背景
近年来,大规模语言模型在自然语言处理领域展现出显著优势。随着模型参数量的增长,系统面临的显存、计算与通信挑战也随之增加,推动了对高效分布式训练方法的需求。
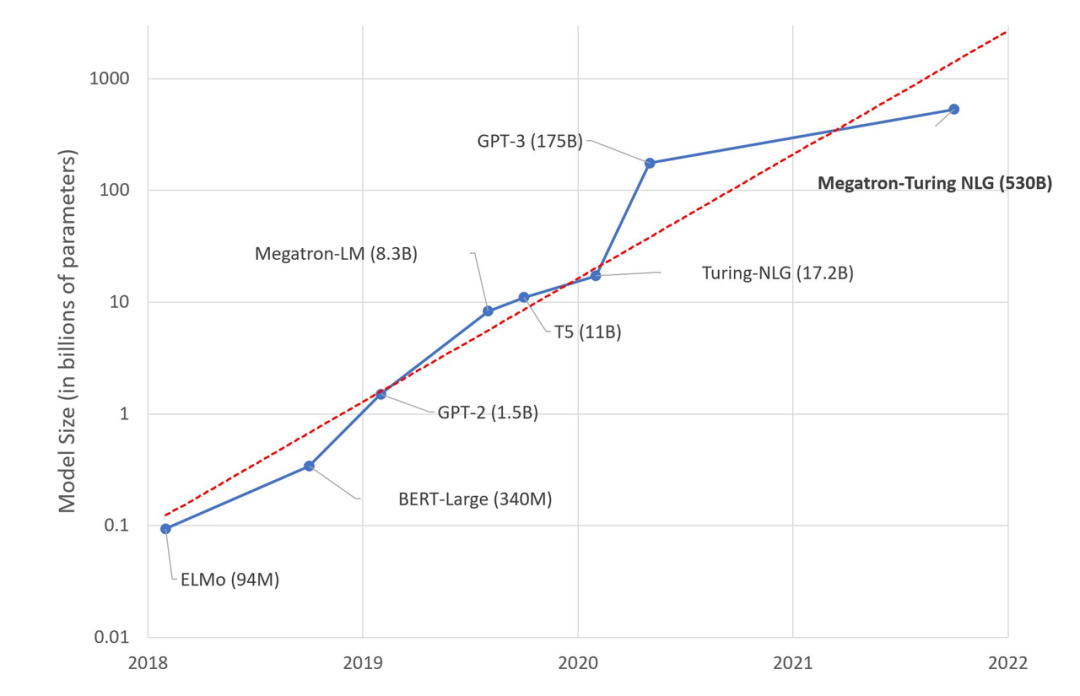
语言模型规模呈指数级增长,相关技术与工具也在持续演进,提升训练效率成为关注重点。
veGiantModel:面向大模型训练的高性能框架
为应对上述需求,内部团队在现有框架基础上开发了 veGiantModel。该框架基于主流深度学习框架,集成了多种分布式训练策略,并在通信库方面进行了优化,提升了训练吞吐与扩展性。其要点包括:
- 同时支持数据并行、算子切分、流水线并行等多种分布式策略,并能够自动化或定制化地应用并行方案;
- 基于高性能异步通信库,训练吞吐相比部分实现拥有显著提升;
- 提供友好且灵活的流水线支持,降低模型开发与迭代所需的人力成本;
- 在 GPU 上可高效支持从数十亿到上千亿参数规模的大模型,对带宽要求相对友好,私有化部署对 RDMA 的依赖较低。
其中,通信库为自研升级版,针对不同硬件拓扑进行分层规约优化,并支持更丰富的通信原语,提升总体并行效率。
veGiantModel 性能对比与测试配置
为展示性能,团队在自有机房进行测试,覆盖高端 GPU 型号的多机部署,实验配置概要如下:
V100 组测:每台机器 8 张 GPU,网络带宽达到较高水平;A100 组测:每台机器 8 张 GPU,网络带宽进一步提升。
在评估中,选择了一个现代级别的自回归语言模型进行对比,序列长度设定为 256,全局训练批量为 1536。对比基准来自在开源社区广受关注的两种主流实现。
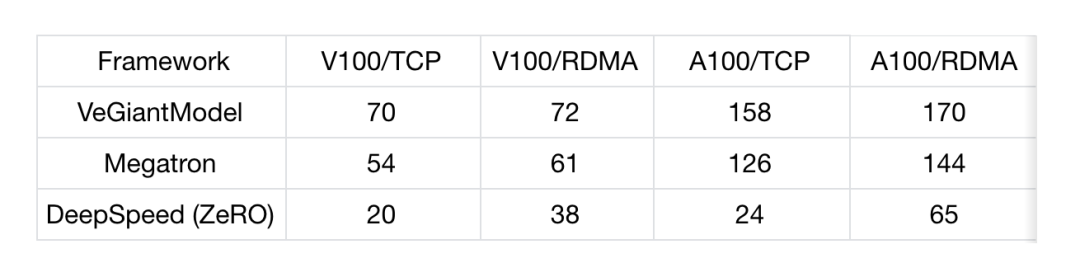
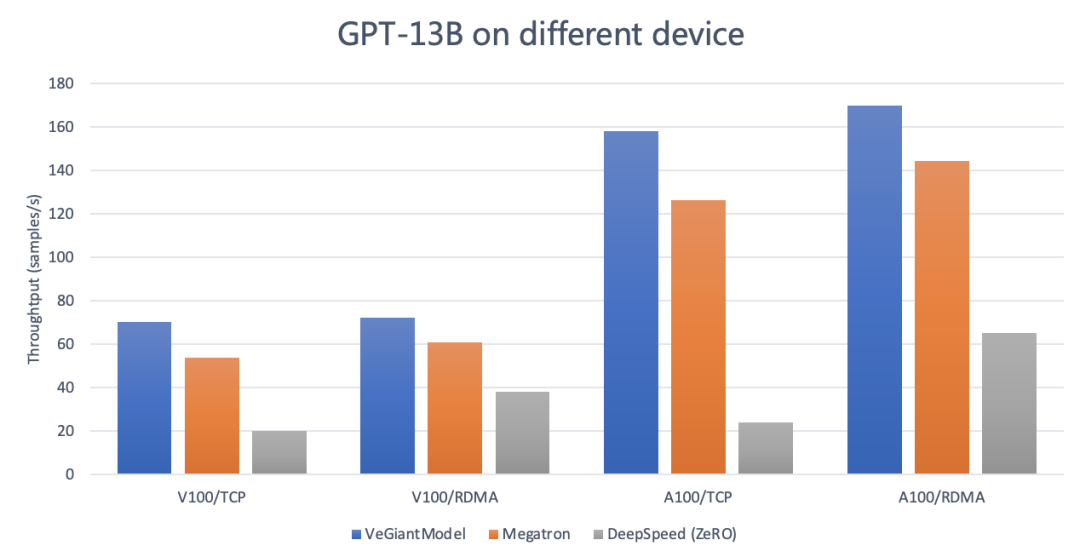
从结果来看,veGiantModel 在不同带宽条件下均显示出优越性能,尤其在高低带宽环境下均高于对照实现,提升幅度最高可达到约 6.9 倍。同时,在带宽波动对吞吐的影响方面,veGiantModel 表现更为稳健,保持的吞吐下降较小;而对比实现对带宽的依赖较大,带宽波动可能带来显著影响。
性能提升的原因
核心原因包括:
- 高性能异步通信库的优化,以及对分布式并行策略的定制能力,能够在跨机传输中更好地利用带宽并自动调整拓扑放置;
- 综合考量数据并行、算子切分、流水线并行三种策略下的传输与计算开销,达到更低的通信瓶颈;
- 对网络拓扑和资源分配的智能优化,使得在不同硬件与带宽条件下都能实现更高的吞吐。
veGiantModel 已在开源平台上提供相关实现与使用指南,方便快速搭建并训练一个 GPT 类的预训练模型。当前平台对该框架原生支持,公开版本正在持续完善与公测阶段,欢迎关注与试用。
注:文中涉及的测试环境、模型选择与对比对象均为内部评估设计,以帮助理解性能提升点为主。
