AutoML 概览

自动化机器学习(AutoML)可以自动执行数据预处理、编码、缩放、超参数优化、模型训练、产物生成及结果列表等流程,快速开发人工智能解决方案,提供友好体验,通常以低代码实现出结果。本质是通过自动化来提升建模效率与准确性。
市场上广泛使用的 AutoML 库包括多种主流实现,本文将以成熟数据集为例,演示在无需深入分析细节的前提下,使用最小代码量构建并部署优化后的机器学习模型。
项目背景与数据集
本教程选用公开数据集进行二分类任务,预测个人年收入是否超过 5 万美元。数据来源为公开的人口普查数据,适合作为入门示例。本文不深入讲解数据分析或模型原理,而是展示如何用几行代码构建优化模型,并通过 API 提供服务访问。
AutoXGB 概览
AutoXGB 是一个开源、易用且高效的 AutoML 辅助开发工具,支持直接从 CSV 训练表格化数据集的模型。它基于 XGBoost 进行模型训练,利用 Optuna 进行超参数优化,并通过基于 Python 的 FastAPI 提供模型推理的 API 服务。
安装与准备
接下来从安装开始,如在运行服务器时遇到错误,请确保已正确安装 FastAPI 框架及相关服务器组件。安装命令示例如下:
pip install autoxgb
初始化
接下来介绍 AutoXGB 的常用特性及参数,帮助提升计算结果或缩短训练时间。参数含义如下:
train_filename:训练数据的路径;output:产物输出文件夹路径;test_filename:测试数据路径。若未指定,则仅保存折外预测(OOF 预测)。task:若未指定,系统将自动推断任务类型。取值可为:
1. “Classification”
2. “Regression”
idx:未指定时,系统会自动生成 id 列。Targets:未指定时,默认目标列名为 target,并将问题视为二分类、多类分类或单列回归之一。可指定为:
1. [“target”]
2. [“target1”, “target2”]
features:未指定时,默认使用除 id、Targets、以及折叠列之外的所有列。示例:
features = [“col1”, “col2”]
categorical_features:未指定时将自动推断分类列。示例:
categorical_features = [“col1”, “col2”]
use_gpu:未指定时默认为 False,即不启用 GPU;可设置为 True/False。
num_folds:交叉验证的折数;seed:随机种子;num_trials:Optuna 的试验次数,默认 1000;time_limit:Optuna 时间限制(秒)。若未指定,默认将运行所有尝试,time_limit 为 None。
Fast:若设为 True,超参数搜索将仅进行一次,随后在剩余折叠部分完成训练并生成 OOF 与测试预测。
在示例项目中,除了 train_filename、output、target、num_folds、seed、num_trials 与 time_limit 外,其余参数采用默认值。参数配置如下:
from autoxgb import AutoXGB
train_filename = “Binary_classification.csv”
output = “output”
test_filename = None
task = None
idx = None
targets = [“income”]
features = None
categorical_features = None
use_gpu = False
num_folds = 5
seed = 42
num_trials = 100
time_limit = 360
Fast = False
训练与优化
现阶段,可以通过定义模型并将上述参数传入来启动训练。随后调用 axgb.train() 即可进入训练过程,XGBoost 与 Optuna 将协同工作,输出包括模型、预测、结果、配置及编码器等产物。
示例:创建并训练模型
axgb = AutoXGB(
train_filename = train_filename,
output = output,
test_filename = test_filename,
task = task,
idx = idx,
targets = targets,
features = features,
categorical_features = categorical_features,
use_gpu = use_gpu,
num_folds = num_folds,
seed = seed,
num_trials = num_trials,
time_limit = time_limit,
Fast = Fast,
)
axgb.train()
训练耗时通常在数分钟内完成,最佳结果可通过延长时间限制或调整超参数进一步提升。
日志与结果
训练过程中的关键指标将输出如下信息,包含 AUC、Log Loss、F1、Accuracy、Precision、Recall 等指标的初步结果。通过命令行也可查看训练详情。
示例输出片段:
Metrics: AUC: 0.852, logloss: 0.387, f1: 0.535, accuracy: 0.823
CLI 使用示例
若希望通过命令行在 Bash 终端训练模型,只需指定 train_filename 与 output 即可。命令示例:
autoxgb train –train_filename Binary_classification.csv –output output
Web API 部署
通过设置模型路径、端口等参数即可在本地部署 FastAPI 服务器。示例参数如下:
Model_path:模型文件路径,本文示例指向输出文件夹;Port:服务器端口,默认为 8080;host:服务器主机地址;workers:并发工作线程数;debug:是否开启调试日志。
云端部署示例:Deepnote 通过 ngrok 提供公开 URL;本地部署也可直接使用 http://0.0.0.0:8080/。
API 服务参数示例
Model_path:/path/to/output;host:0.0.0.0;port:8080;debug:True
另外,我们提供了运行服务器所需的模型路径、主机地址与端口信息。
命令示例:
autoxgb serve –Model_path /path/to/output –host 0.0.0.0 –port 8080 –debug
结果与体验
运行结果显示 API 稳定工作,可通过 Web 浏览器或客户端发送请求并获得响应数据。实际演示地址以环境为准,读者可参考文档中的示例接口。
INFO: Watching directories: [‘/work’]
INFO: Uvicorn running at http://0.0.0.0:8080
示例输入与预测
我们可以输入随机样本来预测某人年收入是否超过 5 万美元。示例页面提供了交互界面,便于查看预测结果。
输入数据
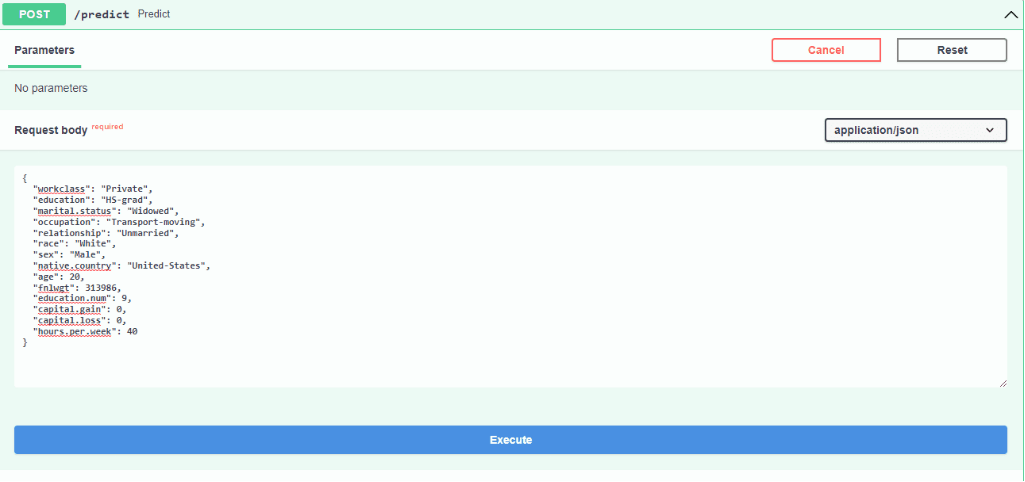
测试结果
示例结果显示:低于 5 万美元的置信度约为 97.6%,高于 5 万美元的置信度约为 2.4%。

使用 requests 进行 API 测试
也可在 Python 中使用 requests 库进行接口测试。将参数以字典形式发送,即可获得 JSON 结果。
示例:
import requests
params = {
“workclass”: “Private”,
“education”: “HS-grad”,
“marital-status”: “Widowed”,
“occupation”: “Transport-moving”,
“relationship”: “Married-csp”,
“race”: “White”,
“sex”: “Male”,
“native-country”: “United-States”,
“age”: 20,
“fnlwgt”: 313986,
“education-num”: 9,
“capital-gain”: 0,
“capital-loss”: 0,
“hours-per-week”: 40,
}
response = requests.post(“http://your-api-host/predict”, json=params)
data = response.json()
print(data)
该示例将返回类似 {“id”: 0, “≤50K”: 0.976, “>50K”: 0.024} 的预测结果。
项目源码与后续
若对本文所述代码及示例感兴趣,可参考以下要点:通过 AutoXGB 实现数据预处理、XGBoost 模型训练、Optuna 超参优化,以及 FastAPI 服务部署,能够为日常表格数据问题提供端到端解决方案。
总结
本教程展示了如何借助 AutoXGB,在最小配置下快速构建并部署一个可用的 AutoML 服务。通过端到端的流程,涵盖数据准备、模型训练、超参优化与 API 服务化,帮助读者在实际项目中实现高效的表格数据问题解决方案。
