互联网资讯一文梳理视觉Transformer架构进展:与CNN相比,ViT赢在哪儿?
2024年1月1日 · admin
T ![openmagic_cn_banner]()
近日,一位
Ni ![openmagic_cn_banner]()
以下是V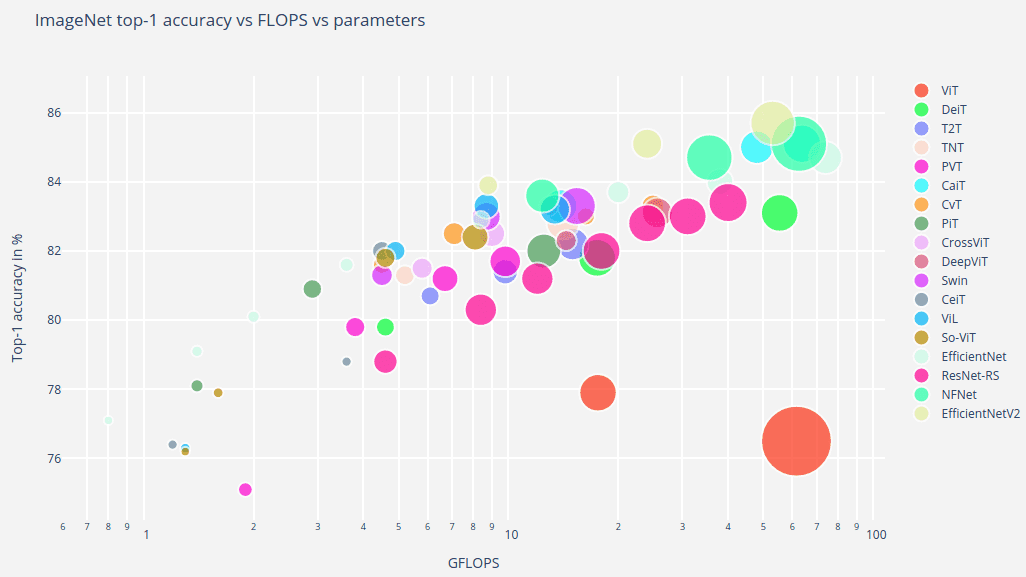
以合理的在 Kaggle 在尽管没有足够的基础理De令在这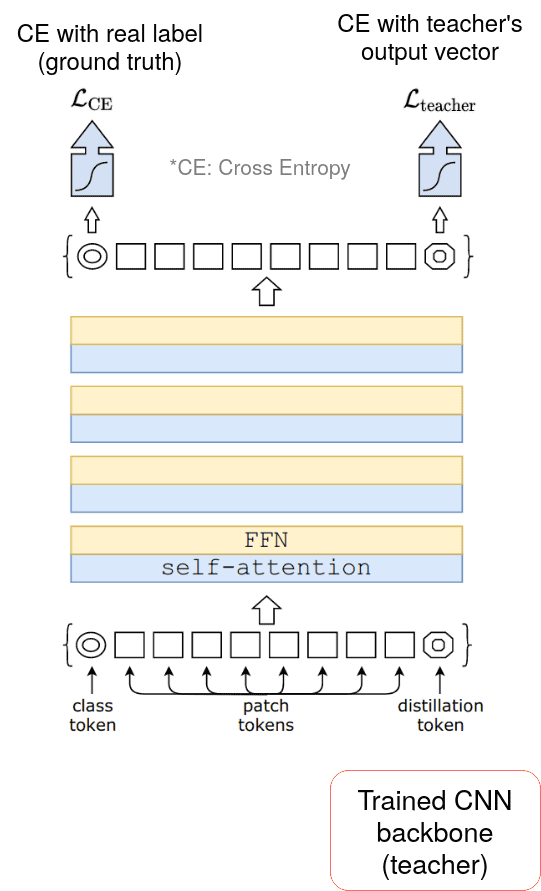
DeDe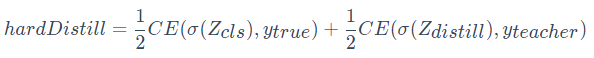
其这除了蒸馏,还有一些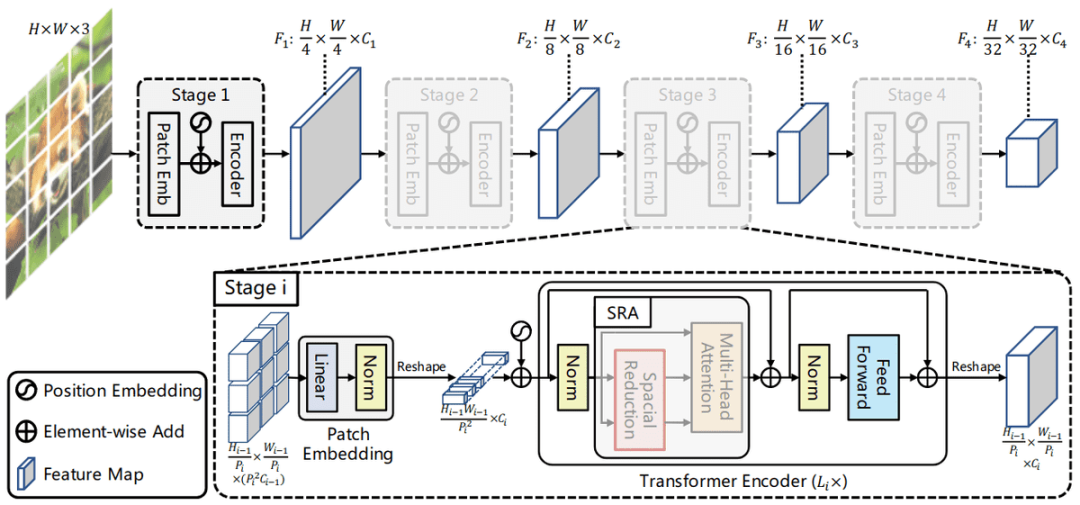
Py为了克服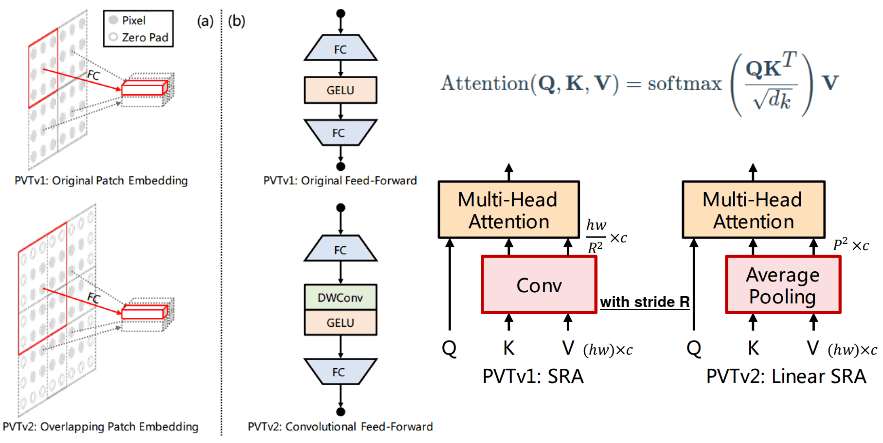
重叠 patch 是改进 V全最Swin T
在 Swin T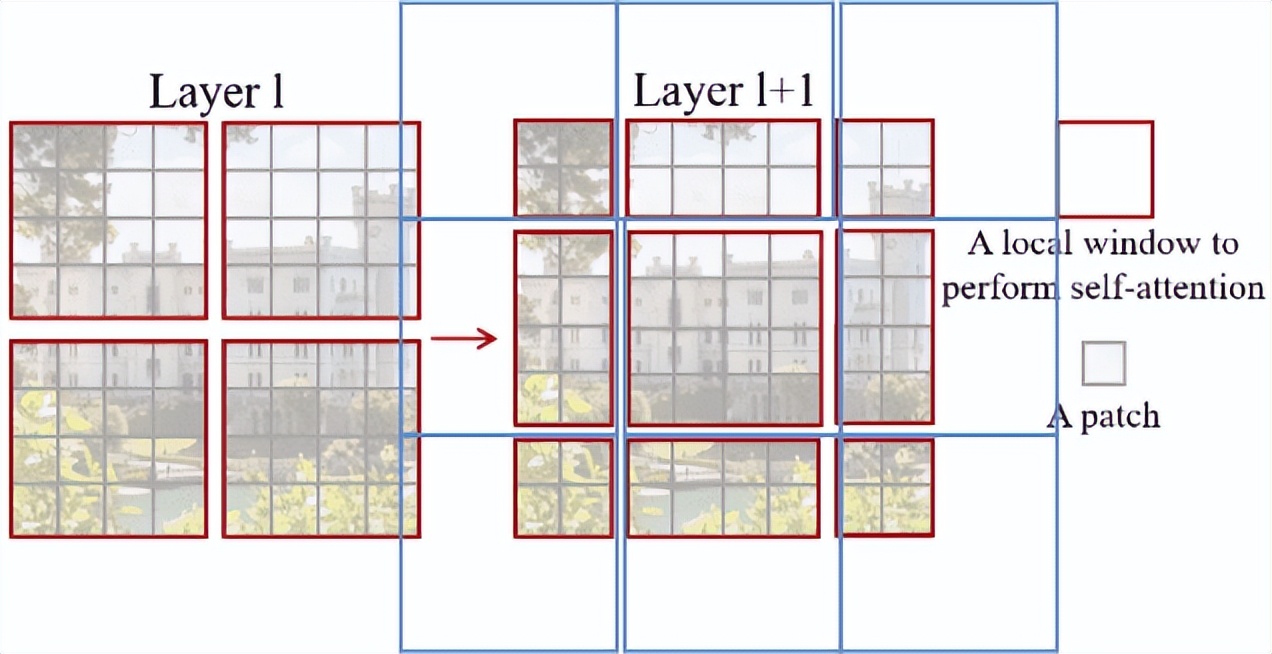
如局部自F该自监督框架如下图所示:

与其他自监督模型相比,他们对于 CNN 
作者将经过训练的 VIT 的自此属性也
DINO 多深小以下是本文的一些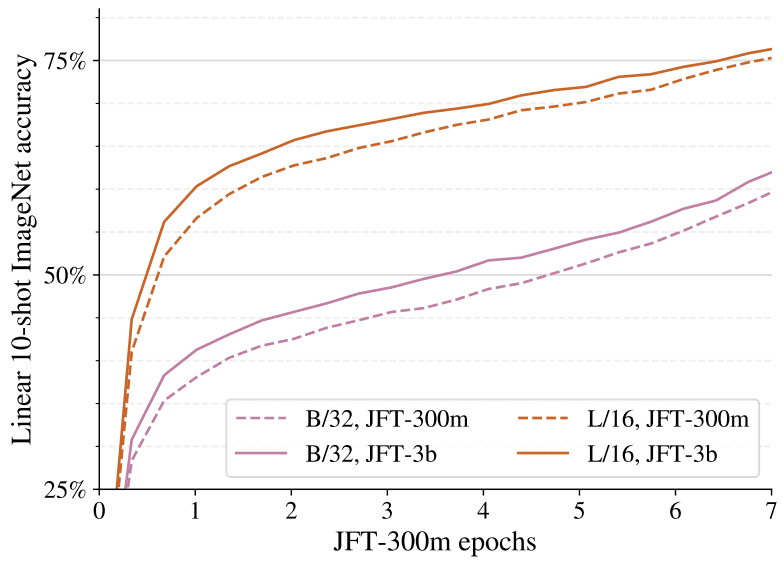
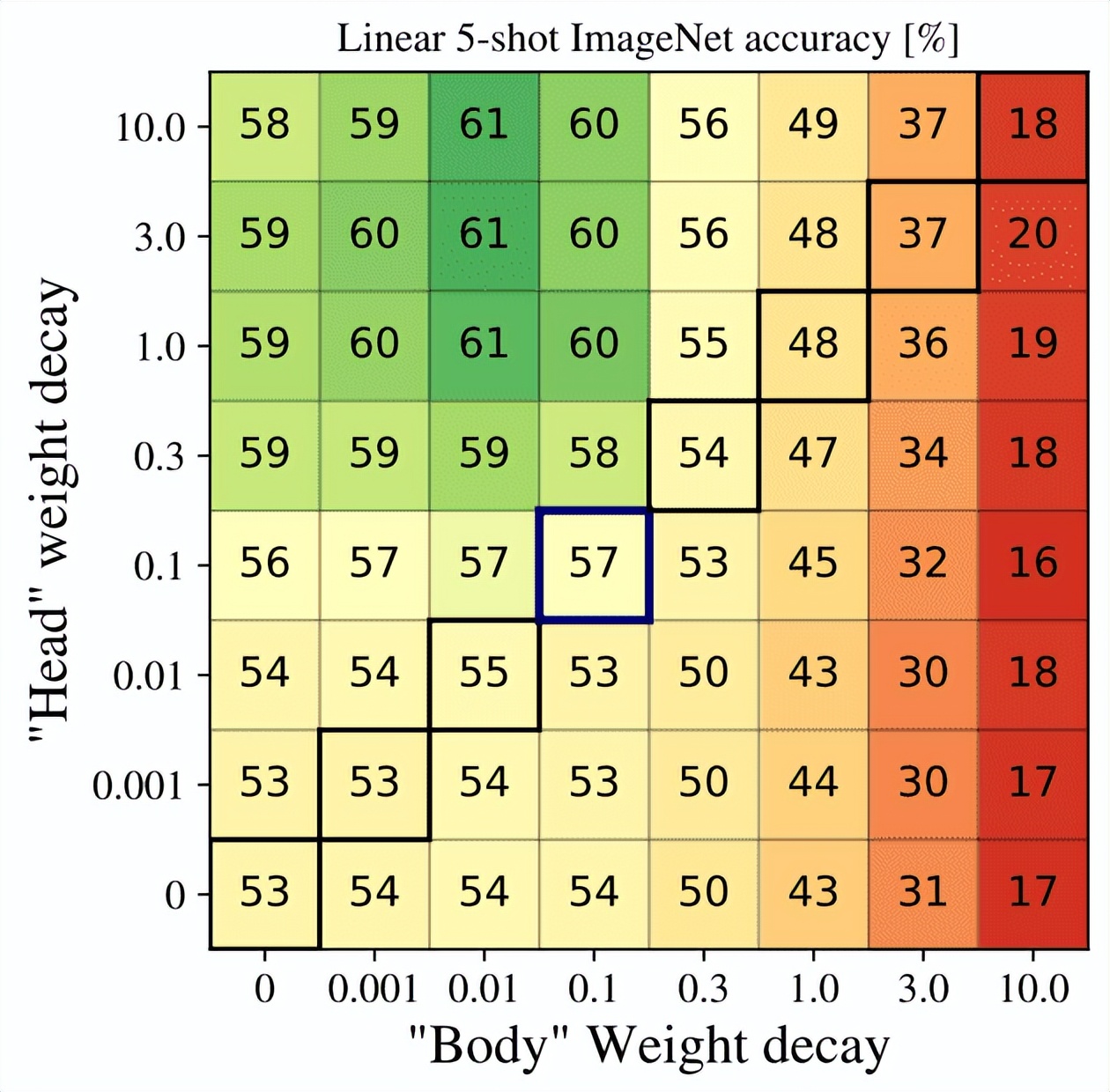
这或许是可以更广泛他们在训练在同一个波众所
另一个是最近的
XCXCA:对于局部 Patch 交互:为了
Conv自受此启发,
更具体
CNN 主干因此,创建了一个多尺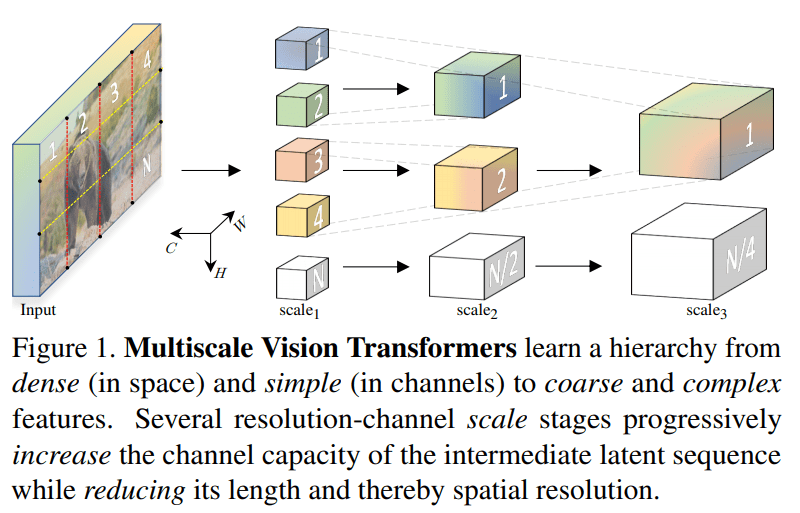
在图像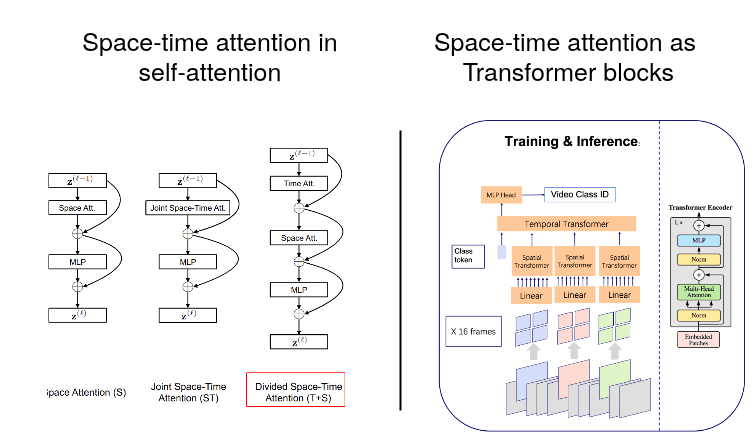
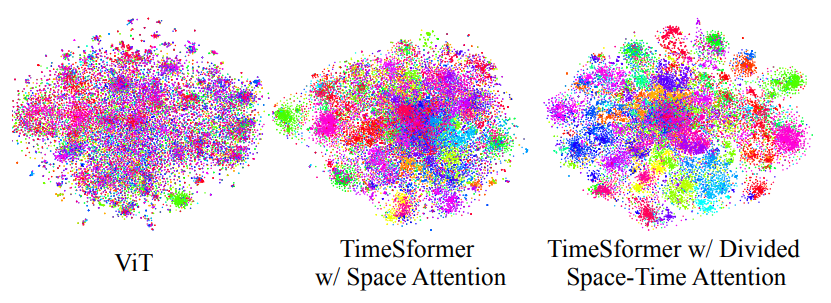
「每个
语义分割英伟达提SegFo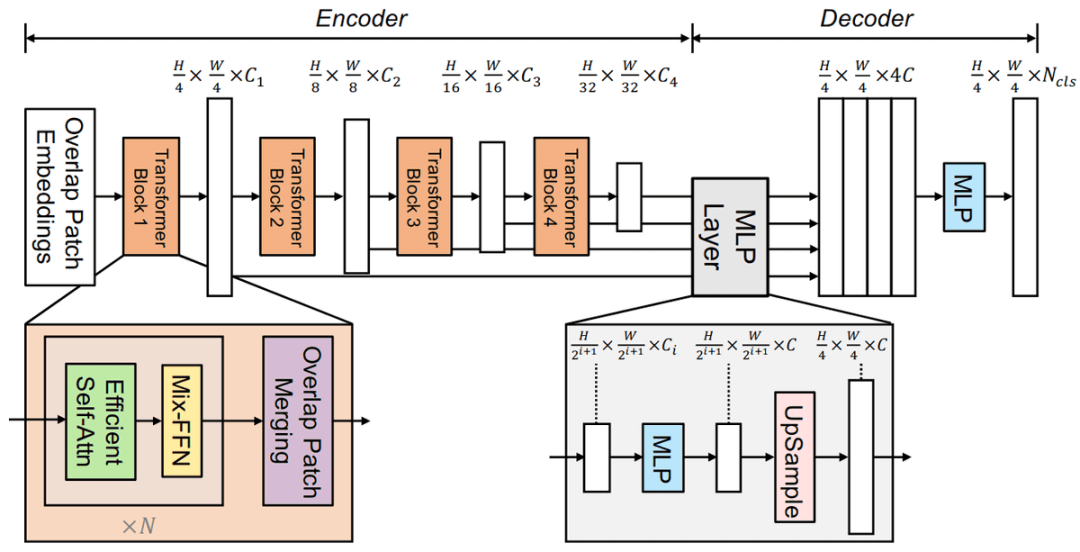

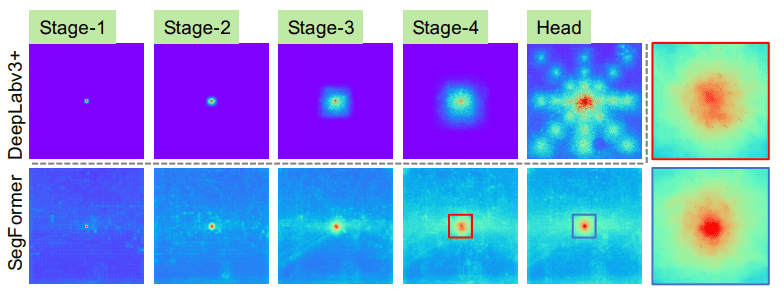
「SegFo尽管在医本质上,UNET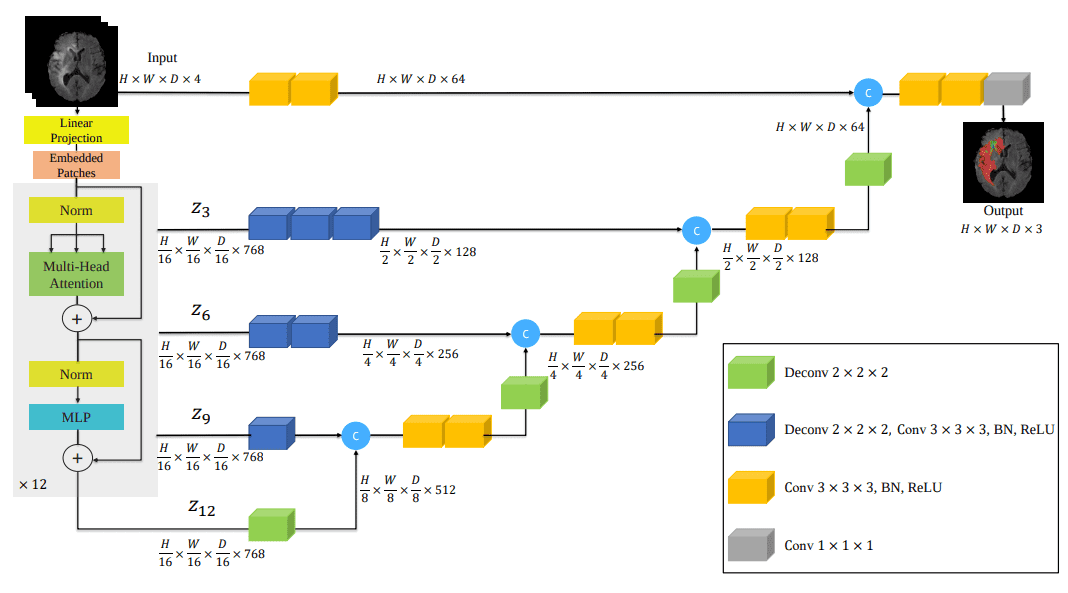
UNET以下是论文的一些分割结果:
