近年来,多层感知机(MLP)在计算机视觉(CV)领域引起了广泛关注。谷歌、清华大学等研究机构相继提出了基于纯 MLP 的视觉架构和新的注意力机制,使得研究焦点再次转向 MLP。最近,FACEbook 发布了一种名为 ReSMLP 的纯 MLP 架构,该架构在图像分类任务中表现出色,尤其在采用现代训练方法时,在 imageNet 数据集上取得了良好的性能。
不久前,谷歌推出的 MLP-MixeR 在 CV 圈内引起了轰动。该架构无需卷积或注意力机制,仅依靠 MLP 即可与 CNN、VIT 等模型媲美。
同样,清华大学的 JITTor 团队提出了一种新型的注意力机制,称为「ExteRnal Attention」。这一机制基于两个小型的、可学习且共享的存储器,仅通过两个级联的线性层和归一化层替代了当前流行的「Self-attention」,揭示了线性层与注意力机制之间的关系。此外,清华大学的丁贵广团队将 MLP 作为卷积网络的通用组件,以实现多种任务性能的提升。
目前,MLP->CNN->TRansfoRMeR->MLP 的模式似乎已成为一种趋势。
近日,FACEbook 的研究者进一步推动了这一趋势,提出了 ReSMLP(Residual Multi-LayeR PeRceptRon),一种专门用于图像分类的纯多层感知机(MLP)架构。

该架构设计非常简洁:它将展平后的图像 patch 作为输入,经过线性层映射后,采用两个残差操作更新投影特征:(i)一个简单的线性 patch 交互层,适用于所有通道;(ii)一个独立于所有 patch 的 MLP,具有单一隐藏层。在网络末端,这些 patch 会被平均池化后输入到线性分类器中。
ReSMLP 的设计受到 VIT 的启发,但其结构更加简单:没有任何形式的注意力机制,仅包含线性层和 GELU 非线性激活函数。与 TRansfoRMeR 相比,该架构的训练更加稳定,不需要特定的批次或跨通道标准化(如 BATch-NoRM、 GRoupNoRM 或 LayeRNoRM)。训练过程基本遵循 DeIT 与 CAIT 的训练方法。
由于 ReSMLP 的线性特性,模型中的 patch 交互便于可视化和解释。尽管第一层学习到的交互模式与小型卷积滤波器相似,但在更深层中,研究者观察到了 patch 之间更为微妙的交互,包括某些形式的轴向滤波器(axial filteRs)以及网络早期的长期交互。
架构方法
ReSMLP 的具体架构如图 1 所示,采用了路径展平(flattening)结构:
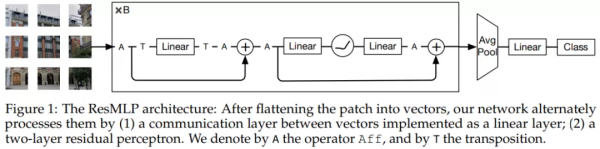
整体流程
ReSMLP 以 N&tiMes;N 的非重叠 patch 组成的网格作为输入,通常 N 为 16。然后,这些非重叠的 patch 通过一个线性层独立形成 N^2 个 d 维嵌入。接着,这些嵌入被送入一个残差 MLP 层序列,生成 N^2 个 d 维输出嵌入。最终,这些输出嵌入会被平均为一个代表图像的 d 维向量,随后输入到线性分类器以预测与图像相关的标签。训练过程中使用交叉熵损失。
残差多感知机层
网络序列中的每层均采用相同结构:线性子层 + 前馈子层。类似于 TRansfoRMeR 层,所有子层与跳远连接(skIP-connection)并行。研究者没有使用层归一化(LayeRNoRMalization),因为即使没有层归一化,采用公式(1)中的 AFFine 转换时,训练仍然稳定。
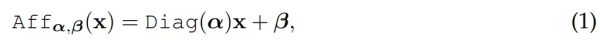
研究者为每个残差块使用了两次 AFFine 转换。作为预归一化,AFF 替代了层归一化,而不再使用通道级统计(channel-wise statistics)。在残差块后处理时,AFF 实现了层扩展(LayeRScale),因此可以在后归一化时采用与 [50] 中相同的小值初始化。这两种转换在推理时均整合至线性层。
另外,在前馈子层中采用与 TRansfoRMeR 相同的结构,并仅使用 GELU 函数替代 ReLU 非线性。
与 TRansfoRMeR 层的主要区别在于,研究者使用以下公式(2)中定义的线性交互替代自注意力:
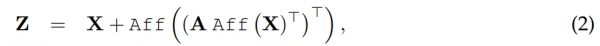
与 VIT 的关联
ReSMLP 是 VIT 模型的显著简化,但有以下几点不同:
ReSMLP 未采用任何自注意力块,使用的是非线性的线性 patch 交互层;没有额外的「类(claSS)」Token,而是仅使用平均池化;不采用任何形式的位置嵌入,因为 patch 之间的线性通信模块已考虑了 patch 的位置;不采用预层归一化,而是使用简单的可学习 AFFine 转换,从而避免了批和通道级统计。
实验结果
研究者在 imageNet-1k 数据集上训练了该模型,该数据集包含 120 万张图像,均匀分布在 1000 个类别中。他们进行了两种训练范式的实验:监督学习和知识蒸馏。
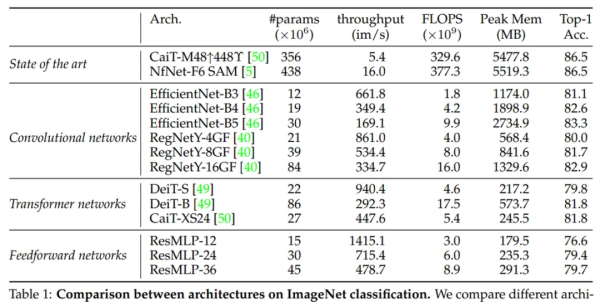
首先,研究者将 ReSMLP 与 TRansfoRMeR 和 convnet 在监督学习框架下进行了比较,如下表 1 所示,ReSMLP 取得了相对较好的 Top-1 准确率。
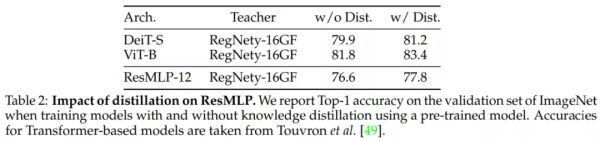
随后,为了提高模型的收敛性,研究者利用知识蒸馏,结果如下表 2 所示。与 DeIT 模型相似,ReSMLP 在 convnet 蒸馏中显著受益。
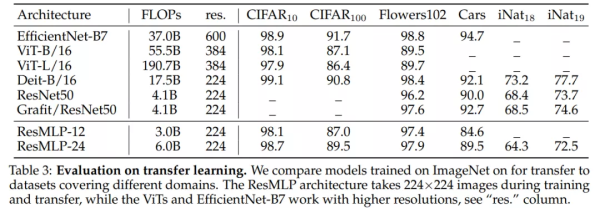
此外,实验还评估了 ReSMLP 在迁移学习方面的性能。下表 3 展示了不同网络架构在各种图像基准上的性能表现,这些数据集包括 CIFAR-10、CIFAR-100、FloweRs-1022、StanfoRd CaRs 和 iNatuRalist。
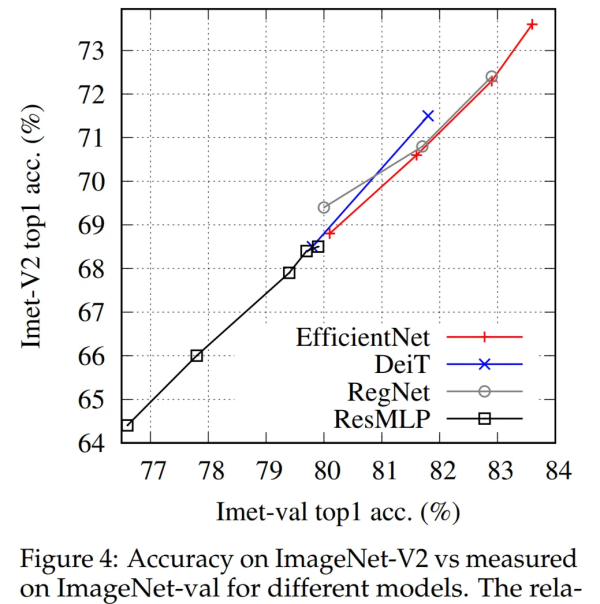
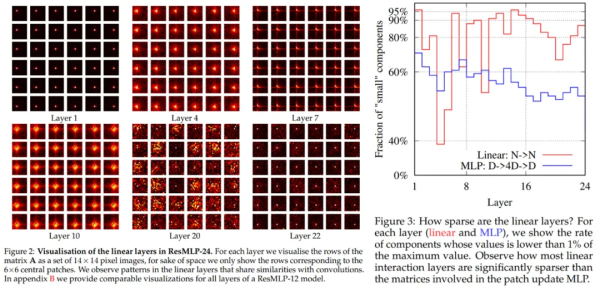
权重稀疏性测量也是研究者关注的一个方面。下图 2 的 ReSMLP-24 线性层的可视化结果显示线性通信层是稀疏的,并在下图 3 中进行了更详细的定量分析。结果表明,所有三个矩阵均呈现稀疏特性,实现 patch 通信的层明显更稀疏。
最后,研究者探讨了 MLP 的过拟合控制,在下图 4 的控制实验中探索了泛化问题。