大模型时代的创造力边界:从工具到自动化的视角解读创新边界
最近,一份来自美国市场研究机构的报道引发关注。文章详细分析了 OpenAI 部署 Sora 所需的硬件资源,计算结果显示在峰值期需要高达 72 万张英伟达 H100 显卡来支撑,对应成本达到巨额水平。
另一条新闻也在热议:一名微软工程师爆料,为了训练 GPT-6 搭建了10万个 H100,最终导致电网压力剧增。这些资讯让关注大模型的人开始反思:如此耗费资源究竟是否值得,只为生成文本、视频等内容?
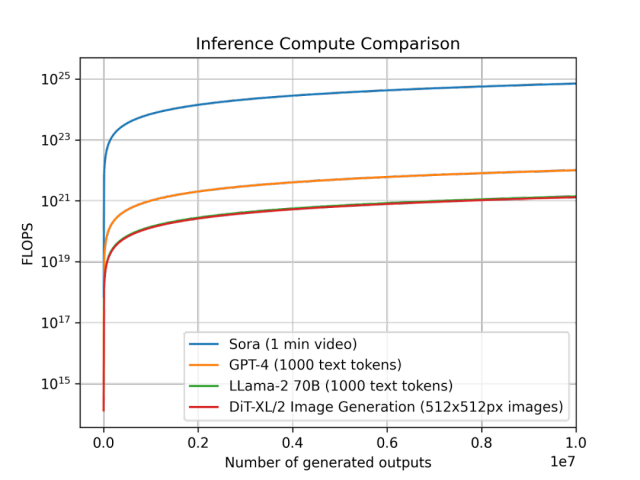
在一定程度上,ChatGPT 与 Sora 的崛起,确实在一定程度上限制了人们对大模型的想象力——人们往往把重点放在“通过预测下一个 Token 来理解世界”这一思路上,从而把资源投向文字和图像等生成任务。
但,真正的创新边界真的是被如此设限吗?最近行业内流传的一些有趣案例,已经极大拓展了人们对生成式 AI 的想象空间,展示了更多样化的应用形态。

图中是一种 AI 正在生成体检报告的场景——它在生成“未来”的体检结果。健康管理领域中,及早对健康风险进行预警一直是关键挑战。
如果让生成式 AI 直接输出未来体检报告,是否具备实际价值?结果显示,未来的体检结果被生成出来并具有可操作的指引。
不仅如此,AI 甚至可以生成复杂系统的未来运行“体检报告”。例如水电机组的未来运行状态,精确到分钟的预测,提示潜在的高温故障,并建议维护与运行策略的调整点。
这些案例来自第四范式在产业界的实际落地。这些行业大模型,基于一个名为“先知 AiOS”的行业大模型平台,涵盖多类 AI 模型的开发、纳管和应用,平台已经发展到 5.0 版本。
一个值得关注的共同特征是:所有案例都在进行“Predict the next X”——而这个 X 不再局限于文本数据中的 Token,而是覆盖各行业的丰富模态数据。
在某种意义上,ChatGPT 的成功证明了通过大规模数据预训练,再以“Predict the next Token”的方式来实现智能,是可行的;Sora 则扩展了这一逻辑,使预测对象不再仅限文本。
因此,推动想象力和大模型价值的关键,在于不断扩展“Predict the next X”中的 X 的指代范围。
这个 X 可能是体检报告、水文数据,或是监测数值和应急预案。行业级大模型需要多样化的数据形态、扎实的行业知识,最终生成适用于特定行业的 X。
以下是一个垂直行业从业者开发的声效大模型场景。为音乐厅设计最佳声音体验时,只需让行业大模型在不同方案下生成声音方案、提供具体数据,并以直观图像呈现。
这种声音体验的生成,可能无法用传统“预测下一个单词”的思路来实现。但在对大量声音行业专有数据和形态进行训练后,生成出符合需求的方案成为现实。
要开发这样的模型,一个关键前提是让行业从业者拥有主动权,让专业知识和行业数据真正驱动模型能力的释放。
他们需要的并非一个单纯的“大语言模型”进行微调以适配行业数据,而是基于各类行业数据形态训练出的可落地的行业基座模型。
第四范式的 AiOS 5.0 能接收各种各样的“X”,再基于这些 X 构建垂直行业大模型。正如他们所说:“种瓜得瓜,种豆得豆。”单一的语言模型并不能解决所有问题。
这一思路也逐渐被更多科技巨头采纳。OpenAI 的高管也曾表示,不必期望一个万能的一体化模型解决所有场景。应通过按需调用不同模型来分配智能资源,以实现更高效的应用落地。
因此,不要被 ChatGPT 与 Sora 的现象所局限,“Predict the next X” 的 X 应有更广阔的形态。随着各行业数据形态的汇聚与协同,这一进程将逐步形成更丰富的生态,推动 AI 的实际应用走向更高的效率与智能化水平。
