有人敢于挑战GPT-3的霸主地位!
自发布以来,GPT-3已成为最大的AI语言模型之一。
它不仅能够撰写电子邮件、文章,还能创建网站,甚至生成Python深度学习的代码。

最近,一个名为“侏罗纪”的模型声称能够超越GPT-3。
那么,这位勇者究竟是谁呢?
这并不是侏罗纪公园中的恐龙,而是JuRaSSic-1 JuMbo,一个尚在公测阶段的语言模型!
现在可以免费体验:
https://studio.AI21.coM/playgRound

除了能够将Python代码转换为JavaScript,这个语言模型还有何独特之处?
胆量与实力并存
在机器学习中,参数是模型的重要组成部分,源自历史训练数据。
通常在语言模型中,参数越多,模型的复杂程度也越高。
JuRaSSic-1 JuMbo模型的参数数量达到1780亿。
这比GPT-3多出整整30亿个参数!
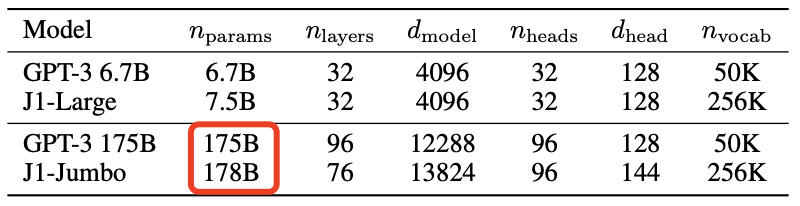
在词汇方面,GPT-3拥有50000个词汇。相比之下,JuRaSSic-1则能识别多达250000个表达式、单词和短语,覆盖范围超越绝大多数现有模型。
JuRaSSic-1模型通过云训练,依托数百个分布式GPU在公共服务上进行。
Token是一种将文本分割为更小单元的方法,可以是单词、字符或词的一部分。
JuRaSSic-1的训练数据集包含3000亿个Token,均来自维基百科、新闻出版物及StackExchange等英语网站。
模型训练采用传统的自监督和自回归方式,对3000亿个Token进行学习。
在优化程序方面,研究人员分别为J1-LaRge和J1-JuMbo设置了1.2&tiMes;10-4和0.6&tiMes;10-4的学习率,以及200万和320万个Token的批大小。
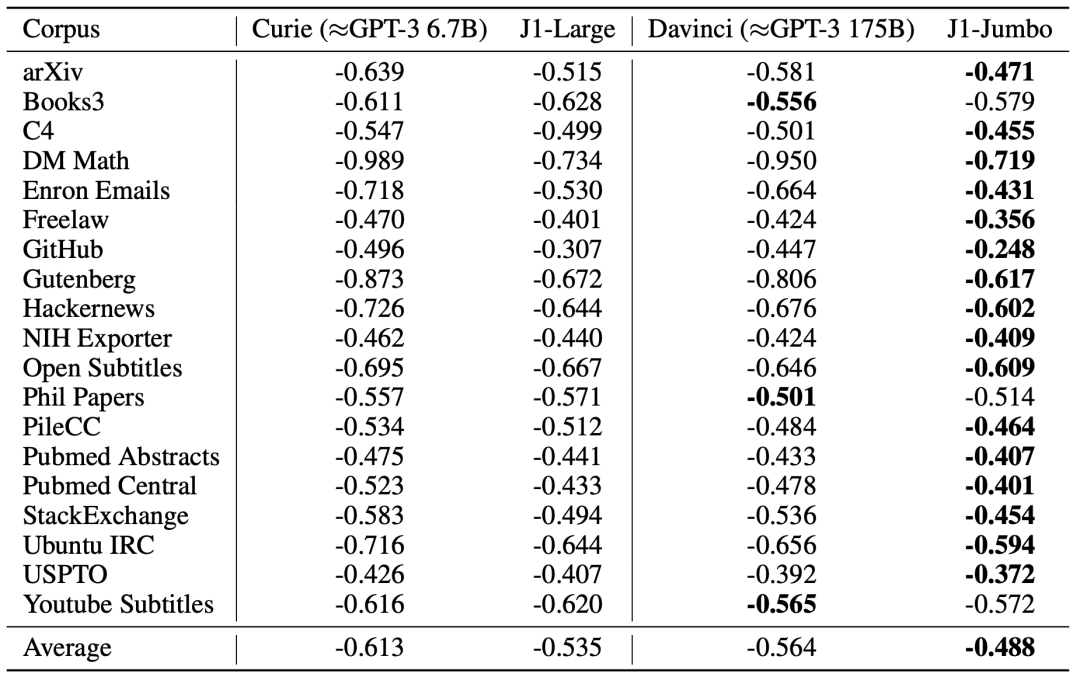
模型在不同领域的适用性由平均每字节对数概率表明。
研究人员表示,JuRaSSic-1模型在几乎所有语料库中都超越了GPT-3。
在小样本学习的测试中,两者各有胜负,但平均得分持平。

在基准测试中,JuRaSSic-1在回答学术和法律问题时的表现已与GPT-3相当,甚至更为出色。
GPT-3需要11个Token,而JuRaSSic-1仅需4个,大大提高了样本效率。
当然,逻辑和数学问题对语言模型来说一直是最大的挑战。
JuRaSSic-1 JuMbo已经能处理简单的算术问题,比如两个大数相加。

JuRaSSic能够解释单词的含义。
在众多语言模型中,JuRaSSic-1 JuMbo虽然是后起之秀,但并不算特别新颖。
不过,类似于它的前辈们,如果问题描述不清,生成的答案很可能并不符合预期。

堪称产品经理的终结者。
偏见甚至可能影响自身。
JuRaSSic-1模型由AI21 Labs开发,并通过AI21 Labs的Studio平台提供服务。
开发者可以在公测版中构建虚拟代理和聊天机器人等应用原型。
此外,JuRaSSic-1模型和Studio还支持释义和总结,例如从产品描述中生成简短的产品名称。

根据新闻内容进行分类。
开发者还可以训练自己的JuRaSSic-1模型,所需的训练实例仅需50-100个。
完成训练后,可以通过AI21 Studio使用该自定义模型。
然而,JuRaSSic-1同样面临其他语言模型的“痛点”:性别、种族和宗教的偏见。
由于训练数据集中不可避免地存在偏见,最终训练出的模型也会受到影响。
研究人员指出,GPT-3等类似语言模型生成的文本可能会激化极右翼的意识形态和行为。

JuRaSSic模型的输出面临预设场景的问题。
为此,AI21 Labs限制了公测中可生成的文本数量,计划手动审查每个微调模型。
然而,即便经过微调的模型,仍难以摆脱训练过程中“染上的恶习”。
就像OpenAI的Codex,仍可能生成种族主义或其他令人不悦的可执行代码。

虽然由以色列研究人员开发,但由于训练数据集的影响,JuRaSSic-1似乎对犹太人的歧视程度甚至高于GPT-3。
在偏见与歧视的问题上,各个模型之间并无太大区别。
不过,AI21 Labs的工程师表示,JuRaSSic-1模型的偏见程度相比GPT-3略低。
