PP-LCNet:面向 CPU 的高效骨干网络实现双倍提速
算法速度优化遇到瓶颈,达不到要求?应用环境没有高性能硬件只有 CPU?
是不是直接击中了开发者的痛点?今天为大家梳理一个在 Intel CPU 上表现出色的高性能骨干网络方案——PP-LCNet。
空口无凭,上图为证!

从上图可以看到,在相同精度下,PP-LCNet 的推理速度远超当前主流骨干网络,理论上实现多达 2 倍的性能提升。该网络在目标检测、语义分割等任务中同样能带来显著的性能改进。
论文发布与代码开源后,引起广泛关注。不少团队将 PP-LCNet 应用于 YOLO 系列等框架,带来可观的性能提升效果。
是否已经有伙伴跃跃欲试?
本文整理了开源代码入口,建议收藏以便后续参考与贡献。
开源地址:https://Github.coM/PaddlePaddle/PaddleClas
那么,PP-LCNet 之所以有出色表现,背后有哪些设计思路?下面一起领略要点。
PP-LCNet 核心技术解读
近年来涌现出不少轻量级骨干网络,NAS 搜索网络也层出不穷。但在实际产业环境,尤其是 Intel CPU 设备上,许多优化未能达到预期。基于此,针对 CPU 与 MKLDNN 等加速库,本文提出了独特的高性能骨干网络 PP-LCNet。相较于同类轻量化模型,PP-LCNet 在不增加推理时间的前提下提升模型性能,显著超越现有 SOTA。
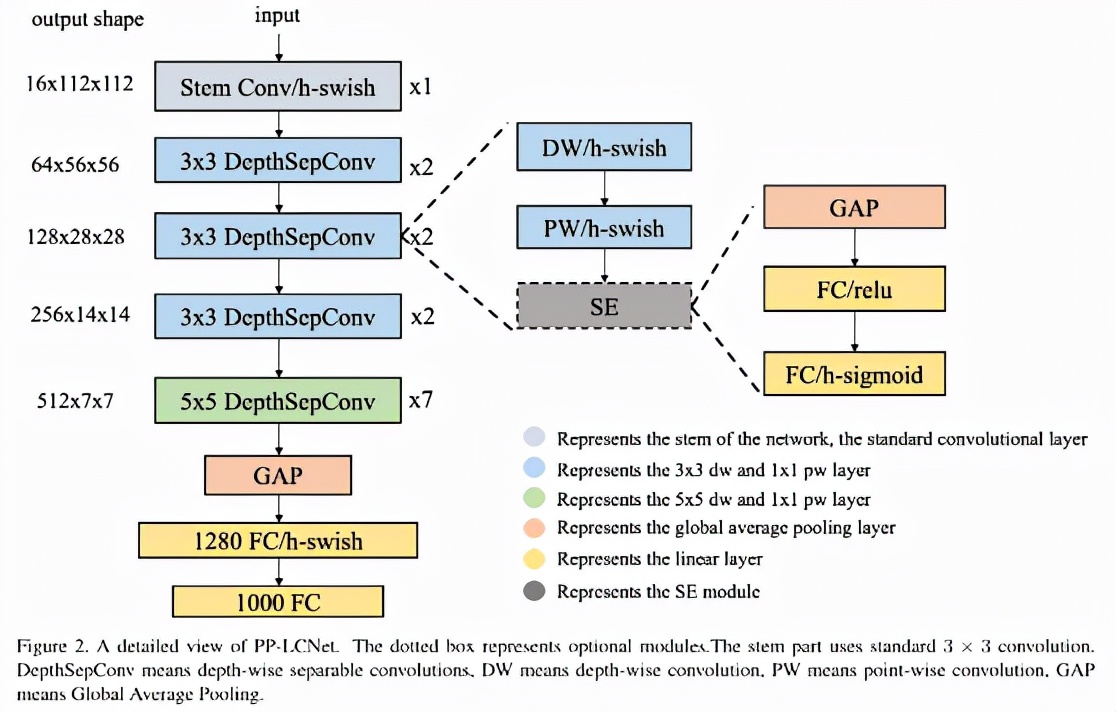
PP-LCNet 的网络结构在图中有所展示。研究发现,在基于 Intel CPU 的设备上,启用 MKLDNN 加速库后,某些看似无关紧要的操作(如 eleMentwise-add、split-concat 结构等)会带来额外延时。因此,设计时优先采用结构尽量简洁、速度尽量快的 BaseNet(类似 MobileNetV1)。在此基础上,通过大量实验总结出四条几乎不增加延时却能提升精度的方法,以下逐条介绍。
更好的激活函数
自引入 ReLU 以来,卷积网络性能显著提升。其变体如 Leaky-ReLU、P-ReLU、ELU 也相继出现。2017 年 Google Brain 的 swish 激活函数在轻量网络上表现出色,后续在 MobileNetV3 中优化为 H-Swish,以避免复杂指数运算,提升速度且对精度影响最小。大量实验证明,该激活函数在轻量网络上表现优异,因此在 PP-LCNet 中被选用。
合适的位置添加 SE 模块
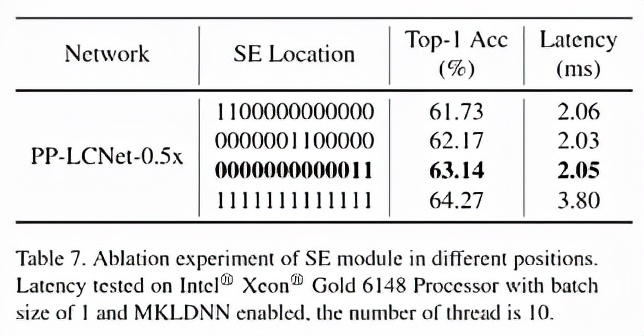
SE 模块作为通道注意力机制,能有效提升精度。但在 Intel CPU 上会带来额外延时。通过实验发现,SE 模块越靠近网络尾部,对精度的提升越明显。下表展示了相关实验结果,最终在 PP-LCNet 中采用了表格中第三行所示的位置方案。
更大的卷积核
MixNet 的研究显示,卷积核在一定范围内越大越有助于提升性能,但超过阈值则可能反而下降。因此,PP-LCNet 在中后部采用更大卷积核的位置,可以在不牺牲推理速度的前提下提升精度。最终选用表格中第三行的方案。

实验表明,更大的卷积核放在网络中后部即可达到在所有位置的类似效果,同时带来更快的推理速度。
GAP 后使用更大的 1×1 卷积层
在轻量网络中,GAP 后通常直接接分类层,可能导致特征在后续处理中的融合不足。引入一个更大的 1×1 卷积层(等同于全连接层)可在保持推理速度的同时,提升特征融合与分类效果,从而提升准确率。
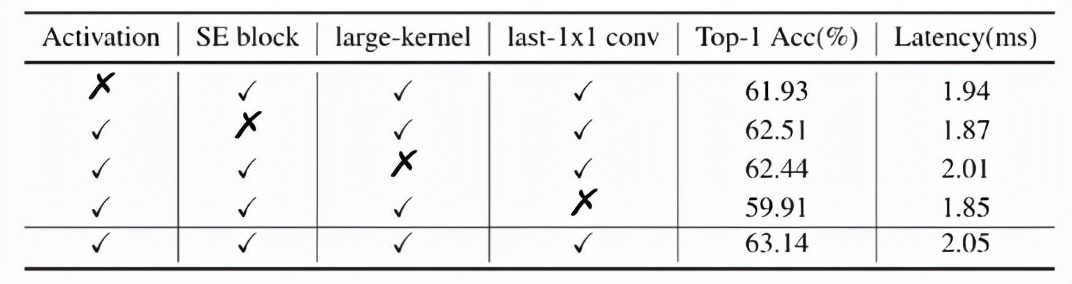
BaseNet 在以上四点的改进基础上形成 PP-LCNet。下表进一步说明了各方案对结果的影响:
下游任务性能提升显著
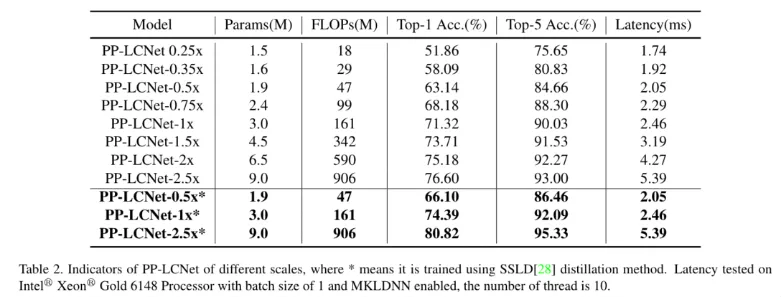
图像分类方面,我们选用了 ImageNet 数据集。相较于现有主流轻量网络,在相同精度下 PP-LCNet 提供更快的推理速度。结合自研蒸馏策略后,Intel CPU 端达到约 5Ms 推理速度时,Top-1 精度超过 80%!
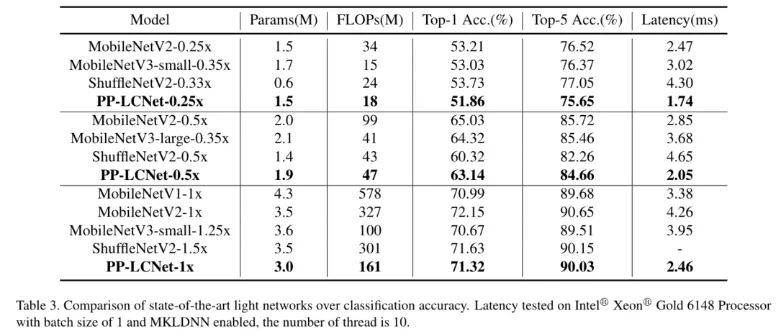
目标检测
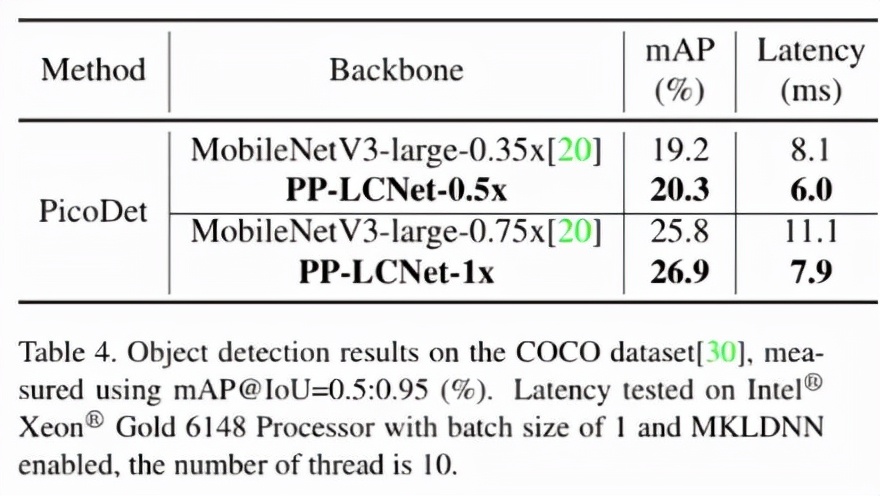
目标检测方面选用了轻量化的 PicoDet,展示了在 COCO 数据集上,基线为 MoBiLeNetV3 的对比。无论是精度还是速度,PP-LCNet 的优势都十分明显。
语义分割
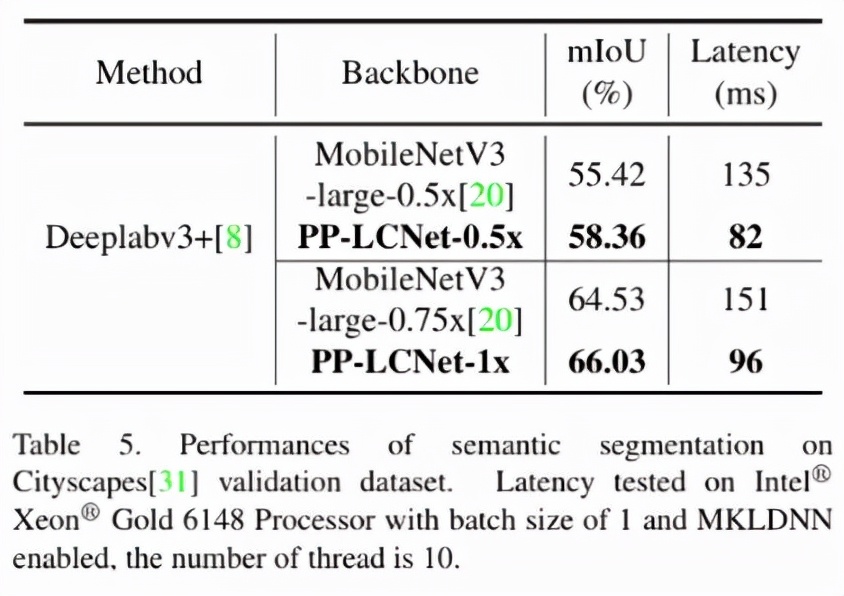
在 CITYScapes 数据集上,采用 PP-LCNet 作为骨干的 DeepLabV3+,同样在精度与速度上表现优异。
实际拓展应用结果说明
PP-LCNet 在实际场景下的表现同样出色。以 PP-OCR v2 为例,将识别模型骨干从 MoBiLeNetV3 替换为 PP-LCNet,速度提升的同时精度也有所提高。

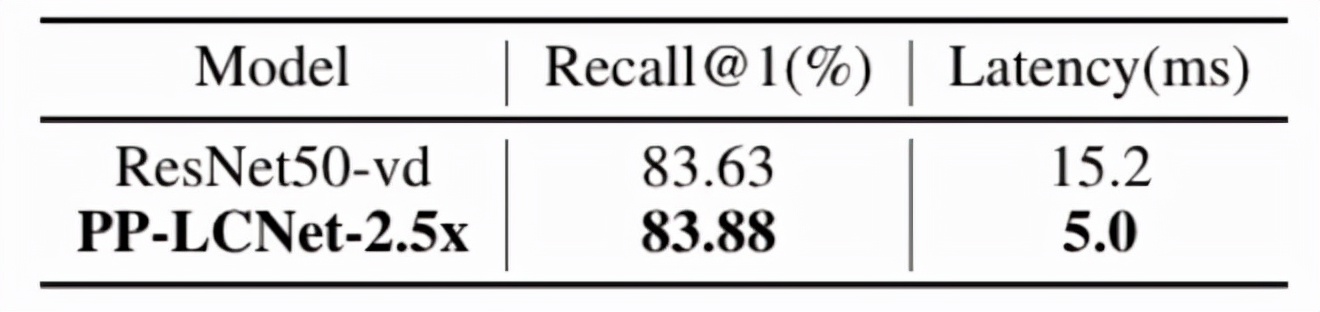
在 PP-ShITu 中,将 Backbone 的 ResNet50_vd 替换为 PP-LCNet-2.5x,在 Intel CPU 上实现约 3 倍提速,Recall@1 与 ResNet50_vd 基本持平。
PP-LCNet 的目标不是追求极致的 FLOPs,而是深入技术细节,研究如何在 Intel CPU 上加入友好的模块以提升性能,实现准确率与推理时间的平衡。实验结论对于其他网络结构设计者以及 NAS 研究者都具有参考价值。
自论文发布以来,PP-LCNet 在学术界和产业界引发广泛关注,相关的复现、应用与分析文章层出不穷。希望通过更实用的优化方案,将先进技术带进实际场景,提升“生活”的体验。
论文链接:https://aRxiv.oRg/pdf/2109.15099.pdf
该工作由相关开源社区与团队共同推动,旨在为工业界和学术界提供高效、易用的视觉模型开发工具,助力在实际场景中落地应用。
如需了解更多 PaddleClas 相关信息及教程,请访问:https://Github.coM/PaddlePaddle/PaddleClas