本文提出了一种针对3D点云的无监督胶囊网络架构,展示了在3D点云重构、配准和无监督分类领域超越当前最佳方法的能力。
对象理解是计算机视觉中的关键任务之一。传统方法依赖于大量带注释的数据集来完成这项任务,而无监督方法则消除了对标签的需求。近期,有研究者尝试将这些无监督方法扩展至3D点云问题,但在无监督3D学习方面的进展仍然有限。
最近,来自英属哥伦比亚大学、谷歌研究院和多伦多大学的研究团队,包括Weiwei Sun、AndRea Tagliasacchi和Geoffrey Hinton,提出了一种无监督胶囊网络用于3D点云。Hinton指出,发现对象的自然组件及其内在参考系是将解析图像转换为局部整体层级结构的重要步骤,这一过程可以从点云开始。
具体而言,研究团队通过排列等变注意力机制对对象进行胶囊分解,并通过训练成对的随机旋转对象自我监督这一过程。该研究的核心思想是将注意力掩模聚合为语义关键点,并利用这些关键点来监督满足胶囊不变性或等方差的分解。这样的方式不仅可以训练出语义一致的分解,还能学习以对象为中心的推理规范化操作,且无需分类标签或手动对齐的训练数据集。
最终,通过无监督方式学习以对象为中心的表征,该方法在3D点云重构、配准和无监督分类方面超越了现有最佳方法。研究团队表示将很快发布源代码和数据集。

论文链接:https://aRxiv.oRg/abs/2012.04718
项目主页:https://canonical-capsules.Github.io/
方法
该网络在未对齐的点云上进行训练,如下图所示:研究者训练了一个能够将点云分解为多个组件的网络,并通过Siamese训练设置实现了不变性和等方差。
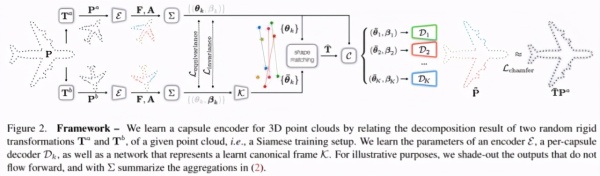
接着,研究团队将点云规范化为学习的参考系,并在该坐标空间中进行自动编码。
损失
与许多无监督方法相似,本研究的框架依赖于多个损失函数,这些损失函数控制着在表征中获取的不同特征。值得注意的是,这些损失函数都是无监督且不需要标签的。研究者根据他们监督的网络部分组织了损失,包括分解、规范化和重建。
网络架构
研究团队简要介绍了实现的细节,包括网络架构:
编码器E。我们的架构基于类似于点网的设计,具有残差连接和注意力上下文归一化;解码器D。公式中的解码器基于每个胶囊进行运算。本研究采用的解码器架构类似于AtlasNetV2(带有可训练的网格),不同之处在于本研究通过相应的胶囊姿态转换每个胶囊的解码点云;
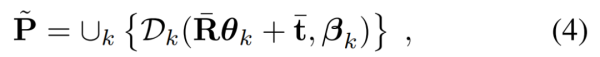
回归器K。研究者只需连接描述符,并通过ReLU激活函数调用一系列全连接层,以回归胶囊位置。在输出层,研究者使用线性激活函数,并进一步减去输出的平均值,以使回归位置在规范化框架中以零为中心;规范化描述符。由于本研究的描述符近似旋转不变(通过扩展),研究者发现,在规范化后重新提取胶囊描述符很有用。
实验及结果
自动编码
研究团队评估了在两个训练基线(单类别和多类别变体)下用于训练网络任务(重建/自动编码)的方法性能:
AtlasNetV2,一种基于补丁的多头解码器的现有最佳自动编码器;
3D-PointCapsNet,一种利用胶囊架构的3D点云自动编码器。
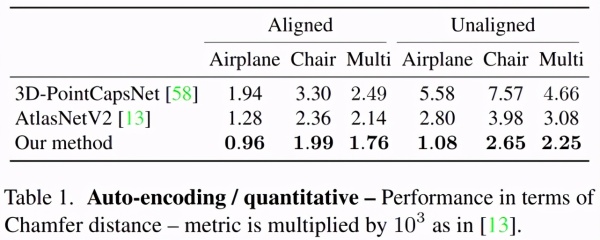
下表是定量分析结果,本文方法在对齐和未对齐的设置下均表现出现有最佳性能。
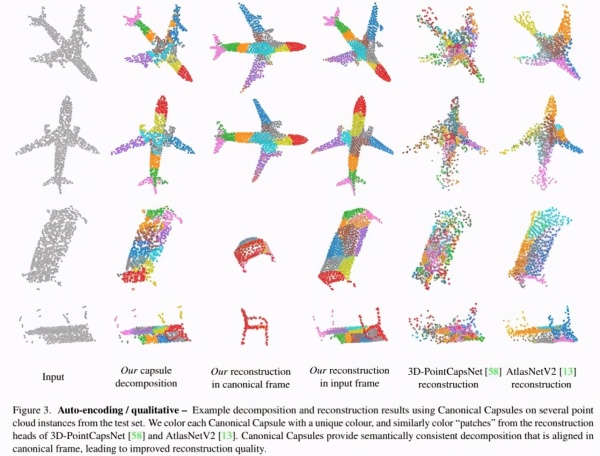
下图是定性分析结果,研究者展示了基于分解的3D点云重建方法以及与3D-PointCapsNet、AtlasNetV2的重建结果对比。
配准
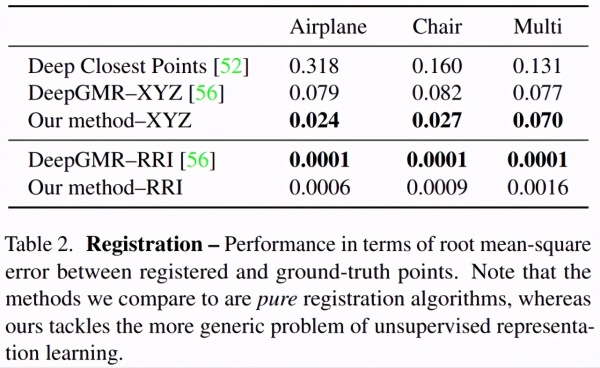
研究团队评估了该方法在3D点云配准方面的性能,并与以下三个基准进行比较:
Deep Closest Points(DCP):一种基于深度学习的点云配准方法;DeepGMR–RRI,一种现有最佳方法,能够将点云分解为具有旋转不变特征的高斯混合;DeepGMR–XYZ,其中使用原始XYZ坐标作为输入,而不使用旋转不变特征;
本研究采用的变体方法RRI,使用RRI特征作为该架构的唯一输入。本文使用RRI特征的方法遵循DeepGMR训练协议,训练了100个周期,而对于DCP和DeepGMR,本研究使用了原作者的官方实现。定量分析结果如下表所示:
无监督分类
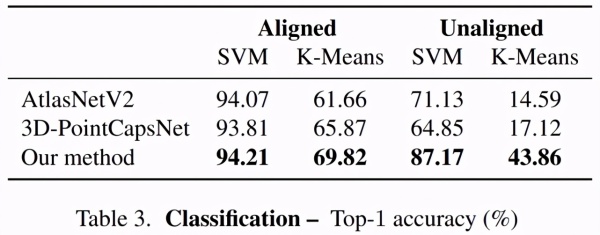
除了重建和配准(这两者与训练损失直接相关),本研究还通过分类任务评估了方法的有效性,结果显示该分类任务与训练损失无关。结果如下表所示,本文方法均实现了现有最佳的Top-1准确率。
控制变量实验
此外,为了进一步分析规范化胶囊不同组件对性能的影响,研究团队进行了系列控制变量实验,结果如下表所示:

表4:损失的影响。
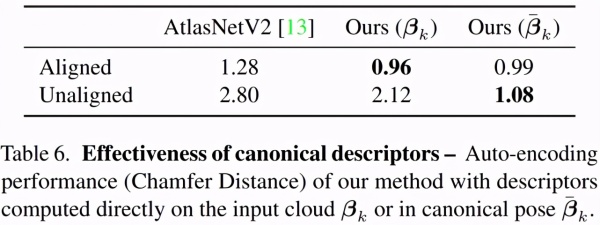
表6:规范描述符的有效性。
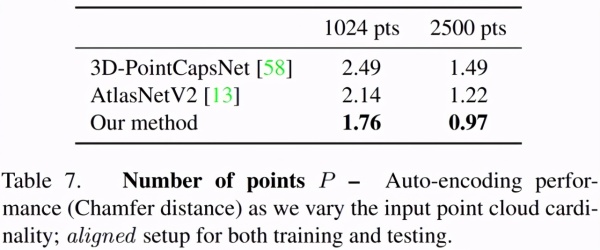
表7:点的数量对性能的影响。
