Hadoop发展历程
Hadoop是由Doug Cutting于2005年创建的,目的是为了应对大数据时代的数据存储与处理挑战。

随着大数据的迅猛发展,传统的数据存储和分析方法已无法满足需求。Hadoop应运而生,旨在解决海量数据的存储、分析和处理问题。其设计理念主要受到Google的三项技术的启发:第一是GFS(Google文件系统),第二是MapReduce,第三是BigTable。
Hadoop的核心组件包括HDFS(Hadoop分布式文件系统)和MapReduce计算框架。HDFS提供了高容错性和高吞吐量,而MapReduce则负责数据的并行处理。
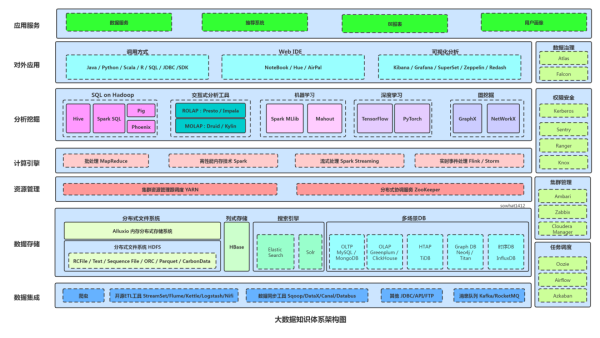
Hadoop生态系统是一个广泛的概念,涵盖了多种工具和技术,为大数据处理提供了一整套解决方案。
Hadoop的特点主要包括:
- 高可扩展性:可以通过增加节点来扩展处理能力。
- 高容错性:即使部分节点出现故障,数据依然安全。
- 高吞吐量:适合处理大规模数据集。
- 低成本:基于廉价的硬件进行部署。
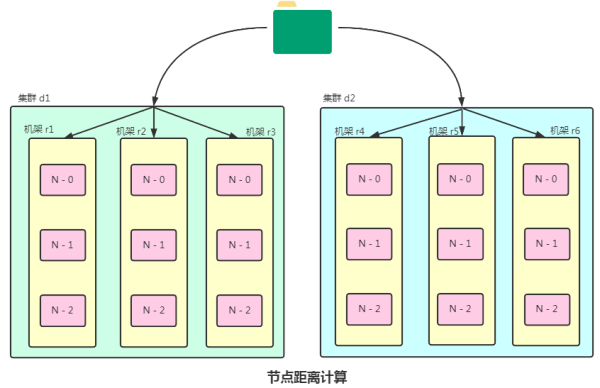
在Hadoop的设计中,数据以块的形式存储,并通过副本机制来保证数据的安全性。即便有节点宕机,数据也能通过其他副本进行恢复,确保数据不丢失。
Hadoop的底层架构使得同一数据的多个副本可以被维护,保证了系统的高容错性。即使某个计算节点出现问题,Hadoop依然能够通过其他节点继续运行。
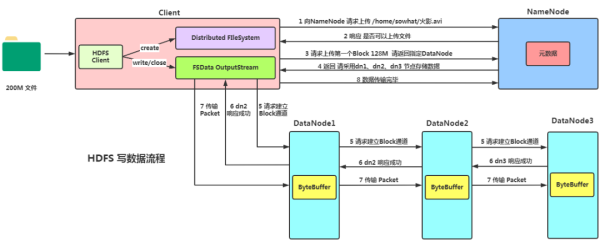
HDFS是Hadoop的核心组件之一,提供了一个分布式文件系统,支持大规模数据的存储。它具有高容错性,并能够在廉价的硬件上部署。
MapReduce是Hadoop的计算模型,包含两个主要步骤:Map和Reduce。Map阶段将输入数据分解为多个任务,Reduce阶段则对结果进行合并和汇总。
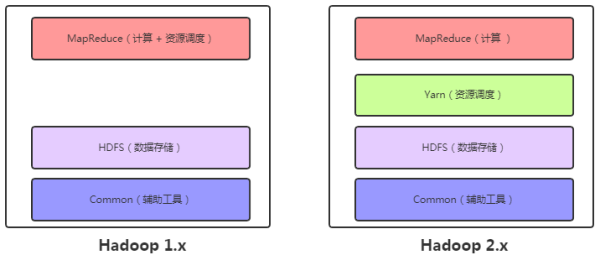
Hadoop的版本演变中,1.x与2.x之间的差异显著,有效提高了任务的管理和资源的调度能力。

在Hadoop的生态系统中,各个组件相互协作,共同为数据处理提供了强大的支持。
Hadoop的应用场景广泛,包括数据仓库、数据分析、机器学习等,已成为大数据处理的标准工具。
随着技术的不断发展,Hadoop也在不断演进,支持更复杂的数据处理任务,满足不断变化的业务需求。
总之,Hadoop的发展历程是对大数据挑战的积极应对,其架构的灵活性与可扩展性,使其在数据处理领域占据了重要地位。