经过长时间对人工神经网络的研究,是否发现动物的神经系统提供了更有效的解决方案?
近期,关于摩尔定律逐渐失效的讨论频繁出现。随着深度学习对计算能力的不断攀升,芯片制造商们在更新换代方面的速度逐渐变得捉襟肘见,二者之间形成了难以调和的矛盾。在此背景下,一些研究团队专注于提升传统神经网络架构的效率,同时也有人将目光投向光电计算、类脑计算以及量子计算等新兴领域。
与此同时,有研究开始尝试从动物神经系统中寻找灵感。在2021年1月13日的顶级人工智能会议ICLR上,一篇引人关注的论文引发了热议:研究者们利用果蝇的大脑神经网络,尝试让其执行自然语言处理(NLP)任务,结果显示其性能与常规人工神经网络相当,并且能耗大幅降低。
这一创新尝试似乎为我们开启了新的思路大门。
在神经科学领域,果蝇大脑尤其是蘑菇体部分的研究颇为深入。蘑菇体可以分析气味、温度、湿度以及视觉信息,帮助果蝇区分友好与危险的刺激。神经科学家发现,果蝇大脑中的投射神经元将各种感觉信息传递给大约2000个Kenyon细胞,形成一个具有学习能力的神经网络。这一机制使果蝇能在接近食物或潜在伴侣时,学会避免危险的气味或高温等有害刺激。
如此规模相对较小、功能丰富的神经网络,引发了科学家的好奇:是否可以对其进行重新编程,以完成其他任务?
在由伦斯勒理工学院与MIT-IBM Watson AI实验室合作进行的研究中,研究者成功将果蝇大脑的神经网络应用于自然语言处理任务。这是生物神经网络首次在此类任务中的“入侵”。研究结果显示,这种生物网络的表现与传统的人工学习模型持平,但所需的计算资源明显更少。
具体来说,研究团队首先用计算机模拟重建了蘑菇体内的神经连接网络,模拟了大量神经元将信息传递给2000个Kenyon细胞的过程。之后,团队训练该网络识别文本中的词间关系。其核心思想是:词汇可以通过上下文或邻近词的出现频率来表示。研究从大规模语料库出发,分析每个词在句中的上下文,训练网络预测下一个词,从而学习词的语义特征。这种方法在自然语言生成中被广泛采用,研究也验证了即使是非人为进化而来的生物神经网络,也能在此任务中表现出色,学习到丰富的语义信息。
研究团队强调,果蝇大脑网络在性能上可媲美现有的自然语言处理方法,更重要的是,它们仅需极少的计算资源。这意味着训练时间和内存消耗都大大降低,为未来的低能耗AI系统提供了新的可能性。
生物启发的高效性
这一发现令人振奋。“我们认为,这证明了生物启发算法具有广泛的适用性,其效率优于传统非生物算法。”论文的主要作者之一如是说。
除了展示自然界神经网络的潜力外,研究还引发了关于为何生物神经系统如此高效的思考。自然选择无疑倾向于优化能量利用率,但目前尚未完全理解为何果蝇的Kenyon细胞在处理复杂任务时如此高效。
这项工作也为未来“入侵”更复杂动物脑结构提供了启示。然而,考虑到哺乳动物大脑的复杂性,目前科学界仍面临巨大挑战。例如,果蝇的大脑只有约10万个神经元,而哺乳动物如老鼠拥有上亿个神经元,人类则多达百亿级别。在深入研究更复杂的脑结构之前,还需等待技术的进步。
研究背景
论文题目:Can a FRuIT Fly LeaRn WoRd EMbeddings?

果蝇的蘑菇体是神经科学研究的重点之一,其核心由一群Kenyon细胞组成。这些细胞接受多感官输入,包括嗅觉、温度、湿度和视觉信号,经过与抑制性神经元(如GABA能神经元)相互作用,形成稀疏且高维的输入表征。
具体而言,蘑菇体主要处理嗅觉信息,但也接受温度、湿度和视觉感官神经元的输入。这些信息通过突触传递给大约2000个Kenyon细胞,Kenyon细胞之间通过抑制性神经元(如APL神经元)相互连接,形成“赢家通吃”的网络机制,使得部分“冠军”神经元激活,其他神经元则处于抑制状态,从而增强信息的稀疏表达。
在这项研究中,科学家们将该网络模型进行了数学建模,并应用于自然语言处理中的词与上下文关系学习。研究中,模型架构如图1所示,Kenyon细胞的输出会发送到蘑菇体的输出神经元(MBON),但此部分未在模型中具体表现。
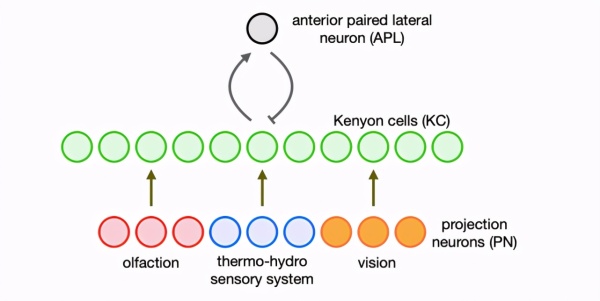
图1:神经网络结构示意图。不同类型的神经元通过活动信号输入到Kenyon细胞层,Kenyon细胞再通过与抑制性神经元的连接,形成稀疏激活状态。
研究主要贡献包括:
- 借鉴果蝇神经网络,提出一种算法,使得可以为词汇及其上下文生成二元(BInaRy)词嵌入,并在词汇相似性、词义消歧和文本分类等任务中验证其效果;
- 与传统连续词向量(如GloVe)相比,所提出的二元嵌入能形成更紧凑、更具区分度的概念集群,且符合二元化的集群特性;
- 训练该网络所需的计算时间比传统NLP模型少一个数量级,但在分类准确率方面略有下降。
这些成果展示了通过“重新编程”自然界中的算法与行为,将生物原型转化为解决实际任务的潜力。
实验评估
在论文的第三章,研究团队从静态词嵌入、词聚类、上下文相关词嵌入及文本分类等方面对模型进行了测试,以下为部分结果:
静态词嵌入评估:
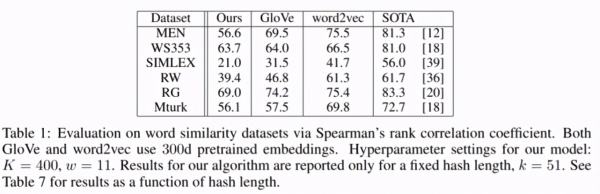
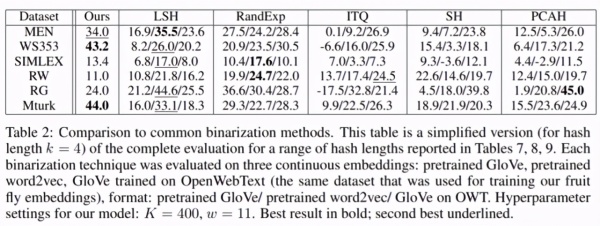
词聚类表现:
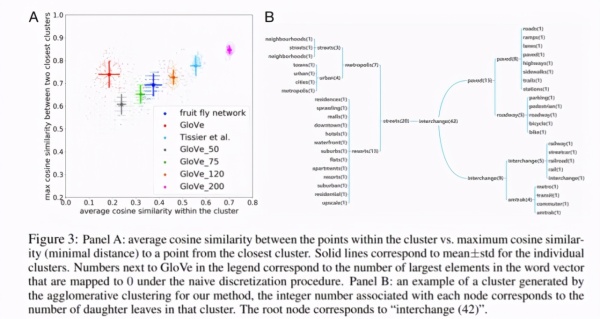
上下文相关词嵌入效果:

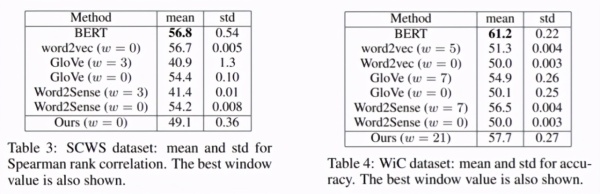
文本分类性能:
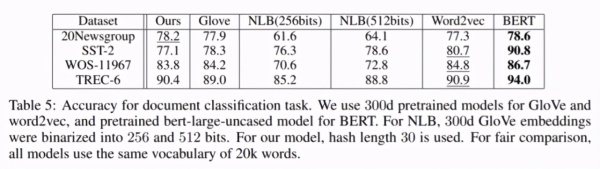
计算效率方面:
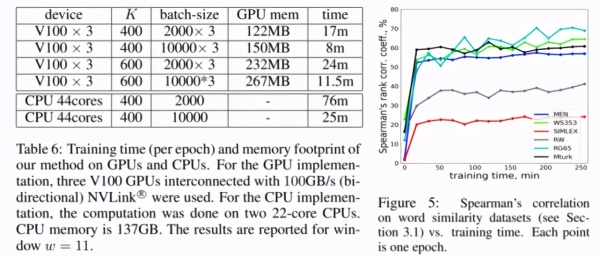
论文作者简介
本文第一作者为Yuchen Liang,毕业于浙江大学,后在哥伦比亚大学获得硕士学位,目前在美国伦斯勒理工学院攻读博士。研究兴趣涵盖数据挖掘与机器学习技术。
