不必再担心图片搜索结果与预期不符,现在你可以尝试OpenAI最新技术CLIP带来的精准图片搜索。
只需简单的一句话描述,即可找到所需的图片。
例如,输入:
The woRd lOVe wRITten on the wall
你将会得到这样的结果:
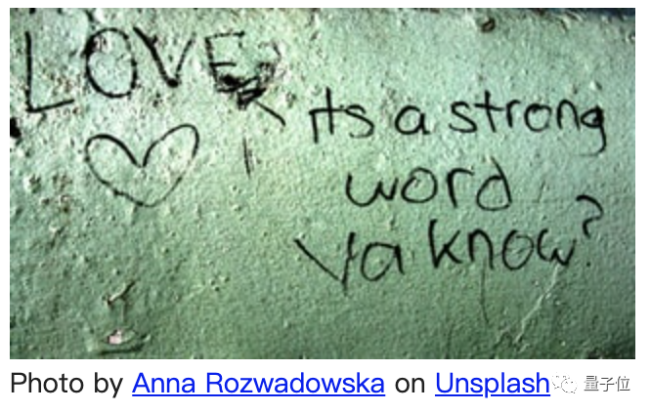
可以说这是相当精准的!这个项目最近在ReddIT上引起了热议。

CLIP是OpenAI最近推出的DALL·E中的核心模块,负责对生成的图片进行重排序。
这个项目使用谷歌Colab Notebook,在线且免费,包含多达200万张图片数据集,最引人注目的是它的精确效果。
网友们纷纷称赞“AMazing”。
简单几步,轻松实现在线精准搜图
该项目之所以如此火爆,简单的操作流程是一个重要原因。
首先,访问该项目在Colab Notebook中的链接(见文末链接),并登录你的账号。
环境配置、包或库的调用都已经为你准备好了,只需依次点击cell旁的小三角,等待运行完成即可。
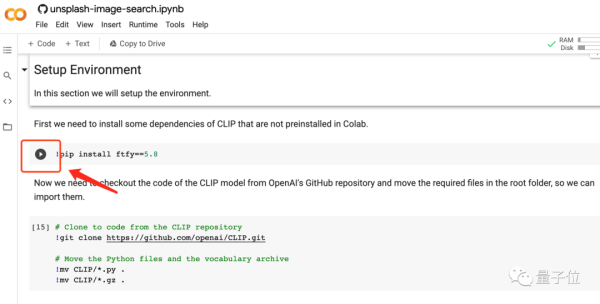
最后,找到包含以下代码的cell:
SeaRch_queRy = “Two dogs playing in the snow”
运行这个cell后,你就能得到搜索图片的结果,例如:


当然,程序似乎很懂人心,当输入“当你的代码成功运行时的情绪”:
The feeling when youR ProgRaM finally woRks
得到的结果,正和人们的预期一致:


为何CLIP能够如此精准地进行搜图?
OpenAI最近推出的DALL·E,主要功能是根据文字描述生成相应的图片。
而它呈现的最终作品,其实是从大量生成的图片中筛选而来。
这一过程中涉及到排名和评分的筛选工作,这正是CLIP的职责所在:
匹配度高、CLIP能够理解的图片会获得更高的分数,从而排名更靠前。

这种结构类似于利用生成对抗网络(GAN)合成图像。
但与通过GAN扩展图像分辨率或进行图像-文本特征匹配的方法不同,CLIP选择直接对输出进行排名。
研究人员指出,CLIP网络的最大意义在于,它解决了深度学习在视觉任务中面临的两个主要问题。
首先,它降低了深度学习所需的数据标注量。
与手动在imageNet上用文字描述1400万张图像不同,CLIP直接从网络上现有的“文字描述图像”数据中进行学习。

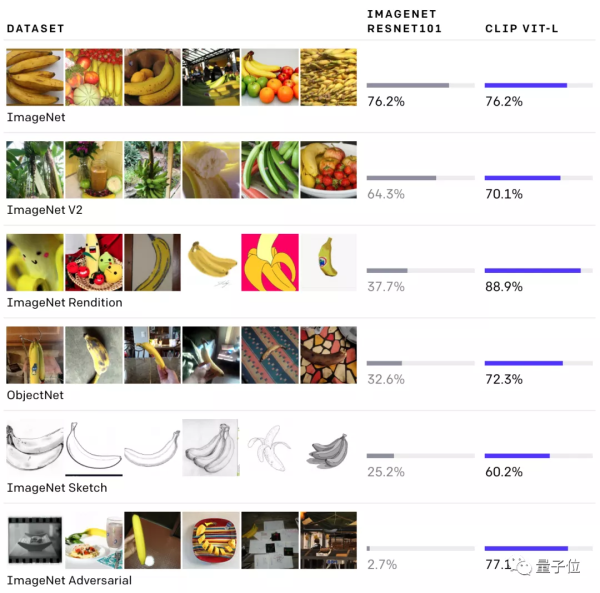
此外,CLIP还拥有多种能力,能够在各类数据集上表现出色。
而此前的大多数视觉神经网络仅能在训练集上取得良好表现。
例如,与ResNet101相比,CLIP在各数据集上均表现出色,而ResNet101在imageNet之外的检测精度则相对较差。
具体而言,CLIP运用了零样本学习、自然语言理解和多模态学习等技术来实现图像理解。

例如,描述一只斑马可以用“马的轮廓+虎的皮毛+熊猫的黑白”来表述。这样,网络能够从未见过的数据中找出“斑马”的图像。
最终,CLIP将文本和图像理解相结合,预测哪些图像与数据集中的文本能够达到最佳匹配。
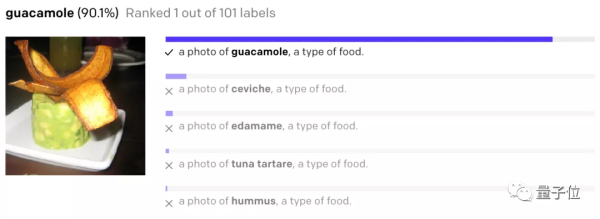
在惊叹CLIP用简单语言实现精准搜图效果的同时,一位ReddIT网友还发现了一个有趣的搜索结果。
他在文本描述的代码部分输入:
What image best RepResents how you feel Right now?
这句话在我们看来是询问AI的语气,然后出现的图片结果如下:

还有这样的:

