在实时数据处理场景中,常见需求之一就是对 PV 和 UV 进行持续统计,并按照日期与小时维度展示结果,例如按 date、hour、pv、uv 输出。通常这类统计会以天为周期进行汇总,到了第二天重新开始计算。
如果业务还有更细的分析需求,也可以继续按照类型字段扩展维度,例如输出为 date、hour、pv、uv、type。本文先聚焦最基础的实时 PV、UV 统计实现方式。
示例结果类似如下:
id uv pv date hour
1 155599 306053 2018-07-27 18
整体处理流程
整个实时统计链路可以概括为:日志采集、消息传输、流式计算、去重统计、结果落库展示。
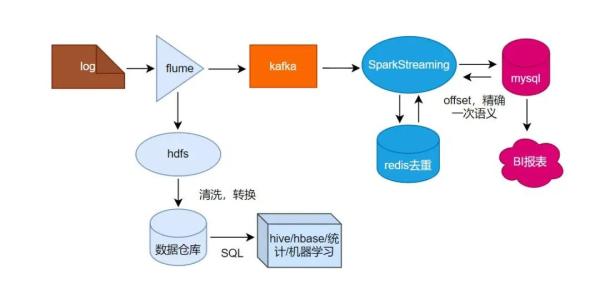
日志首先由 Flume 采集,一方面写入 HDFS 供离线业务使用,另一方面同步写入 Kafka。Spark Streaming 从 Kafka 中消费实时数据后,完成 PV 和 UV 的计算。其中:
- PV 通过流式状态计算完成累计;
- UV 借助 Redis 的 Set 集合完成全天去重;
- 最终统计结果写入 MySQL,供前端页面查询和展示。
PV 的实时计算
从 Kafka 拉取数据时,常见有两种方式:Received 模式和 Direct 模式。这里采用 Direct 直连拉取方式,这种方式在稳定性和控制能力上更适合生产环境。
在状态维护方面,使用 mapWithState 算子来保存和更新统计状态。它与 updateStateByKey 的用途相似,但整体性能通常更好,因此更适合实时累加类场景。
实际业务中,原始日志往往不能直接参与计算,通常还需要先经过清洗、过滤、字段提取等步骤,得到可用于统计的结构化数据,然后再进入 PV 累计逻辑。
PV 的核心思路比较直接:每来一条有效访问记录,就对对应时间维度下的访问次数加 1,并持续更新状态。通过定义状态更新函数,即可实现实时 PV 统计。
UV 的实时计算
相比 PV,UV 的难点在于“全天去重”。也就是说,同一个用户在同一天内无论访问多少次,都只计为一个独立访客。
如果直接使用 Spark 原生的 reduceByKey 或 groupByKey 来做大规模去重,在机器配置不高的情况下会带来较大的资源压力。因此,这里采用 Redis 来承担去重任务,并申请了较大容量的 Redis 实例用于存储每日用户集合。
实现原理是:每当一个批次的数据到来时,以当天日期作为 Redis 的 key,把用户标识(如 guid)加入对应的 Set 集合。由于 Set 天然具备去重能力,因此同一用户重复写入不会重复计数。
随后按照固定频率刷新统计结果,例如每 20 秒读取一次该 Set 的大小,将最新 UV 更新到数据库中。
相关处理逻辑如下:
helper_data.foreachRDD(Rdd => { Rdd.foreachPartition(eachPartition => { // 获取Redis连接 eachPartition.foreach(x => { // 省略若干... jedis.sadd(key,x._2) // 设置存储每天的数据的set过期时间,防止超过Redis容量,这样每天的set集合,定期会被自动删除 jedis.expire(key,ConfigFactory.Rediskeyexists) }) // 关闭连接 closeJedis(jedis) }) })
这段逻辑的关键点主要有几个:
- 按分区处理数据,减少 Redis 连接的频繁创建;
- 使用
sadd将用户标识写入 Set,实现天然去重; - 为每天的 key 设置过期时间,避免 Redis 中历史数据无限增长;
- 定时获取 Set 的大小,并同步更新 MySQL 中的 UV 结果。
实现思路总结
这套方案适合中小规模的实时 PV、UV 统计需求,结构清晰,也比较容易落地:
- Kafka 负责承接实时日志流;
- Spark Streaming 负责消费与计算;
- PV 使用状态算子进行实时累加;
- UV 使用 Redis Set 做按天去重;
- MySQL 负责结果存储与展示。
如果后续还需要按业务类型、渠道、页面等维度继续细分,只需要在现有统计 key 的基础上扩展字段即可。对于实时访问分析类需求来说,这是一个较为实用且容易维护的实现方式。
