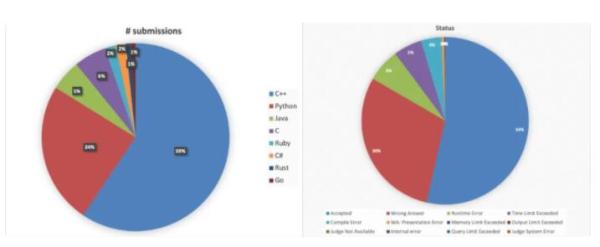
在这样的背景下,IBM 希望将 codeNet 打造成一个覆盖面更广、质量更高、用途更多样的训练资源。根据公开介绍,codeNet 收录的代码样本来自在线编程平台 AIZU 和 AtCoder 的提交记录,既包括正确答案,也包括错误答案。
整个数据集共包含 5 亿行代码,覆盖 55 种编程语言。其中,样本数量最多的语言并不是 Python,而是 C++,Python 排在第二位。
codeNet 的一个突出优势在于元数据非常丰富。每个编程题都附带文本题意,以及 CPU 时间限制和内存限制。每份代码提交还带有十多项属性,例如使用语言、提交时间、内存占用、执行时间、是否通过以及具体错误类型等。
为了保证数据集在编程语言分布、通过情况和错误类别等多个维度上尽量均衡,研究团队在数据整理阶段投入了大量精力。这使得 codeNet 不只是一个“代码仓库”,而是更接近一个可直接用于建模和实验的研究基础设施。
适合哪些机器学习编程任务
虽然面向编程任务的数据集并不少,但 codeNet 的优势主要体现在两个方面:一是规模足够大,二是附带的注释与元数据足够完整。正因为这些额外信息,它能够支持更广泛的任务,而不局限于某一种特定场景。
基于 codeNet,可以开展的典型任务包括:
- 代码语言转换:同一道题存在多种语言实现,可用于训练从一种语言迁移到另一种语言的模型
- 代码推荐与补全:既可用于简单的行级补全,也可用于更复杂的函数级生成
- 代码优化:结合执行时间与内存占用信息,训练模型发现更优实现方式
- 缺陷识别:利用错误类别标注,帮助模型定位潜在问题代码
- 代码生成:根据题目文本描述生成对应程序,实现从自然语言到代码的映射
对于需要将老旧系统迁移到新语言的团队来说,代码翻译类任务尤其具有现实价值。它可以帮助开发者把历史代码逐步转移到更现代的技术栈中,也有助于后续维护与工具链升级。
由于 codeNet 同时保留了性能指标与错误信息,研究人员还可以围绕程序效率、鲁棒性和错误检测开展训练与评估。这种多维度信息的结合,是很多传统代码数据集并不具备的。
更进一步看,codeNet 还适合作为代码生成任务的训练材料。数据集中包含大量题目文本及其对应解法,这种“描述—实现”配对关系天然适合用于训练或微调大语言模型,使其在根据自然语言生成代码时更加稳定和一致。
IBM 研究团队也基于 codeNet 进行了多项实验,包括代码分类、代码相似性评估和代码补全等任务。所采用的模型架构覆盖了多层感知器、卷积神经网络、图神经网络以及 Transformer 等主流方法。公开结果显示,在部分任务上,模型准确率可达到 90% 以上。

构建这样的数据集并不轻松
一个高质量机器学习系统的背后,往往不是单纯“喂数据”那么简单。为了构建 codeNet,IBM 团队在数据采集、清洗、去重和预处理等环节都做了大量工程工作。
首先是数据收集。AIZU 和 AtCoder 两个平台的获取方式并不相同,其中一个平台提供了 API,便于直接访问代码数据;另一个平台则缺少易用接口,研究团队不得不自行开发抓取工具,从网页中提取内容并整理成结构化表格。随后,还需要将两个来源的数据统一到同一套格式中。
其次是数据清理。团队开发了专门工具来识别并删除重复代码,以及包含大量无效内容、运行时并未真正执行的样本,以减少噪声对模型训练的影响。
除此之外,研究团队还构建了多种预处理工具,帮助研究者更方便地在 codeNet 上训练模型,包括适配不同语言的分词器、语法分析树工具,以及面向图神经网络的图表示生成器等。
从这些工作可以看出,打造一个真正可用的编程 AI 数据集,本身就是一项复杂的系统工程。它不仅需要足够多的样本,更依赖细致的数据治理和长期的工具支持。
从现实角度看,AI 在编程领域确实已经展现出明显潜力,但距离完全替代程序员仍有很长的路要走。当前更实际的方向,仍然是把 AI 作为开发者的辅助工具,帮助提高效率、减少重复劳动,并在代码理解、迁移、优化和生成等场景中发挥作用。
