研究显示,通过在每个视频帧中引入被称为对抗性样本的输入,Deepfake探测器可以被轻易击败。对抗性样本是经过轻微操控的输入,这些样本能够使人工智能系统,包括机器学习模型,产生错误判断。此外,研究团队还发现,即使在视频经过压缩的情况下,这种攻击依然有效。
来自加州大学圣迭戈分校计算机工程专业的博士生Shehzeen HuSSAIn表示:
我们的研究揭示了对Deepfake探测器的攻击可能对现实世界构成威胁,更加令人震惊的是,我们证明了即使不掌握探测器所使用的机器学习模型的具体运作原理,也能生成高度有效的对抗性样本。

在Deepfake技术中,主体的面部被修改,以制造出看似真实却根本没有发生过的事件镜头。
因此,传统的Deepfake探测器通常将重点放在视频中的人脸上:首先追踪人脸,然后将裁剪后的人脸数据传递给神经网络,由其判断这些人脸的真实性。
例如,眨眼在Deepfake中往往无法被精确复制,因此探测器会特别关注眼睛的运动,以此来识别虚假内容。最先进的Deepfake探测器依赖机器学习模型来甄别假视频。
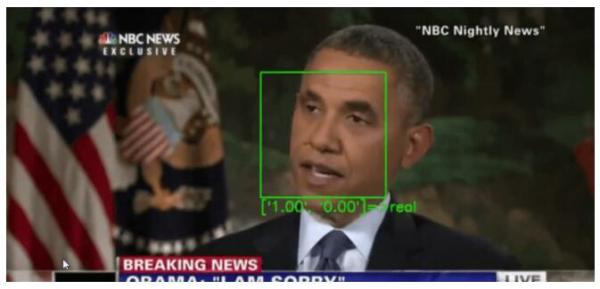
研究人员指出,虚假视频在社交媒体平台上的广泛传播已经引发了全球范围内的广泛关注,尤其是对媒体可信度的影响。
研究团队为视频中的每一张面孔创建了对抗性样本。尽管标准操作如视频压缩和调整大小通常会去除对抗性样本,这些样本却经过设计,能够承受这些处理。
攻击算法通过估算一组输入转换来实现这一目标,模型将图像分为真或假。随后,它利用这种估算来转换图像,使得即使在压缩和解压缩后,对抗性图像依然有效。
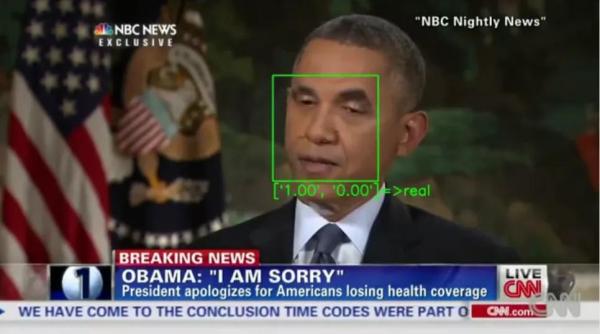
XceptionNet,一个Deepfake探测器,将研究人员制作的对抗性视频标记为真实。
将经过修改的面孔插入到每个视频帧中,然后对视频中的所有帧重复这一过程,从而生成Deepfake视频。这种攻击不仅可以针对面部,还可以针对整个视频帧进行操作。
成功率极高
研究人员在两个场景下测试了他们的攻击:在第一个场景中,攻击者可以完全访问探测器模型,包括人脸提取管道和分类模型的结构与参数;在第二个场景中,攻击者只能查询机器学习模型,以计算每帧被分类为真或假的概率。
在第一种情况下,对未压缩视频的攻击成功率超过99%。对于压缩视频,这一比例为84.96%。在第二种情况下,未压缩视频攻击的成功率为86.43%,而压缩视频的成功率为78.33%。
这是首次展示能够成功攻击最先进Deepfake探测器的研究成果。

为了提升探测器的效果,研究人员建议采用一种类似对抗性训练的方法:在训练过程中,一个适应性的对手持续生成新的Deepfake内容,这些内容可以绕过当前最先进的探测器;探测器则不断改进,以应对新的Deepfake结果。
