一次夜间故障中,客户在扩容 Kubernetes 集群时发现新增节点始终无法加入,扩容流程持续失败。在多次自查仍未解决后,问题被提交到技术支持侧继续分析。整个排查过程较有代表性,尤其适合用来梳理 Kubernetes 网络故障的定位思路。
问题现象
在为集群新增节点时,运维人员观察到以下现象:
- 新增节点无法访问 Kubernetes Master Service 的 VIP。
- 新增节点直接访问 Master 节点的 Host IP 加 6443 端口是正常的。
- 新增节点可以正常 ping 通其他节点上的容器 IP。
- 新增节点访问 CoreDNS 的 Service VIP 也是正常的。
客户环境中,Kubernetes 版本为 1.13.10,宿主机内核版本为 4.18,操作系统为 CentOS 8.2。
初步排查
结合以往经验,问题一开始就指向了 IPVS 相关链路。先进行了几项常规检查:
- 确认 ip_tables 内核模块已加载。
- 确认 iptables 的 forward 策略为 accept。
- 确认宿主机网络正常。
- 确认容器网络正常。
常规项都没有发现异常后,排查范围基本可以收敛到 IPVS 与 kube-proxy 相关机制上。
通过 IPVS 观察连接状态
客户集群中,10.96.0.1 是 Kubernetes Master Service 的 VIP。使用 ipvsadm 查看后,发现存在异常连接,状态停留在 SYN_RECV。
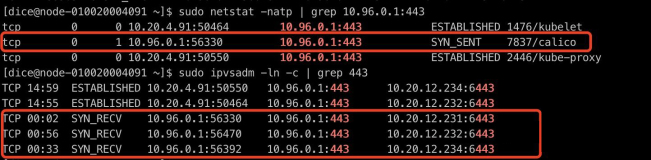
这说明 kubelet 和 kube-proxy 在启动阶段曾经建立过正常连接,但在后续运行过程中,Service 网络出现了异常。
抓包进一步确认
随后在通信两端进行抓包,并通过 telnet 10.96.0.1 443 进行验证。
抓包结果表明:SYN 包在本机并没有真正发送出去。
这个现象很关键,它意味着问题不在远端响应,而更可能发生在本机转发或规则处理阶段。
怀疑 kube-proxy
由于当前集群采用的是 IPVS 模式,而 IPVS 在实际工作时仍然依赖 iptables 完成部分转发、SNAT 和丢弃等动作,因此排查重点转向了 kube-proxy。
查看 kube-proxy 日志
检查日志后,发现了明显异常:iptables-restore 执行失败。
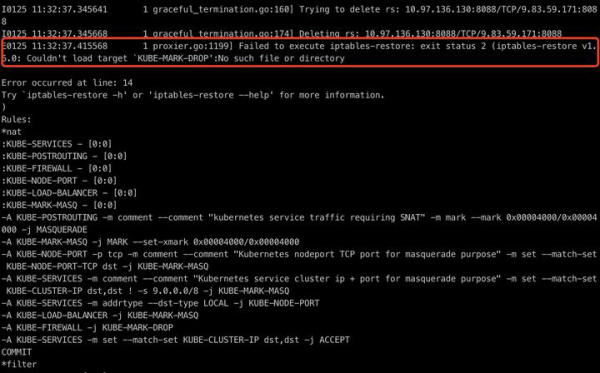
结合社区资料和已有经验,可以基本确认问题与 iptables 规则下发失败有关。
继续深入:版本缺陷浮现
进一步查看 Kubernetes 1.13.10 版本中与 IPVS 代理相关的代码,可以发现该版本在处理 KUBE-MARK-DROP 链时存在缺陷:如果该链不存在,程序不会主动判断并创建,结果会导致后续执行 iptables-restore 时失败。
这也解释了一个关键现象:为什么 Master Service VIP 不通,但容器 IP 却仍然可以通信。原因与一条 Service 相关的 NAT 规则处理逻辑有关,规则未正确恢复后,部分 Service 访问路径就会失效,而容器网络本身不一定受影响。
根因追踪
到这里,已经知道 Kubernetes 1.13.10 在 kube-proxy 的规则处理上存在问题。但还有一个更深的问题需要回答:为什么同样的 Kubernetes 版本,在 CentOS 8.2 的 4.18 内核上会失败,而在 CentOS 7.6 的 3.10 内核上却表现正常?
由于 kube-proxy 本质上也是通过执行 iptables 命令来维护规则,因此需要直接到现场环境中验证规则状态。
进入 kube-proxy 容器执行 iptables-save,可以看到容器内确实没有 KUBE-MARK-DROP 链,这与代码逻辑一致;但在宿主机上执行 iptables-save 时,却能看到这个链存在。
由此产生了两个疑问:
- 为什么 4.18 内核宿主机上存在 KUBE-MARK-DROP 链?
- 为什么宿主机和 kube-proxy 容器内看到的 iptables 规则不一致?
答案一:不只有 kube-proxy 在改 iptables
继续检查 Kubernetes 源码后可以确认,除了 kube-proxy 之外,kubelet 也会修改 iptables 规则。因此宿主机上出现额外链路并不奇怪。
答案二:CentOS 8 默认采用 nftables
第二个问题的关键,在于 CentOS 8 的网络栈行为发生了变化。该系统默认已经转向 nftables 框架,而不再沿用传统 iptables 作为默认的包过滤实现。
这就导致了宿主机与容器内对规则的观察和操作结果可能不一致,也最终触发了 kube-proxy 在旧版本中的兼容性问题。
至此,整个问题链路已经打通:Kubernetes 1.13.10 的 kube-proxy 本身存在缺陷,而 CentOS 8 默认采用 nftables 的环境又放大了这个问题,最终导致 Service 相关规则恢复失败,新增节点无法通过 Master Service VIP 加入集群。
几个常见疑问
为什么这个问题并不常见?
因为它需要同时满足几个条件:Kubernetes 1.13.10、CentOS 8.2,以及相关网络路径刚好触发缺陷。这个组合本身并不普遍,但一旦出现,问题通常可以稳定复现。实际验证表明,升级到 Kubernetes 1.16.10 及以上版本后,这类问题不会再出现。
为什么使用 Kubernetes 1.13.10 配合 5.5 内核时没有出现同样的问题?
关键不只是内核版本,更与操作系统默认采用的网络框架有关。即使手动升级到 5.5 内核,如果系统仍然使用传统 iptables 框架,也可能不会触发这一问题。
可以通过执行 iptables -V 来判断系统当前是否基于 nftables。

至于 nftables 与 iptables 的区别,以及它们各自的优劣,则是另一个值得深入学习的话题。
解决方案
结合本次排查结果,可行的处理方式主要有以下几种:
- 使用 CentOS 7.6 及以上、3.10 内核体系的环境。
- 手动升级到 5.0 及以上内核,并确认实际网络框架配置。
- 升级 Kubernetes 版本,已确认 1.16.10 及以上版本不存在该问题。
如果生产环境仍在使用较老版本的 Kubernetes,尤其是在 CentOS 8 这类默认引入 nftables 的系统上,建议优先评估升级方案,以避免类似兼容性问题再次出现。
