多智能体强化学习的运行机制解析
多智能体强化学习的运行机制解析
本文将对多智能体强化学习(Multi-agent Reinforcement Learning, MARL)的基本理论进行简要介绍,包括问题的定义、模型建立以及相关核心思想和概念。近年来,随着强化学习在多个领域的应用取得了显著成果,研究者们开始关注在现实场景中,多个智能体(agents)如何同时进行有效的决策。
随着强化学习技术的进步,尤其是在多个应用领域中取得的显著成效,研究者们逐渐将目光从单一智能体扩展到多智能体系统。本文将重点讨论多智能体强化学习的研究进展和关键问题。
近年来,强化学习(Reinforcement Learning)在不同应用领域的成功引发了人们对多智能体系统的极大关注。本文将首先介绍多智能体强化学习的相关理论,包括问题的定义、模型构建,以及涉及的核心思想和概念。接下来,基于具体应用场景,将多智能体问题分为完全合作、完全竞争和混合关系三种类型,并简要阐述如何利用经典算法解决这些问题。
本文将首先简要介绍多智能体强化学习的相关理论,包括问题的定义、模型建构,以及涉及的核心思想和概念。随着强化学习在多个应用领域取得的显著成果,研究者们逐渐将眼光从单一智能体扩展到多智能体系统。
在多智能体强化学习中,待解决的问题通常被描述为马尔可夫决策过程(Markov Decision Process, MDP)。在这一过程中,智能体通过与环境的交互来学习如何做出最佳决策,以最大化其累积奖励。每个智能体的状态、动作和奖励都受其他智能体行为的影响,这使得多智能体的决策过程变得复杂,需考虑到其他智能体的策略和行为。

图 1:强化学习的框架(同时也显示了马尔科夫决策过程)。图源:[1]
在多个智能体与环境交互的过程中,整个系统变成一个多智能体系统(Multi-agent system)。每个智能体仍然遵循强化学习的基本目标,即最大化其能够获得的累积回报。在此过程中,环境的全局状态变化与所有智能体的联合动作相关。因此,多智能体强化学习策略的学习过程需要考虑联合动作的影响。
接下来将讨论多智能体强化学习的相关理论,包括问题的定义、模型构建以及涉及的核心思想和概念。针对不同的多智能体问题,本文将其分为完全合作式、完全竞争式和混合关系式三种类型,并简要阐述如何利用经典算法解决这些问题。最后,本文将列举深度强化学习在多智能体研究工作中提出的一些方法(Multi-agent deep reinforcement learning)。
在强化学习和多智能体强化学习中,核心思想是“试错”(Trial-and-Error):智能体通过与环境的交互,根据获得的反馈信息不断迭代优化。在强化学习领域,经典的马尔可夫决策过程(MDP)通常用于描述待解决的问题。

图 2:马尔可夫博弈过程。图源:[2]
马尔可夫决策过程(MDP)拓展到多智能体系统,被定义为马尔可夫博弈(又称随机博弈)。当我们对博弈论有一定了解后,可以借助博弈论来分析多智能体强化学习的问题。
在多智能体强化学习的研究中,均衡求解方法是一个基础且重要的方向。对于多智能体强化学习的问题,研究者们逐渐将注意力从单一智能体的学习方法扩展到多智能体的学习策略。通过对多智能体的协作和竞争行为的深入分析,可以更好地理解智能体之间的相互影响。

对于马尔可夫博弈,纳什均衡是一个重要的概念,它是在多个智能体中达成的一个不动点,对于任意一个智能体而言,若其策略不变,将无法通过改变自身策略获得更好的累积回报。这样的均衡状态在多智能体系统中具有重要的理论意义。
在多智能体强化学习中,纳什均衡的实现并不一定是全局最优的,但它是在概率上最容易产生的结果,是在学习过程中较容易达到的状态。尤其是在当前智能体对其他智能体的策略缺乏认知时,达到纳什均衡显得尤为重要。

在该式中,π^表示智能体 i 的纳什均衡策略。需要注意的是,纳什均衡并不总是全局最优,但它是最易达成的状态,尤其是在学习过程中,如果智能体对其他智能体的行为没有准确的预期时。
在多智能体强化学习中,显式的协作机制是指智能体之间需要通过相互协商,以达成更优的联合行动。在这样的协作机制中,各智能体通过分享信息和策略来共同优化整体的决策过程。
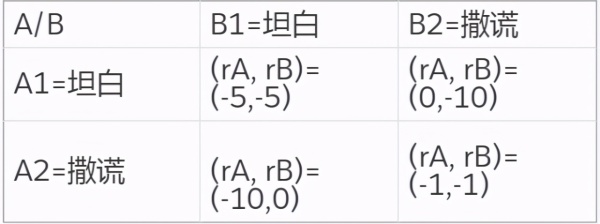
在多智能体系统中,对协作机制的研究主要集中于如何有效地管理和协调多个智能体之间的行为,确保它们在协作时能够实现最优的联合回报。在实际应用中,这种协作机制可以通过分布式学习和集体决策的方式来实现。
针对不同应用场景,本文将探讨多智能体强化学习的具体应用案例,包括实时战略游戏、物流配送等。在这些场景中,智能体需要在复杂的环境中进行决策,这就要求其具备良好的协作能力和较强的适应性。

在强化学习领域,特别是在多智能体系统的研究中,随着深度学习技术的发展,智能体的学习能力得到了显著提升。深度强化学习(Deep Reinforcement Learning)在处理复杂问题时展现了极大的潜力,尤其是在多智能体系统中,它为实现高效的协作和竞争提供了新的思路。
未来,多智能体强化学习的研究方向将围绕着如何提升智能体在协作和竞争环境中的表现展开,解决多智能体系统中的各种挑战,包括理论框架的完善、算法的优化、模型的安全性等。
综上所述,多智能体强化学习是结合了强化学习和多智能体系统的一项重要研究方向,关注多个智能体的序贯决策问题。本文对多智能体强化学习的理论、算法及其在不同场景中的应用进行了探讨,未来的研究将继续推动这一领域的发展。