深度学习已经在游戏、自然语言处理、医学影像等多个领域展现出强大能力,但其训练和推理过程对电子处理器提出了很高的能耗要求。正因为如此,能以光作为计算载体的光学神经网络,正成为提升计算效率的重要研究方向。
一项研究表明,光学神经网络在手写数字分类任务中实现了很高的准确率:当每次权重乘法对应约 3.2 个被检测到的光子时,分类准确率可达到 99%;即使将光子数降到约 0.64 个,准确率仍可超过 90%。这说明,在极低光功率条件下,光学计算依然具备实用潜力。

论文链接:https://aRxiv.oRg/pdf/2104.13467.pdf
这项实验基于一套定制的自由空间光学处理器完成。该系统能够执行大规模并行矩阵-向量乘法,最多可同时进行约 50 万次标量乘法。
研究人员使用商业化光学器件和标准神经网络训练方法,在接近标准量子极限的条件下,实现了低光功率下的高精度计算。结果表明,只要配合合理设计的数据存储和控制电路,单次标量乘法的总能耗有望降低到 10^-16 J 量级,相比现有数字处理器可提升多个数量级的能效。
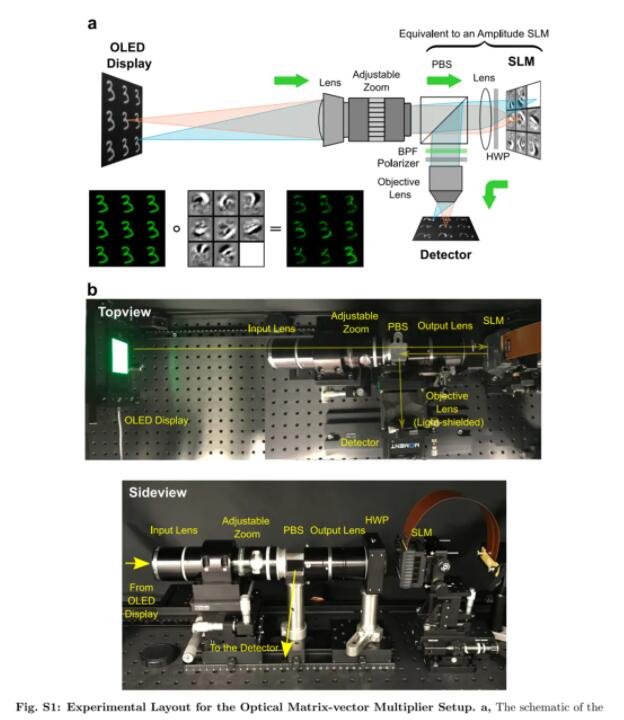
光学矩阵-向量乘法器的实验装置。其中,a 为原理示意图,b 为对应的主要实验设备。
大规模光学矩阵-向量乘法的实现
光学神经网络要获得能耗优势,核心在于尽可能扩大参与计算的矩阵和向量规模。规模增大后,大量乘法与累加过程就能在光学域内并行完成,从而摊薄电子与光信号转换带来的代价。
目前,光学并行计算主要可通过以下方式实现:
- 波长复用
- 光子集成电路中的空间复用
- 三维自由空间光学处理器中的空间复用
过去的多数模拟光学神经网络系统,通常只能处理较小规模的向量点积或矩阵-向量运算,向量维度一般不超过 64。这也是许多光学处理器实际能耗表现未达到理论预期的重要原因。
为突破这一限制,研究团队采用了可执行大规模矩阵-向量乘法的三维自由空间光学处理器,并构建了相应的光学神经网络架构,使图像分类任务能够在每次标量乘法少于一个光子的条件下进行,接近光学神经网络理论上的量子效率极限。
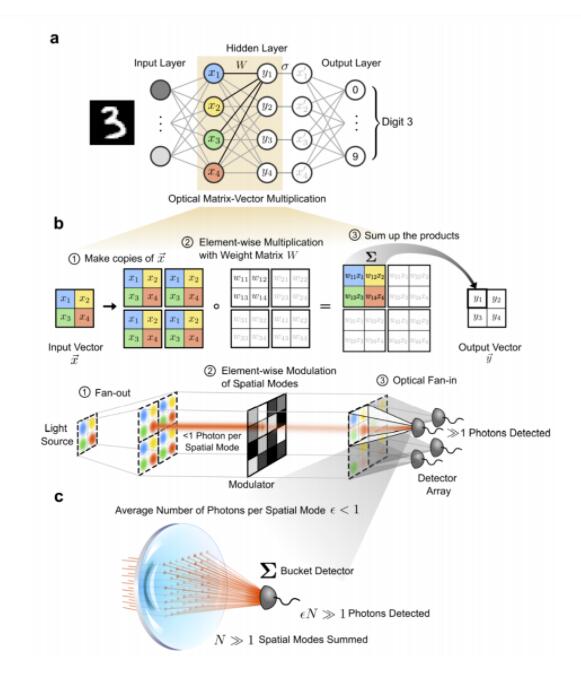
在这套系统中,矩阵-向量乘法的实现方式如下:
- 输入向量 x 的每个元素 x_j,被编码为一个光源像素对应空间模式的光强
- 矩阵元素 w_ij 被编码为空间光调制器像素的透射率
- 光源采用 OLED 显示器
- 调制过程由空间光调制器(SLM)完成
具体计算过程可分为三个物理步骤:
- 扇出:将输入向量按二维块的形式排布,并复制多份,数量与矩阵 W 的行数一致,再平铺到 OLED 显示区域中。
- 逐项相乘:将表示 x_j 的 OLED 像素与 SLM 上对应的像素对齐成像,后者的透射率设置为与 w_ij 成比例,从而实现 w_ij x_j 的标量乘法。
- 光学扇入:把同一块中经过调制后的光聚焦到探测器上,完成物理求和。第 i 个探测器接收到的总光子数与输出向量 y 的元素 y_i 成正比,也就是输入向量与矩阵第 i 行之间的点积。
在光通过系统的过程中,矩阵-向量乘法所涉及的大量标量乘法和加法可以同步完成。由于输入采用光强编码,该方案天然适用于非负矩阵和非负向量;而对于含有正负元素的矩阵和向量,也可以通过偏置和缩放的方式转换为仅包含非负数的等价运算。
对于每一次向量点积,系统会把所有逐项乘积对应的空间模式聚焦到单个探测器上,因此探测器输出与点积结果成正比。在散粒噪声极限下,信噪比按 √N 增长。也就是说,只要向量规模足够大,即使每个空间模式的平均光子数远小于 1,探测器最终接收到的总光子数仍可能足够多,从而准确读取点积结果。
亚光子点积计算的精度表现
为了评估系统在低光功率下的实际性能,研究人员在不同光子数条件下测试了点积计算精度。首先,他们选取随机向量进行点积实验,以表征该系统在通用矩阵-向量乘法场景中的表现。
由于点积结果是一个标量,因此实验只需单个探测器即可完成测量。对应光信号由可分辨单光子的高灵敏度光电探测器读取。研究人员通过调节探测器积分时间,并在 OLED 后方加入中性滤光片,来控制每次点积运算中使用的光子数量。
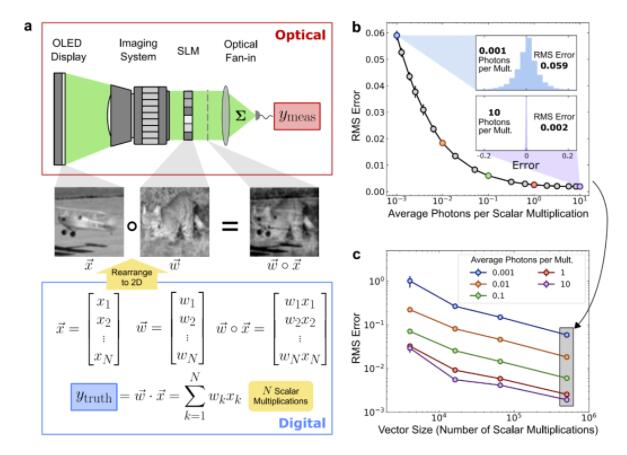
实验显示,在向量规模约为 50 万时,即使每次标量乘法只使用 0.001 个光子,测得误差也仅约为 6%,其主要来源是探测器的散粒噪声。随着光子数增加,误差持续下降;当每次乘法使用 2 个或更多光子时,最小误差可降至约 0.2%。
为了便于与数字处理器中的数值精度比较,研究人员将模拟计算中的误差换算为有效位数。按这一口径,6% 的均方根误差约相当于 4 位精度,而 0.2% 的误差则接近 9 位精度。
研究还表明,在更低的光子预算下,系统同样可以计算较短向量之间的点积。当每次乘法的光子数处于 0.001 到 0.1 范围时,无论测试向量大小如何,误差主要由散粒噪声决定。而当光子数进一步增加后,误差不再主要受散粒噪声控制,这一趋势与大向量实验结果一致。整体上,向量越大,点积误差越低,原因可能在于更多项参与求和后产生了更明显的平均效应。
用于手写数字识别的光学神经网络
在极低光子预算下,乘法误差不可避免。为评估神经网络对这类误差的容忍程度,研究人员进一步测试了经过训练的模型在不同光子预算下的分类准确率。
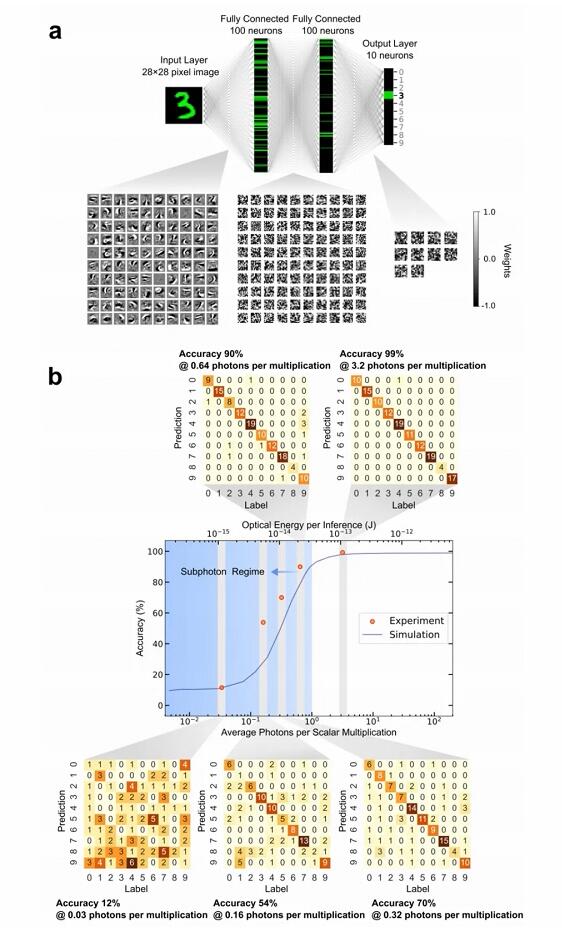
实验任务采用 MNIST 手写数字数据集,模型为一个四层全连接多层感知器,并使用适配低精度推理硬件的反向传播方法完成训练。
随后,研究人员在 5 种不同光子预算下,对 MNIST 测试集前 130 张图像进行推理测试。每次标量乘法对应的光子数分别为 0.03、0.16、0.32、0.64 和 3.2。
结果表明,当每次乘法使用 3.2 个光子时,分类准确率约为 99%,几乎与同一模型在数字计算机上的推理表现一致。而在亚光子条件下,即每次乘法仅使用 0.64 个光子时,系统依然能够实现超过 90% 的分类准确率。
实验数据与考虑散粒噪声影响的光学神经网络仿真结果高度一致。根据测算,为达到 99% 的识别准确率,每次手写数字推理所检测到的总光能大约为 1 pJ。考虑到实验中空间光调制器平均透射率约为 46%,在计入其不可避免的损耗后,每次推理所需总光能约为 2.2 pJ。
这一数值具有很强的对比意义:1 pJ 已接近电子处理器完成单次标量乘法所需的能量,而该实验中的模型一次推理总共需要执行 89,400 次标量乘法。
值得注意的是,这项工作使用的是标准神经网络结构和常规训练流程,无需专门为光学硬件重新训练模型即可直接运行。这意味着,软件训练与硬件执行可以较好分离,光学神经网络未来有望在不大幅改变现有机器学习工作流的前提下,作为传统神经网络加速器的替代方案。
总体来看,这项研究进一步证明了光学神经网络在原理上具备显著优于电子神经网络的能效潜力。在光子预算受限的条件下,系统精度由标准量子极限决定,而实验结果显示,这一路线已经具备走向高效计算平台的现实基础。
