前言
在Hadoop初期,HDFS未能有效解决单点故障问题,导致NaMEnode服务器宕机时整个集群都会受到影响,这显然是个严重的风险。为了应对这一挑战,Hadoop在不断更新中引入了Hadoop HA(高可用性)来处理NaMEnode的单点故障问题。接下来,我们来探讨几种解决方案。
解决HDFS单点故障的方法可以通过部署两个NaMEnode来实现,尽管实际上对外提供服务的只有一个。然而,这两个NaMEnode之间的元数据信息是否需要共享?如果其中一个NaMEnode宕机,且元数据信息没有同步,那么将会出现问题。
目前,有三种主要的解决方案如下:
方案一、目录共享
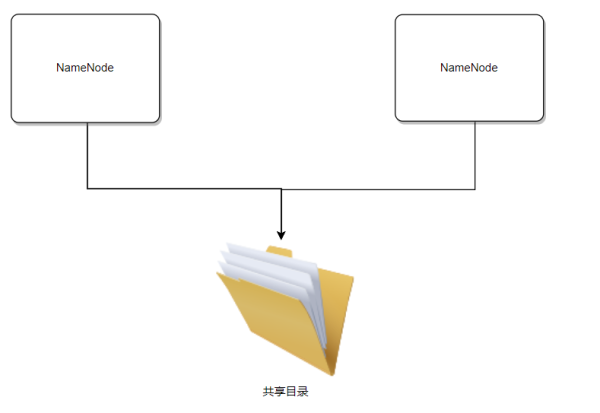
目录共享是社区提出的一个方案,但目前尚未被广泛采用。因为如果目录共享出现问题,则可能导致HDFS也随之故障,因此一些企业选择了放弃这一方案。
方案二、使用JouRnalNode方案
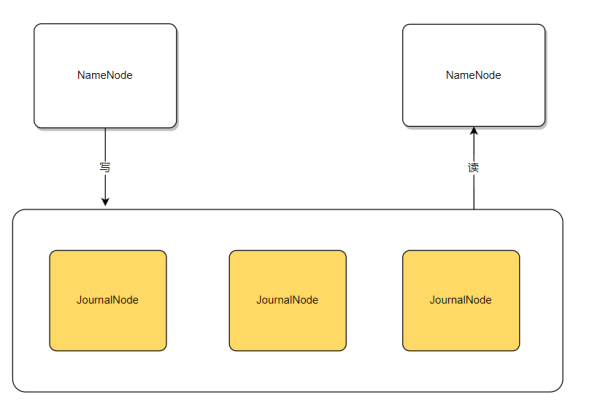
通过使用JN来保存元数据信息,可以避免单点故障的风险。JN本身是一个集群,通常会部署3、5、7或9个节点。JN的工作原理是,只要存活的节点数量超过一半,就能保持正常服务。
需要注意的是,选择的组件若本身存在单点故障,那么根本问题仍未解决。
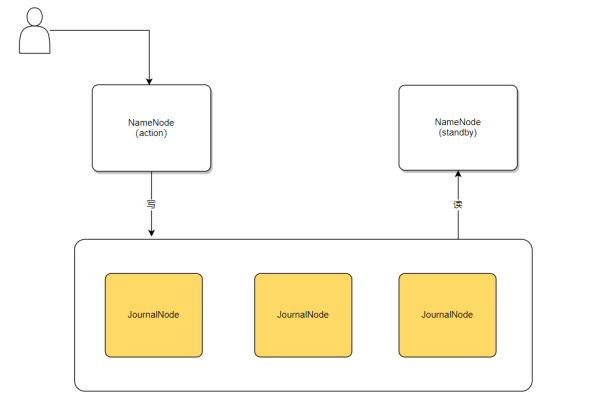
实际上,NaMEnode也有不同的角色,其中一个作为active节点提供服务,而另一个则为standby。在高可用架构中,只有一个NaMEnode对外服务,用户只能与active的NaMEnode进行交互。可以类比为在工作中,如果有两个平级领导,其中一位同意请假而另一位不同意,那么请假请求将无法明确决策,这就导致了混乱。因此,在高可用架构中,必须有一个明确的决策者。
方案三、使用zookeepeR方案
许多企业选择使用zookeepeR来解决单点故障问题。我们可以思考一下,JN主要解决了数据一致性和单点故障的问题,而zookeepeR同样具备相关功能。因此,一些企业对zookeepeR的源码进行了修改,从而采用了这一方案。
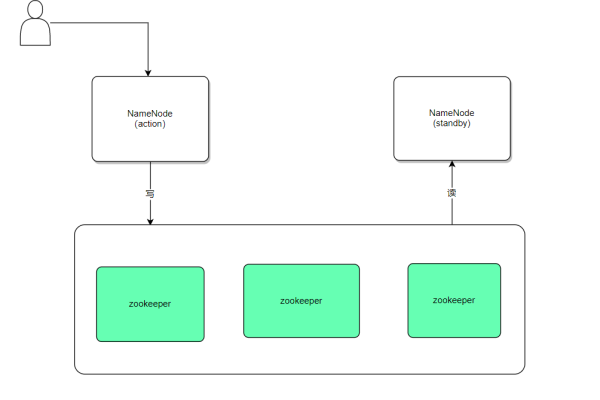
总体架构
以上方案是否能够有效解决NaMEnode的单点故障问题?假设在凌晨时分,active的NaMEnode宕机,我们是否需要人工干预进行切换?如果切换不及时,就可能导致整个集群不可用。因此,接下来我们将实现自动切换功能。
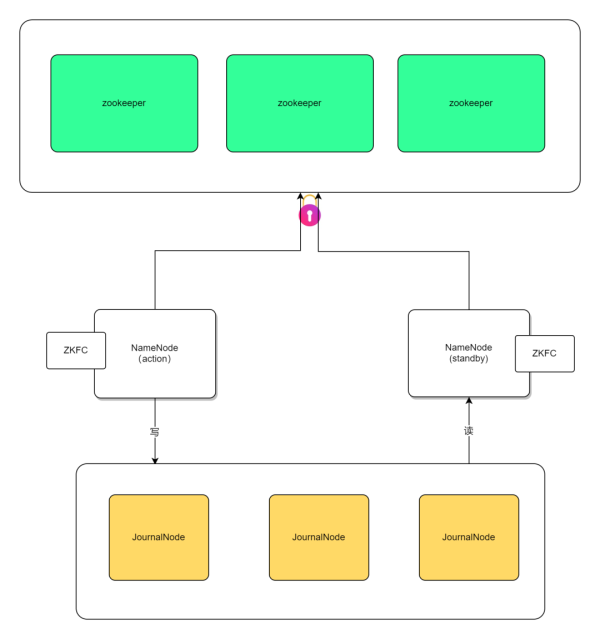
当两个NaMEnode成功启动后,它们会向zookeepeR注册。zookeepeR中会存在一把锁,注册成功的NaMEnode将成为active节点,而其他NaMEnode在注册时发现已经被占用,则会变为standby状态。
每个NaMEnode都部署了ZKFC来监控NaMEnode的状态。当active的NaMEnode发生故障时,ActionZKF会通过zookeepeR删除临时的zNode(释放锁)。处于standby状态的ZKFC会订阅这个临时zNode的变化,一旦zNode消失,standby状态的ZKFC会立即通过standby NaMEnode接管。StandBy NaMEnode会远程登录到active NaMEnode并执行kill-9命令以终止其运行,然后通知StandBy ZKFC向zookeepeR注册新的zNode,注册成功后转换为active状态。这样就实现了自动切换。
小结
本文介绍了几种解决HDFS单点故障的方法,希望大家能有所收获。如有疑问,请在下方留言或私信我,我将乐意为您解答。下期将分享关于NaMEnode内存受限的解决方案。此外,我还提供了一些大数据相关的资料(如企业面试题、简历模板等),需要的朋友可以前往我的GITHUB下载。相信自己,努力和汗水总会有回报。
