全行业都在测语音AI的“接话准不准”,但从没人问过:它真的听懂了吗?
我们先来关注一个数据。
超过40%。
这是某一主流全模态大模型在进行语音交互时“正确”的比例。这意味着每进行100次操作,其中超过4次是错误的。
它并不是因为理解了才作出回答,而是恰好没有出错。
这个数据来源于百融团队开源的TT Benc。我们对Gemini 3-Pro、GPT-4o-audio、Qwen3-Omini和mini CP-Mo-4.5这些热门模型进行了测试。
结果令人失望。
一个价值千万的缺陷,隐藏在“正确”之中。
在你查看数据之前,我先给你讲个真实的场景。
一个智能语音助手正在向客户推介理财产品,客户突然咳嗽了一声。
AI瞬间停住,静默两秒,等待客户说话。
看似很贴心,对吗?似乎很“智能”?
但事实上,它根本不知道那是一声咳嗽。
它只是感知到“有声音”,然后本能地保持沉默。如果客户是跟同事说话,它也会停下;如果是窗外的喇叭声,它也会停下。如果客户想打断并说“我不感兴趣”,它的反应与咳嗽时完全一样。
这四种情况各自需要不同的处理方式,但在这个AI的“思维”中,它们都是“有动静,闭嘴”。
从表面看,它每次都“做对了”,但从内部来看,它一次都没有“听懂”。
这并非个别现象,而是语音AI行业的普遍盲点。
整个行业都在用错误的标准进行评估。
这个问题为何存在已久却无人察觉?
因为我们使用的评估方法有误。
目前,行业内评估语音交互能力的主流方法是端点检测——判断用户是否说完。说完了就接话,没说完就等。
这是个简单的二分类问题,粗暴而且严重失真。
近几年出现了一些升级版的评估工具,如FLEXI测社交场景、Full-Duplex-Bench-v2评估多轮任务及MTR-DuplexBench考察性能衰退。这些工具确实比二分类有所进步。
但它们有一个致命的缺陷:只关注“做了什么”,而不探究“为什么这么做”。
它们能看到“模型沉默了”,却无法判断:这次沉默是因为正确判断了用户在思考?还是把咳嗽当成了发言?还是把背景噪音当成了用户指令?
这三种沉默在现有评估中得分相同,但在真实对话中,反应的智能程度却截然不同。
所有人都在用这份“错误的评估”打分,宣称自己的模型表现优异。
难怪没人发现问题,因为评估本身无法识别出问题。
这一问题的严重性如何?
你可能觉得:即使偶尔出错,用户也感知不到,结果不都是一样的吗?
并不一样,差别很大。
在百融云创的多个业务场景中,智能助手每天处理大量实时通话。营销、回访、客服、贷后——每个电话都涉及真实的经济利益。
想象以下场景:
客户犹豫要不要购买。他停顿了几秒钟,一个“真正理解”的AI会静静等待,给他思考的空间;而一个“蒙”的AI可能错误判断为“用户说完了”,急于插话,打断客户的购买决定。
客户被旁边的同事叫了一声。他转头说了句“等一下”。一个“真正理解”的AI会立刻停下;而一个“蒙”的AI可能把这句话误解为指令,做出不合适的反应。
客户明确说了“你别说了”。一个“真正理解”的AI会立刻停下;而一个“蒙”的AI可能依然犹豫——因为它上次听到类似声音时,判断的是“背景噪音,忽略”。
每次错误判断都是转化率的损失、客户满意度的下降、合规风险的增加。
这在日均百万通话量的情况下影响巨大。
这不是小问题。这是一个被“正确分数”掩盖的巨大隐患。
我们揭开了这个真相。
我们创建了一个新的评估工具,名为codeTT——它不再测量“做了什么”,而是测量“为什么这么做”。
它不测“做了什么”,而是测“为什么这么做”。
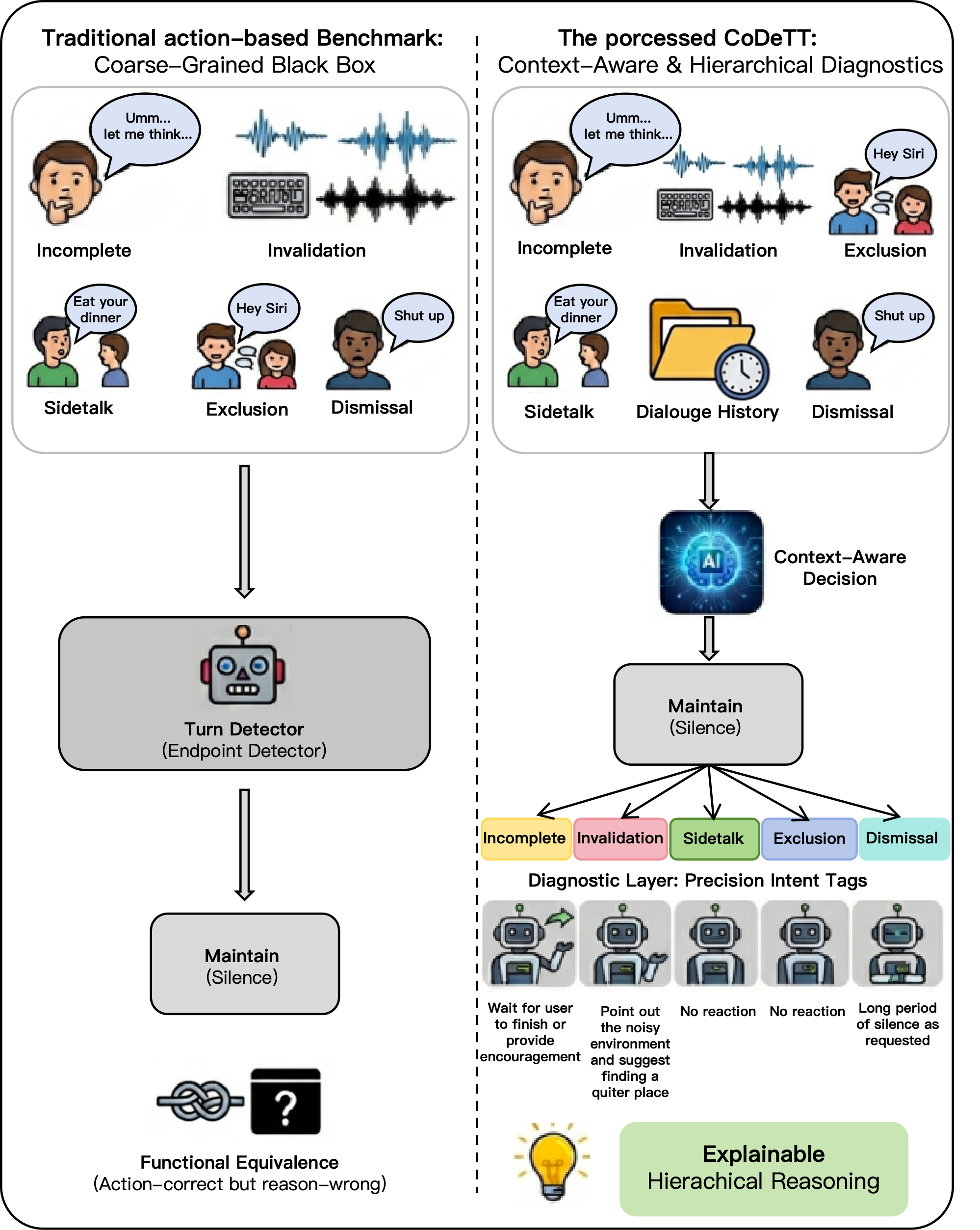
图示:传统评估(左)只关注表面,像是“黑箱阅卷”;codeTT(右)深入分析决策意图,实现分层诊断,展现评估理念的根本差异。
14个“陷阱”,层层递进。
codeTT建立了一个三层诊断体系,将转接过程从“判断对错”转变为“诊断原因”。
第一层:你现在在做什么?系统在发言(system Speaking)还是在等待用户发言(system Idle)。
第二层:你打算如何处理?四个宏观动作——继续说(Maintain)、停下来听(Stop & Listen)、接管发言(Take Over)、无视(Disregard)。
第三层:你凭什么这么做?这是关键。codeTT设计了14种细粒度意图场景,每一种都是精心设计的“陷阱”。
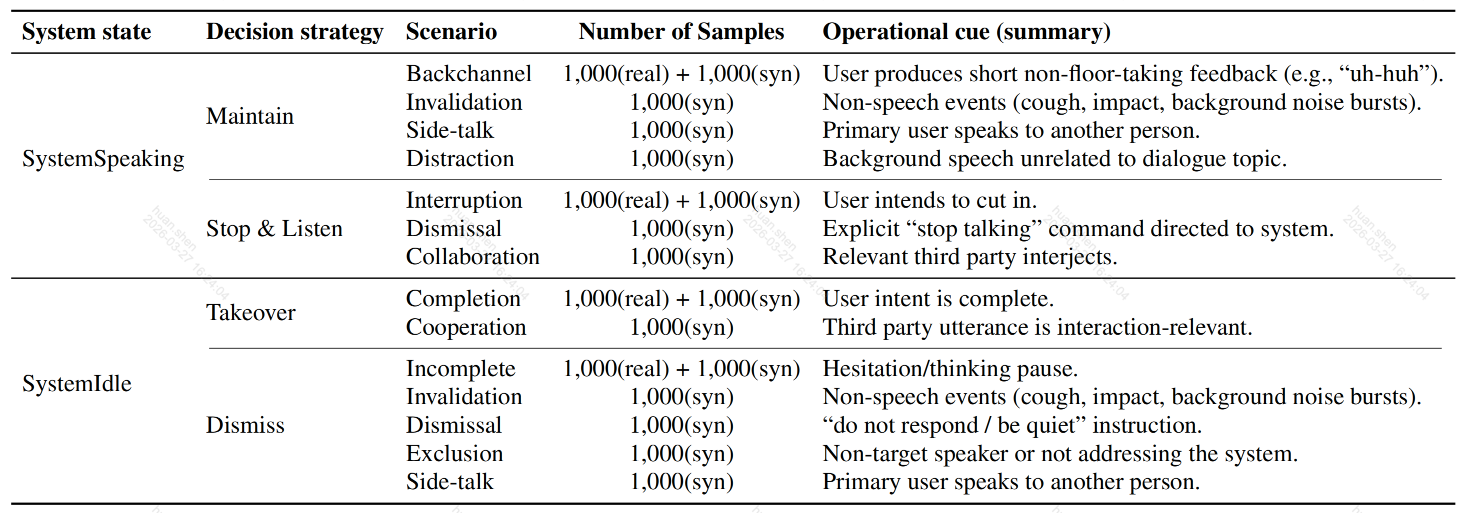
图示:codeTT定义的14种轮次交接决策场景完整分类体系—相当于将“轮次交接”这张试卷划分为14个大题,每道题考察不同的能力。
同样是“继续说不停下”,你的理由是什么?
用户只是“嗯嗯”两声表示在听?—对,继续。
旁边传来一声咳嗽?—对,继续,但理由完全不同。
用户在和别人说话?—对,继续,但这又是另一个理由。
背景里有人在聊天?—对,继续,但你必须知道原因。
四个看似相同的“正确答案”,却有四种截然不同的“正确理由”。传统评估只关注表面,codeTT关注内在。
数据集:300小时,毫不含糊。
codeTT并不是一个简单的测试集。
300小时的中英双语多轮对话,包含18,000个标注决策实例,14个诊断场景均匀覆盖,每个实例带有5轮完整对话历史。
数据构建经历了六个阶段:Gemini 3-Pro生成对话文本、GPT-5进行语义质检、Qwen3-TTS合成多个人声、Qwen3-AS进行转录验证、专项声学复杂场景模拟、真实自然对话语料融合。两名双语标注员人工审核,标注一致性Cohen’s kappa = 0.87。
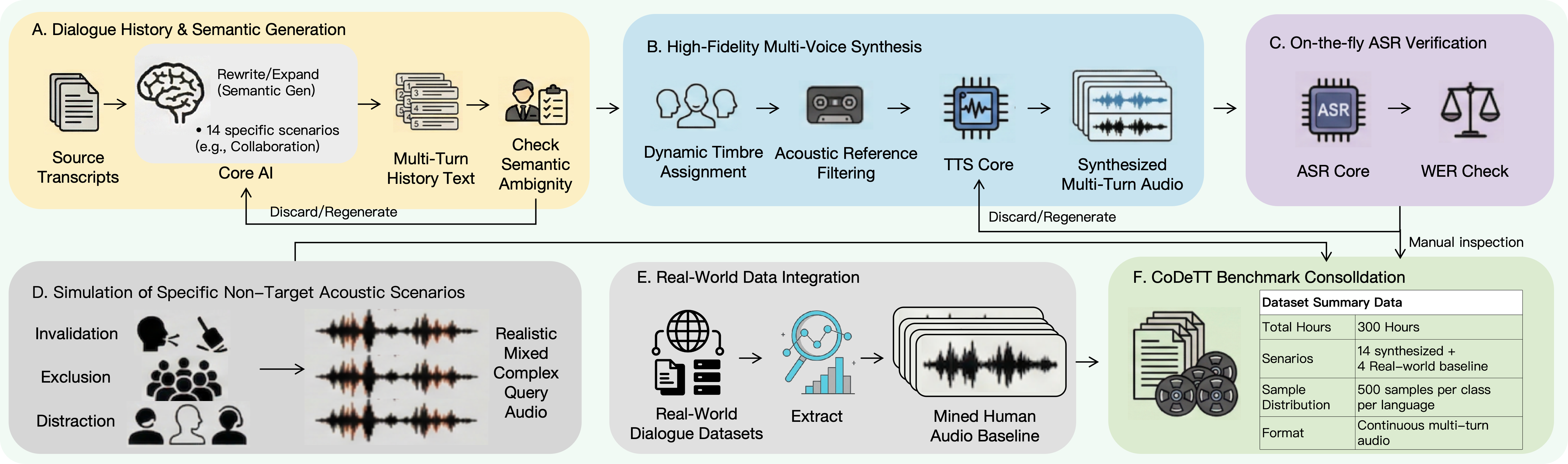
图示:codeTT数据六阶段构建流水线全景图,从文本生成到声学模拟,再到真实数据融合,展示了数据工程的完整性和严谨性。
这不是随便拼凑的,而是以造武器的态度构建的评估工具。
一个指标,揭露“蒙题”的遮羞布。
codeTT还引入了一个全新的指标——语义错位率(Semantic Misalignment Rate,SMR)。
这个指标的作用是:识别那些“动作正确但理由错误”的案例。
公式简单:在所有“动作正确”的样本中,有多少是“意图判断错误”的?
SMR越高,说明模型越像一个蒙题的学生——选择题答对了,但问他原因时,他却说“因为今天是周三”。
这个指标此前从未被提出过,因为以往的评估根本没有“问理由”的环节。
成绩出来了,请坐稳。
我们把当前最强的语音模型和全模态大模型都带到了考场。
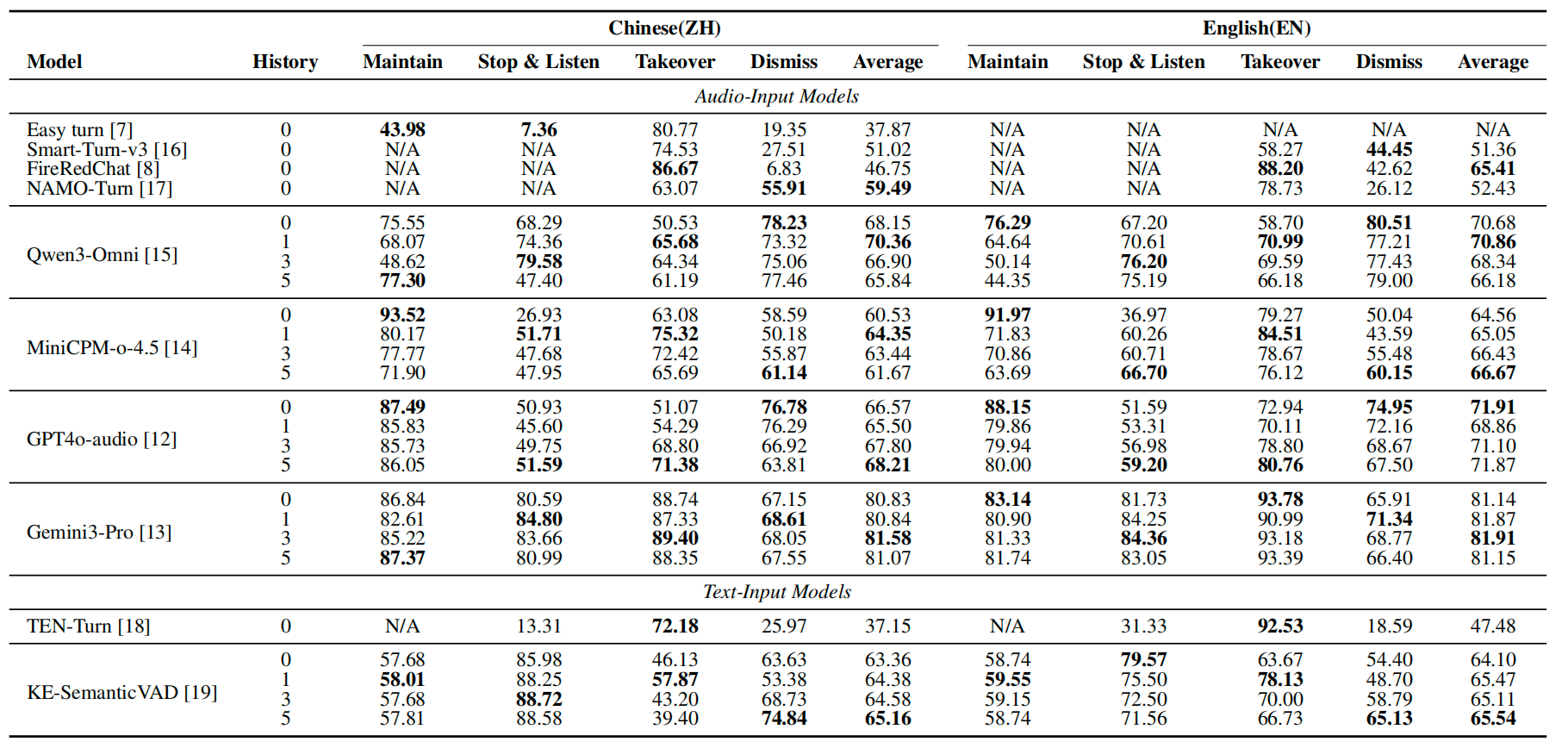
图示:主流模型在四类核心决策上的准确率对比(中英文),清晰展示各模型的“偏科”现象——许多模型在某一场景下表现尚可,其余场景则大幅下降。
专用控制器:“瘸腿冠军”
Easy Turn、FireRedChat、SMart-Turn-v3、NAMO-Turn——这些专注于端点检测的选手,在“接管话轮”上得分很高,FireRedChat中文达到86.67%。
但一旦到了“该不该忽略”,成绩就崩盘了。FireRedChat仅有6.83%。
这意味着什么?在100次该忽略的情况下,它判断对了不到7次,剩下93次则做出了不该的反应。
这些模型把“判断用户是否说完”练到了极致,但面对现实世界的复杂性—背景噪音、旁人说话、用户犹豫—它们基本无能为力。
全模态大模型:“优等生”的成绩单充满水分。
从动作级别来看,Gemini 3-Pro的表现最为出色,中英文平均准确率超过81%。看起来确实是个优等生。
但通过SMR的“X光”映射——
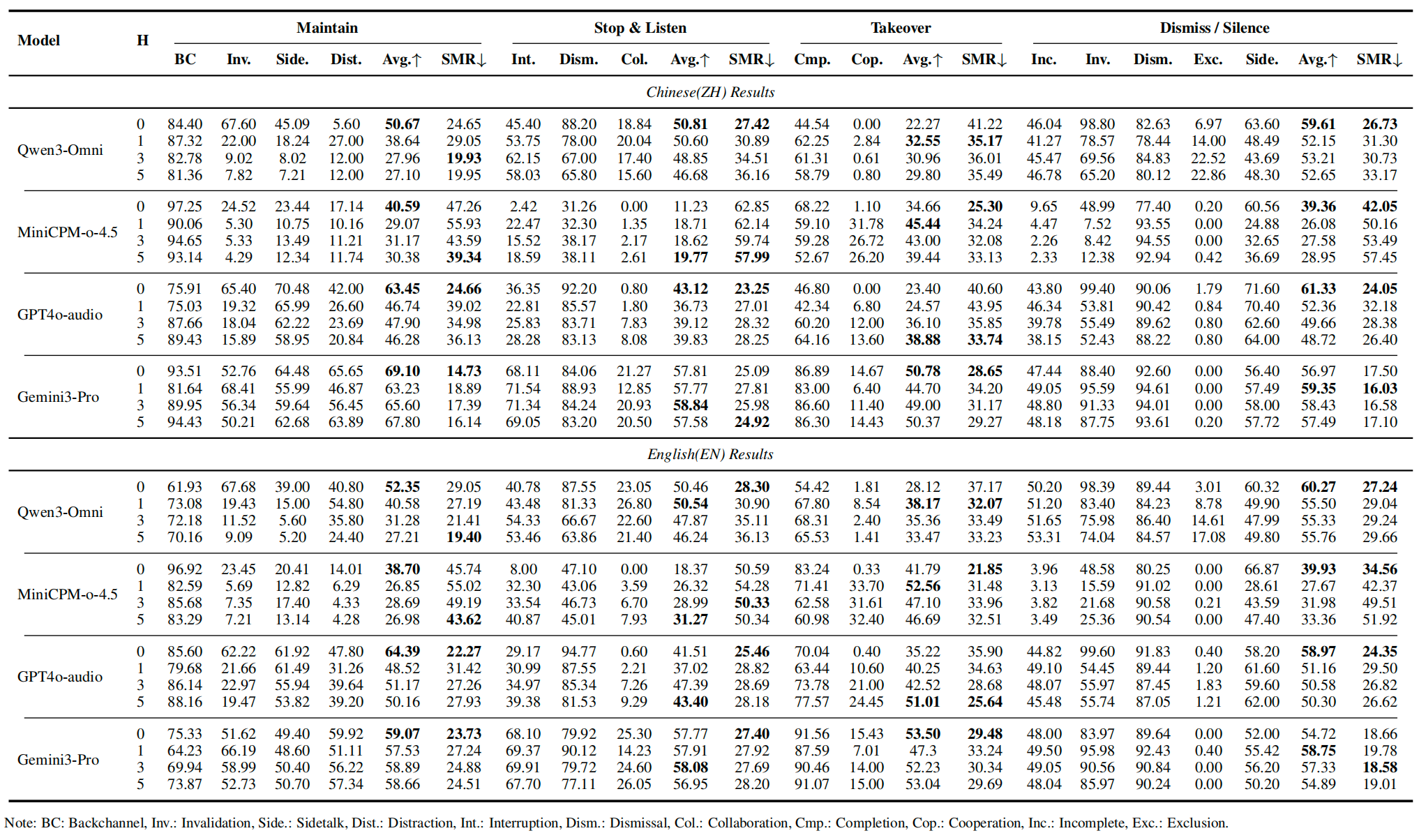
图示:14种细粒度意图场景下各模型的准确率与SMR对比,清晰展示“动作对但理由错”的普遍性。
mini CP-Mo-4.5:在AIntn场景下SMR高达55.93%(中文,1轮历史)。
这意味着什么?它在“正确保持说话”的案例中,超过一半是偶然正确的。它不清楚用户是在“嗯嗯”还是在咳嗽,或者是在和旁边的人说话,反正都是选择“继续说”——偶然对了。
GPT-4o-audio在动作级别表现尚可,但在协作场景下准确率不足8%。几乎无法识别“另一个相关的人加入了对话”这种情况。
Qwen3-Omini增加到5轮上下文时,旁人对话识别率从45%骤降至7%。上下文越多,反而越糊涂。
即使是表现最佳的Gemini3-Pro,SMR也在15%到25%之间。也就是说,它每5次“正确操作”中,至少有1次是偶然做对的。
没有任何模型的SMR低于15%。没有一个。
上下文越多就越好?错得离谱。
我们分别在0轮、1轮、3轮、5轮对话历史下进行测试,发现了一个反直觉的结论:
适度的上下文(1~3轮)确实有帮助。比如帮助模型区分“用户在思考”和“环境噪声”。
但增加到5轮时,反而变差了。尤其在“打断”场景下,性能下降,SMR升高。
图示:GPT-4o-audio的语义混淆矩阵,直观展示模型在哪些场景中产生了意图混淆。
模型确实停下来了,但它停下来的不是因为听到打断,而是因为它的“历史惯性”告诉它该停。
这就像一个老司机在红灯路口停下——不是因为看到了红灯,而是因为他每次在这个路口都会停。虽然看似相同,但本质上,一个是安全驾驶,一个是定时炸弹。
codeTT揭示的三层真相。
所有实验数据指向同一个结论:当前语音AI的转接能力被严重高估。
codeTT揭示了三层能力阶梯,现实非常残酷:
第一层:边界检测——说完了吗?专用控制器能做到,大多数系统停留在此。
第二层:上下文推理——为何这样?全模态大模型有所触及,但远未过关。SMR无情地证明了这一点。
第三层:多方语音消歧——谁在说、说给谁、意图是什么?所有模型在这里集体失利。协作和排除场景的糟糕数据就是明证。
传统评估只测第一层,然后宣称胜利;codeTT告诉你,真正的挑战才刚刚开始。
这对行业意味着什么?
对语音AI从业者:codeTT是首个能够告诉你“模型为何出错”的诊断工具。不再是“准确率低,但不知道原因”,而是能精确定位问题:是后续识别弱?还是多人场景处理不当?还是上下文使用过多反而导致过拟合?需要修正的地方一目了然。